一、使用DOM解析XML文档
DOM的全称是Document Object Model,也即文档对象模型。在应用程序中,基于DOM的XML分析器将一个XML文档转换成一个对象模型的集合(通常称DOM树),应用程序正是通过对这个对象模型的操作,来实现对XML文档数据的操作。通过DOM接口,应用程序可以在任何时候访问XML文档中的任何一部分数据,因此,这种利用DOM接口的机制也被称作随机访问机制。
DOM接口提供了一种通过分层对象模型来访问XML文档信息的方式,这些分层对象模型依据XML的文档结构形成了一棵节点树。无论XML文档中所描述的是什么类型的信息,即便是制表数据、项目列表或一个文档,利用DOM所生成的模型都是节点树的形式。也就是说,DOM强制使用树模型来访问XML文档中的信息。由于XML本质上就是一种分层结构,所以这种描述方法是相当有效的。
DOM树所提供的随机访问方式给应用程序的开发带来了很大的灵活性,它可以任意地控制整个XML文档中的内容。然而,由于DOM分析器把整个XML文档转化成DOM树放在了内存中,因此,当文档比较大或者结构比较复杂时,对内存的需求就比较高。而且,对于结构复杂的树的遍历也是一项耗时的操作。所以,DOM分析器对机器性能的要求比较高,实现效率不十分理想。不过,由于DOM分析器所采用的树结构的思想与XML文档的结构相吻合,同时鉴于随机访问所带来的方便,因此,DOM分析器还是有很广泛的使用价值的。
- 优点:
- 形成了树结构,有助于更好的理解、掌握,且代码容易编写。
- 解析过程中,树结构保存在内存中,方便修改。
- 缺点:
- 由于文件是一次性读取,所以对内存的耗费比较大。
- 如果XML文件比较大,容易影响解析性能且可能会造成内存溢出。
Oracle公司提供了JAXP来解析XML,JAXP会把XML文档转换为一个DOM树。JAXP包含3个包:
- org.w3c.dom W3C推荐的用于使用DOM解析XML文档的接口;
- org.xml.sax 用于使用SAX解析XML文档的接口;
- javax.xml.parsers 解析器工厂工具,程序员获得并配置特殊的分析器;
DOM解析所使用到的类都在这些包中,使用DOM解析XML文档前序导入这些包。
示例:
<book id=”1234”> <title>三国演义</title> <author>罗贯中</author> <price>30元</price> </book>
其中所有带尖括号的叫元素节点,只有文本文字的叫属性节点,id=”1234”叫做属性节点。
转换成DOM树:
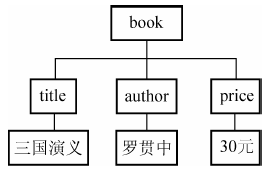
更易于增删改查的应用。
1. 常用接口介绍:
| 常用方法 | 说明 | |
| Document:表示整个 XML 文档 | NodeList getElementsByTagName(String Tag) | 返回一个NodeList对象,它包含了所有指定标签名称的标签 |
| Element getDocumentElement() | 返回一个代表这个DOM树的根节点的Element对象,也就是代表XML文档的根元素的对象 | |
| NodeList对象:包含一个或多个节点的列表 | getLength() | 返回列表的长度 |
| item(int index) | 返回指定位置的Node对象 | |
| Node对象:DOM中最基本的对象,代表了文档树中的一个抽象节点。 | getChildNodes() | 此节点的所有子节点的NodeList |
| getFirstChild() | 如果节点存在子节点,则返回第一个子节点 | |
| getLastChild() | 如果节点存在子节点,则返回最后个子节点 | |
| getNextSibling() | 返回DOM树中这个节点的下一个兄弟节点 | |
| getPreviousSibling() | 返回DOM树中这个节点的上一个兄弟节点 | |
| getNodeName() | 返回节点的名称 | |
| getNodeValue() | 返回节点的值 | |
| getNodeType() | 返回节点的类型 | |
| Element对象: 代表XML文档中的标签元素,继承自Node,也是Node最主要的子对象 | getAttribute(String attributename) | 返回标签中指定属性名称的属性的值 |
| getElementByTagNmae(String name) | 返回具有指定标记名称的所有后代Elements的NodeList |
2. 使用DOM解析XML文档步骤
1)创建解析器工厂对象 DocumentBuildFactory对象
2)由解析器工厂对象创建解析器对象,即DocumentBuilder对象
3)由解析器对象对指定XML文件进行解析,构建相应的DOM树,创建Document对象,生成一个Document对象
4)以Document对象为起点对DOM树的节点进行查询
5)使用Document的getElementsByTagName方法获取元素名称,生成一个NodeList集合,
6)遍历集合
3. DOM解析XML文档实例
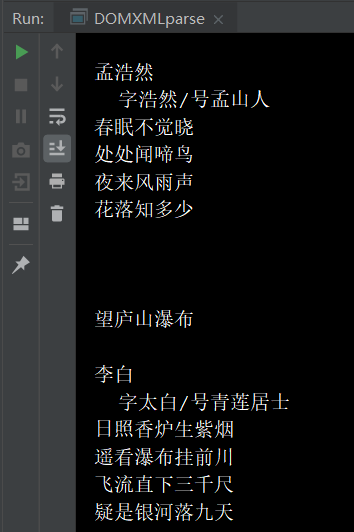
Poems.xml:
<?xml version="1.0" encoding="utf-8"?> <poems createYear="2019"> <poem> <title>春晓</title> <author authorInfo="字浩然/号孟山人">孟浩然</author> <content>春眠不觉晓,处处闻啼鸟。夜来风雨声,花落知多少。</content> </poem> <poem> <title>望庐山瀑布</title> <author authorInfo="字太白/号青莲居士">李白</author> <content>日照香炉生紫烟,遥看瀑布挂前川。飞流直下三千尺,疑是银河落九天。</content> </poem> </poems>
DOMXMLparse .java:
package cn.XmlFile; import java.io.*; import java.util.regex.Matcher; import java.util.regex.Pattern; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import com.sun.org.apache.bcel.internal.generic.NEW; import org.w3c.dom.*; import org.xml.sax.SAXException; /** * @author yu * */ public class DOMXMLparse { /** * * 通过输入流打印原XML文档 */ public static void ReadXmlByIO(File file) { FileReader fileReader = null; BufferedReader bufferedReader = null; try{ fileReader = new FileReader(file); bufferedReader = new BufferedReader(fileReader); String line = null; while ((line = bufferedReader.readLine())!=null){ System.out.println(line); } }catch (FileNotFoundException f){ f.printStackTrace(); }catch (IOException i){ i.printStackTrace(); } } /* * 写一个读取树的函数: 1:获得第一层子节点 2:获得子节点的属性 3:完成第一、二步后读取下一层回掉函数重复执行第一、二步后 */ public static void ReadTreeStructure(NodeList nodes) { // 遍历所有子节点 for (int i = 0; i < nodes.getLength(); i++) { // 获得字节点名,判断子节点的类型,区分出text类型的node以及element类型的node if (nodes.item(i).getNodeType() == Node.ELEMENT_NODE) { //System.out.println("该节点的名称为:" + nodes.item(i).getNodeName() + " "); String value = ((Text)(nodes.item(i).getFirstChild())).getData().trim(); if (value.getBytes().length != 0) { //如果有逗号和句号,换行 String reg = "[\,\,\。]"; Pattern pattern = Pattern.compile(reg); Matcher matcher = pattern.matcher(value); System.out.println(matcher.replaceAll(" ")); } //元素属性值 String attrValue = ((Element)(nodes.item(i))).getAttribute("authorInfo"); if(attrValue!=null||attrValue!=""){ System.out.println(" "+attrValue); } } // 获得子节点的值,如果没有就不输出;如果子节点还有子节点就继续往下层读 if (nodes.item(i).getChildNodes().getLength() != 0) { ReadTreeStructure(nodes.item(i).getChildNodes()); } } } public static void main(String[] args) { // 用DocumentBuilderFactory的newInstance()从xml获得生成DOM对象树的解析器 DocumentBuilderFactory docbf = DocumentBuilderFactory.newInstance(); try { // 顾名思义DocumentBuilder是Doucument的生成器,可以利用解析器的newDocumentBuilder()获得示例 DocumentBuilder docb = docbf.newDocumentBuilder(); // 用DocumentBuilder的parse()解析xml文件获得Doucment对象下面就可以利用它获得xml文件的内容了 Document doc = docb.parse("D:\MyPractice01\sources\Poems.xml"); //打印源XML文件 //File XMLFile = new File("D:\MyPractice01\sources\Poems.xml"); //DOMXMLparse.ReadXmlByIO(XMLFile); // 获得当前节点的所有子节点 NodeList nodes = doc.getChildNodes(); ReadTreeStructure(nodes); // 下面决定写个方法一层一层剥开xml文件,由于xml是树的结构所以要用到读取树的方法 } catch (ParserConfigurationException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (SAXException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } }
注意:
- 函数里面,筛选了xml的节点类型,因为xml的节点除了标签外,还存在text类型的节点,它一般只用来存放文字,没有NodeName。所以不用获取。
- 这里的获得text类型的value是直接获得当前的子节点的value,但是element类型的node是没有value的,只有text类型的node才有,和用if (value.getBytes().length != null)有区别。
- 下图蓝色区域也是一个text类型的节点。放文字的也是text类型的节点,所以算外面element类型的node的子节点。
![]()
4. 使用DOM对XML文档进行增删改查操作
- 增加
(1) 创建
-
- document.createElement(tagName); /*元素节点*/
- document.createTextNode(data); /*文本节点*/
- document.createAttribute(name); /*属性节点*/
- cloneNode(deep)
(2) 加入
-
- document.write(markup) /*一般不用,文档加载完毕后使用会覆盖页面!*/
- appendChild(aChild) /*追加到结尾处*/
- innerHTML
- innerText
- insertBefore(newElement, referenceElement) /*用法----父元素.insertBefore(新元素, 旧元素)*/
(3),其它
-
- style. 的操作
- setAttribute(name, value)
- 删除
- removeChild(child) /*修改元素*/
- removeAttributeNode(attributeNode)
- 修改
(1) 修改节点
-
- replaceChild(newChild, oldChild) /* 删除节点再加入*/
用法:父元素.replaceChild(新元素, 旧元素)
(2) 修改样式
-
- style.xxx = sss ;
- setAttribute(name, value)
(3),修改文本
-
- innerHTML
- innerText
- nodeValue /*节点操作(删除旧文本节点再加入新文本节点)*/
(4),修改属性
-
- setAttribute(name, value) /*属性名 = 值 */
例子如下:
MyXml.xml:
<?xml version="1.0" encoding="UTF-8" standalone="no"?><father> <son id="001"> <name>老大</name> <age>28</age> </son> <son id="002"> <name>老二</name> <age>25</age> </son> <son id="003"> <name>老三</name> <age>13</age> </son> </father>
XMLOperation.java:
package cn.XmlFile; import java.io.File; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.transform.Transformer; import javax.xml.transform.TransformerFactory; import javax.xml.transform.dom.DOMSource; import javax.xml.transform.stream.StreamResult; import javax.xml.xpath.XPath; import javax.xml.xpath.XPathConstants; import javax.xml.xpath.XPathExpressionException; import javax.xml.xpath.XPathFactory; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; public class XMLOperation { private static String xmlPath = "D:\MyPractice01\sources\MyXml.xml"; public static void getFamilyMemebers() { /* * 创建文件工厂实例 */ DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); // 如果创建的解析器在解析XML文档时必须删除元素内容中的空格,则为true,否则为false dbf.setIgnoringElementContentWhitespace(true); try { /* * 创建文件对象 */ DocumentBuilder db = dbf.newDocumentBuilder();// 创建解析器,解析XML文档 Document doc = db.parse(xmlPath); // 使用dom解析xml文件 /* * 历遍列表,进行XML文件的数据提取 */ // 根据节点名称来获取所有相关的节点 NodeList sonlist = doc.getElementsByTagName("son"); for (int i = 0; i < sonlist.getLength(); i++) // 循环处理对象 { // 节点属性的处理 Element son = (Element) sonlist.item(i); // 循环节点son内的所有子节点 for (Node node = son.getFirstChild(); node != null; node = node .getNextSibling()) { // 判断是否为元素节点 if (node.getNodeType() == Node.ELEMENT_NODE) { String name = node.getNodeName(); String value = node.getFirstChild().getNodeValue(); System.out.println(name + " : " + value); } } } } catch (Exception e) { e.printStackTrace(); //System.out.println(e.getMessage()); } } // 修改 public static void modifySon() { // 创建文件工厂实例 DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); dbf.setIgnoringElementContentWhitespace(true); try { // 从XML文档中获取DOM文档实例 DocumentBuilder db = dbf.newDocumentBuilder(); // 获取Document对象 Document xmldoc = db.parse(xmlPath); // 获取根节点 Element root = xmldoc.getDocumentElement(); // 定位id为001的节点 Element per = (Element) selectSingleNode("/father/son[@id='001']", root); // 将age节点的内容更改为28 per.getElementsByTagName("age").item(0).setTextContent("28"); // 保存 TransformerFactory factory = TransformerFactory.newInstance(); Transformer former = factory.newTransformer(); former.transform(new DOMSource(xmldoc), new StreamResult(new File( xmlPath))); } catch (Exception e) { e.printStackTrace(); //System.out.println(e.getMessage()); } } // 获取目标节点,进行删除,最后保存 public static void discardSon() { DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); dbf.setIgnoringElementContentWhitespace(true); try { DocumentBuilder db = dbf.newDocumentBuilder(); Document xmldoc = db.parse(xmlPath); // 获取根节点 Element root = xmldoc.getDocumentElement(); // 定位根节点中的id=002的节点 Element son = (Element) selectSingleNode("/father/son[@id='002']", root); // 删除该节点 root.removeChild(son); // 保存 TransformerFactory factory = TransformerFactory.newInstance(); Transformer former = factory.newTransformer(); former.transform(new DOMSource(xmldoc), new StreamResult(new File( xmlPath))); } catch (Exception e) { e.printStackTrace(); //System.out.println(e.getMessage()); } } // 新增节点 public static void createSon() { // 创建文件工厂实例 DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); dbf.setIgnoringElementContentWhitespace(false); try { DocumentBuilder db = dbf.newDocumentBuilder(); // 创建Document对象 Document xmldoc = db.parse(xmlPath); // 获取根节点 Element root = xmldoc.getDocumentElement(); // 创建节点son,设置对应的id为004 Element son = xmldoc.createElement("son"); son.setAttribute("id", "004"); // 创建节点name Element name = xmldoc.createElement("name"); name.setTextContent("小儿子"); son.appendChild(name); // 创建节点age Element age = xmldoc.createElement("age"); age.setTextContent("0"); son.appendChild(age); // 把son添加到根节点中 root.appendChild(son); // 保存 TransformerFactory factory = TransformerFactory.newInstance(); Transformer former = factory.newTransformer(); former.transform(new DOMSource(xmldoc), new StreamResult(new File( xmlPath))); } catch (Exception e) { e.printStackTrace(); //System.out.println(e.getMessage()); } } // 利用XPath获取目标节点信息 public static Node selectSingleNode(String express, Element source) { Node result = null; //创建XPath工厂 XPathFactory xpathFactory = XPathFactory.newInstance(); //创建XPath对象 XPath xpath = xpathFactory.newXPath(); try { result = (Node) xpath.evaluate(express, source, XPathConstants.NODE); //System.out.println(result); } catch (XPathExpressionException e) { e.printStackTrace(); //System.out.println(e.getMessage()); } return result; } // 打印 public static void main(String[] args) { System.out.println("~~~~~~~~~~~~~~~~~~~~原数据~~~~~~~~~~~~~~~~~~~~~"); getFamilyMemebers(); System.out.println("~~~~~~~~~~~~~~~~~~~~修改数据~~~~~~~~~~~~~~~~~~~~~"); modifySon(); getFamilyMemebers(); System.out.println("~~~~~~~~~~~~~~~~~~~~删除数据~~~~~~~~~~~~~~~~~~~~~"); discardSon(); getFamilyMemebers(); System.out.println("~~~~~~~~~~~~~~~~~~~~添加数据~~~~~~~~~~~~~~~~~~~~~"); createSon(); getFamilyMemebers(); } }
二、使用XPath解析XML文档
-
XPath介绍
XPath 是一门在 XML 文档中查找信息的语言, 可用来在 XML 文档中对元素和属性进行遍历。
XPath表达式比繁琐的文档对象模型(DOM)代码要容易编写得多。如果需要从XML文档中提取信息,最快捷、最简单的办法就是在Java程序中嵌入XPath表达式。在Java版本中推出了javax.xml.xpath包,这是一个用于XPath文档查询的独立于XML对象模型的库。
-
XPath API
1.XPathFactory类
XPathFactory实例可用于创建XPath对象。该类只有一个受保护的空构造方法,常用的方法是:
static XPathFactory newInstance( ):获取使用默认对象模型(DOM)的新XPathFactory 实例。
2. XPath 接口
提供了对XPath计算环境和表达式的访问。XPath对象不是线程安全的,也不能重复载入。也就是说应用程序负责确保在任意给定时间内不能有多个线程使用一个XPath对象。
常用方法 :
XPathExpression compile(String expression):编译XPath表达式。
3. XPath.evaluate()
1)XPath.evaluate(String expression, InputSource source, QName returnType) :计算指定 InputSource 上下文中的 XPath 表达式并返回指定类型的结果。
2)XPath.evaluate(String expression, Object item, QName returnType) : 计算指定上下文中的 XPath 表达式并返回指定类型的结果。
其中第三个参数就是用于指定需要的返回类型,该参数的值都是在XPathConstants中已经命名的静态字段。如下:
- XPathConstants.BOOLEAN
- XPathConstants.NODESET
- XPathConstants.NUMBER
- XPathConstants.STRING
- XPathConstants.STRING
- XPathConstants.NODE
注:XPathConstants.NODE它主要适用于当XPath表达式的结果有且只有一个节点。如果XPath表达式返回了多个节点,却指定类型为XPathConstants.NODE,则evaluate()方法将按照文档顺序返回第一个节点。如果XPath表达式的结果为一个空集,却指定类型为XPathConstants.NODE,则evaluate( )方法将返回null。
-
java代码实现
1.xml文件
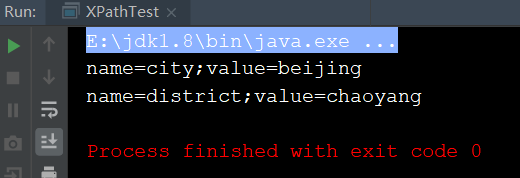
<location> <property> <name>city</name> <value>beijing</value> </property> <property> <name>district</name> <value>chaoyang</value> </property> </location>
2.解析上面的xml文件
import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.xpath.XPath; import javax.xml.xpath.XPathConstants; import javax.xml.xpath.XPathFactory; import org.w3c.dom.Document; import org.w3c.dom.Node; import org.w3c.dom.NodeList;
public class XPathTest { public static void main(String args[]){ try { //解析文档 DocumentBuilderFactory domFactory = DocumentBuilderFactory.newInstance(); domFactory.setNamespaceAware(true); // never forget this! DocumentBuilder builder = domFactory.newDocumentBuilder(); Document doc = builder.parse("city.xml"); XPathFactory factory = XPathFactory.newInstance(); //创建 XPathFactory XPath xpath = factory.newXPath();//用这个工厂创建 XPath 对象 NodeList nodes = (NodeList)xpath.evaluate("location/property", doc, XPathConstants.NODESET); String name = ""; String value = ""; for (int i = 0; i < nodes.getLength(); i++) { Node node = nodes.item(i); name = (String) xpath.evaluate("name", node, XPathConstants.STRING); value = (String) xpath.evaluate("value", node, XPathConstants.STRING); System.out.println("name="+name+";value="+value); } } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } } }
运行结果: