问题1、数组和指针的区别
数组名不可以作为左值
char * p1 = "Hello World" ; //分配字符串常量,然后赋给 p1 ,一个指针型变量,是左值 char p2[ 20] = "Hello World" ; //分配一个数组,然后初始化为字符串,相当于一个常量,类型为数组,不是左值 *p1 = 'h' ; //p1可以指向别的地方,但hello world不能更改 p2[ 0] = 'h' ; //p2不能指向别的地方,但hello world可以更改
sizeof运算
sizeof(指针变量p1)是编译器分配给指针(也就是一个地址)的内存空间。
sizeof(数组指针常量p2)是整个数组占用空间的大小。但当数组作为函数参数进行传递时,数组就自动退化为同类型的指针。
取地址&运算
对数组名取地址&运算,得到的还是数组第一个元素的地址
对指针取地址&运算,得到的是指针所在的地址,也就是指向这个指针的指针。因此main函数的参数char *argv[],也可以写成char **argv。
参考
问题2、指针数组、数组指针与二维数组剖析
定义
指针数组:首先它是一个数组,数组的元素都是指针,数组占多少个字节由数组本身决定。它是“储存指针的数组”的简称。
数组指针:首先它是一个指针,它指向一个数组。在32 位系统下永远是占4 个字节,至于它指向的数组占多少字节,不知道。它是“指向数组的指针”的简称。
实例区分
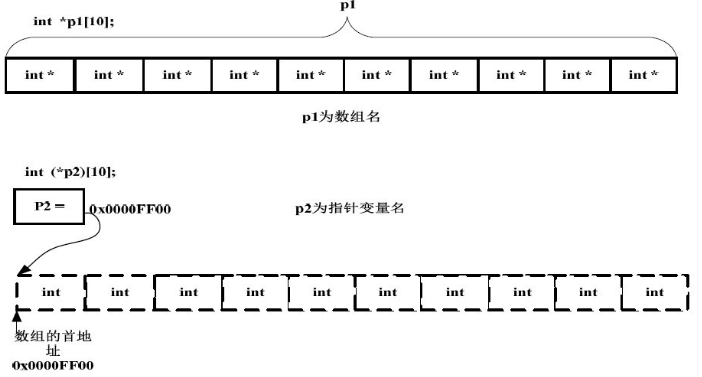
int *p1[10]; //p1 是数组名,其包含10 个指向int 类型数据的指针,即指针数组 int (*p2)[10]; //p2 是一个指针,它指向一个包含10 个int 类型数据的数组,即数组指针 cout<<sizeof(a)<<" "<<sizeof(b); //4 40
实例分析
符号优先级: ()> [ ] > *
p1 先与“[]”结合,构成一个数组的定义,数组名为p1,int *修饰的是数组的内容,即数组的每个元素。
“*”号和p2 构成一个指针的定义,指针变量名为p2,int 修饰的是数组的内容,即数组的每个元素。数组在这里并没有名字,是个匿名数组。
数组和指针参数是如何被编译器修改的?
“数组名被改写成一个指针参数”规则并不是递归定义的。数组的数组会被改写成“数组的指针”,而不是“指针的指针”:
实参 所匹配的形参 数组的数组 char c[8][10]; char (*)[10]; 数组指针 指针数组 char *c[10]; char **c; 指针的指针 数组指针(行指针) char (*c)[10]; char (*c)[10]; 不改变 指针的指针 char **c; char **c; 不改变
void f(char **c){ cout<<c[1][2]<<endl; } int main(){ char *c[3]={"abc","def","ghi"}; f(c); }
*c[3] 表示这是一个一维数组,数组内的元素是char *类型,每个元素分别指向一个字符串。因为 [] 优先级大于 * 的优先级。
问题3、结构体和数组
数组中存放的是连续的元素,比如int、char等。同样,可以存放struct元素。
实例
struct UnionFieldInfo { int flag; //字段选中标识: 0 未选中 1 选中 char *field; // 选中字段 char *fieldDetail; //选中字段在数据库中具体表示 }; struct UnionFieldInfo HACAlarmAudioInfo[] = { {0, "time", "events.time"}, {0, "matchRule", "events.content"}, {0, "level", "events.rule_level"}, {0, "userName", "session.username"}, {-1, NULL, NULL}, }; /* int flag*/ int UnionGetAlarmFieldInit() { int i = 0; for (i = 0; i < sizeof(HACAlarmAudioInfo)/sizeof(HACAlarmAudioInfo[0]); i++) { HACAlarmAudioInfo[i].flag = 0; //init } return 0; } /* get field */ static char * UnionGetAlarmField(char *Field) { int i = 0; for (i = 0; i < sizeof(HACAlarmAudioInfo)/sizeof(HACAlarmAudioInfo[0]); i++) { if(HACAlarmAudioInfo[i].flag == 1) { return HACAlarmAudioInfo[i].field; } } return NULL; } /* make fielddetail sql */ int UnionMakeAlarmFieldSQL(char *sql) { int i = 0; for (i = 0; i < sizeof(HACAlarmAudioInfo)/sizeof(HACAlarmAudioInfo[0]); i++) { if(HACAlarmAudioInfo[i].flag == 1) { sprintf(sql+strlen(sql), "%s, ", HACAlarmAudioInfo[i].fieldDetail); } } /*cancel ", "*/ if(strlen(sql) >= strlen(", ")) { tinysql[strlen(sql)-strlen(", ")] = 0; } }
一维数组HACAlarmAudioInfo中存放的是struct UnionFieldInfo元素。
问题4、带逗号的字符串分隔
使用strtok进行分隔带有逗号的字符串
if (strlen(stApplyInfo.userGroupID)) { char *tmpstr = NULL; char s[2] = ","; tmpstr = strtok(stApplyInfo.userGroupID, s); //返回被分解的第一个子字符串,如果没有可检索的字符串,则返回一个空指针。 while(tmpstr) { memset(sql, 0, 2048); UnionDBPrintf(sql, 2048, "insert into workOrder_userGroup(workOrder, userGroupID) values('%s','%d')", worknote, atoi(tmpstr)); UnionLogDebugEx("draw.log","sql=[%s]",sql); UnionErr = UnionDBInsert(sql, &row, &errmsg); if (UnionErr) { UnionLogErrEx("draw.log", "db insert failed:[%s]", errmsg); free(sql); return UnionErr; } tmpstr = strtok(NULL, s); } }
问题5、字符串拷贝函数
最好使用memcpy()、snprintf()函数进行字符串拷贝。而strcpy()、strncpy()不太好。
strcpy()容易溢出,只用于字符串的拷贝。
strcpy(p+1, p); //内存重叠
char * strcpy(char * dest, const char * src) // 实现src到dest的复制 { if ((src == NULL) || (dest == NULL)) //判断参数src和dest的有效性 { return NULL; } char *strdest = dest; //保存目标字符串的首地址 while ((*strDest++ = *strSrc++)!='�'); //把src字符串的内容复制到dest下 return strdest; }
strncpy()标准用法
strncpy(path, src, sizeof(path) - 1); path[sizeof(path) - 1] = '/0'; len = strlen(path);
memcpy将N个字节的源内存地址的内容拷贝到目标内存地址中。
对于需要复制的内容没有限制,复制任意内容,例如字符数组、整型、结构体、类等。
当源内存和目标内存存在重叠时,memcpy会出现错误。
memcpy(p+1, p, 512); //内存重叠
void* memcpy(void* dest, const void* src, size_t n) { assert((NULL != dest) && (NULL != src)); char* d = (char*) dest; const char* s = (const char*) src; while(n-–) *d++ = *s++; return dest; }
内存重叠
函数strcpy和函数memcpy都没有对内存重叠做处理的,使用这两个函数的时候只有程序员自己保证源地址和目标地址不重叠,或者使用memmove函数进行内存拷贝。
memmove函数对内存重叠做了处理。内存重叠时,使用strcpy函数则程序会崩溃。使用memcpy的话程序会等到错误的结果。
memmove将N个字节的源内存地址的内容拷贝到目标内存地址中
当源内存和目标内存存在重叠时,能正确地实施拷贝,但这也增加了一点点开销。
void* memmove(void* dest, const void* src, size_t n) { assert((NULL != dest) && (NULL != src)); char* d = (char*) dest; const char* s = (const char*) src; if (s>d) { // start at beginning of s while (n--) *d++ = *s++; } else if (s<d) { // start at end of s d = d+n-1; s = s+n-1; while (n--) *d-- = *s--; } return dest; //do nothing }
(1)内存低端 <-----s-----> <-----d-----> 内存高端 start at end of s (2)内存低端 <-----s--<==>--d-----> 内存高端 start at end of s (3)内存低端 <-----sd-----> 内存高端 do nothing (4)内存低端 <-----d--<==>--s-----> 内存高端 start at beginning of s (5)内存低端 <-----d-----> <-----s-----> 内存高端 start at beginning of s
(1)当源内存的首地址等于目标内存的首地址时,不进行任何拷贝
(2)当源内存的首地址大于目标内存的首地址时,实行正向拷贝
(3)当源内存的首地址小于目标内存的首地址时,实行反向拷贝
问题6、字符串查找函数
strstr() 函数
char *strstr(const char *haystack, const char *needle) 参数说明: haystack -- 要被检索的 C 字符串。 needle -- 在 haystack 字符串内要搜索的小字符串。 返回值: 该函数返回在 haystack 中第一次出现 needle 字符串的位置,如果未找到则返回 null。 实例: ret = strstr("RUNOOB", "NOOB"); printf("子字符串是: %s ", ret); //"NOOB"
代码实现
#include <cstring> #include <iostream> #include <cassert> using namespace std; char* my_strstr(char* str, char* sub) { assert(str != NULL); assert(sub != NULL); int str_len = strlen(str); int sub_len = strlen(sub); if (str_len < sub_len) /*不用比较,肯定不是*/ { return NULL; } if (str_len != 0 && sub_len == 0) /*aaaaaaaaaaaaaaaaaa, "" ,比较需要花费时间很多*/ { cout << "子串为空。。。" << endl; return NULL; } if (str_len == 0 && sub_len == 0) /*都为空可以直接返回*/ { cout << "原串和子串都为空 !" << endl; return str; } for (int i = 0; i != strlen(str); ++i) { int m = 0, n = i; cout << "原串剩余的长度 : " << strlen(str + i) << endl; cout << "子串的长度 : " << sub_len << endl; if (strlen(str + i) < sub_len) /*往后找如果原串长度不够了,则肯定不是*/ { cout << "子串太长啦。。。" << endl; return NULL; } if (str[n] == sub[m]) { while (str[n++] == sub[m++]) { if (sub[m] == '�') { return str + i; } } } } return NULL; }
问题7、const用法
const与指针
const放在*左边表示指针指向的是一个常量,放在*后面表示这是一个常量指针。
int a=5, b=10; const int* p = &a; //p指向的是一个常量,即p的内容为常量 int const* p = &a; //p指向的是一个常量,即p的内容为常量 p = &b; //可以改变p的指向 //*p = 20; //错误:但是不能改变a的内容 int* const p1 = &a; //p1是一个常量指针,表明指针p1是常量不能进行修改,但是p指的内容是可以修改的 *p1 = 30; //p指的内容是可以修改的 //p1=&b; //错误:指针p的指向不能修改
const修饰函数参数
const修改函数参数表示参数不可修改,可起到保护的作用。按值传递的参数加上const是没意义的,因为参数传递的时候是拷贝的。按引用传递时加上const保证传出参数的同时对象也不会被更改。
void foo(const int a) { // a=10; //错误,函数参数不可改变 }
const修改成员函数
const修改成员表示该函数不能修改任何成员变量的值,同时不能调用任何非const修饰的函数,因为没有const修饰的函数会修改成员变量的值。const修饰函数放在最后面。
#include<iostream> using namespace std; const int a()//返回值为const { return 3; } class A { public: int temp; int fun (int x)const//类中成员函数的函数体由const修饰时,不能改变成员变量的值 { //temp=5;//修改了temp的值,出错 return 0; } }; int main() { //int v=a();//a()只能作为右值,可以赋给int v和const int v const int v=a(); cout<<v; A a; a.fun(5); return 0; }
const修饰返回值
一、常量可以赋给常量和变量。
二、指向常量的指针必须必须赋给指向常量的指针,指向变量的指针可以赋给指向变量或常量的指针。
const char* foo() { const char a = 'c'; const char* p = &a; return p; } char* const foo2() { char a = 'c'; char* const p = &a; return p; } const char* const foo3() { const char a = 'c'; const char* const p = &a; return p; } int main() { //char* p = foo(); //error,指向常量的指针不能赋给指向变量的指针 const char* p = foo(); //指向常量的指针 const char* const p4 = foo(); //把变量指针赋给常量指针,合法 char* p2 = foo2(); //把常量指针赋给变量指针,合法 char* const p3 = foo2(); //常量指针 const char* p5 = foo2(); //指向变量的指针可以赋给指向常量的指针 const char* const p6 = foo3(); //指向常量的常量指针 const char* p7 = foo3(); //指向常量的变量指针 //char* const p8 = foo3(); //指向变量的常量指针,error //char* p9 = foo3(); //指向变量的变量指针,error cin.get(); return 0; }
问题8、代理中的echo调试记录
各种代理(ssh等)调试日志,很难获取。可以使用echo命令,通过以下简单几行代码进行调试。
int ret = 0; char log_cmd[1024] = {0}, buff[1024] = {0}; snprintf(buff, 1024, "%s", "test log by system()"); snprintf(log_cmd, 1024, "echo '%s' >> /tmp/log.txt", buff); ret = system(log_cmd);
问题9、非root帐户下密钥认证脚本生成中的用户主目录获取
Linux 命令行下可通过 echo $HOME进行获取。
//获取当前用户主目录 char *UnionGetRealHomeDir() { char *path = getenv("HOME"); return path; }