在Kubernetes中,Deployment是最基本的控制器对象
apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment spec: selector: matchLabels: app: nginx replicas: 2 template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.7.9 ports: - containerPort: 80
这个Deployment定义的编排动作非常简单:确保携带了app=nginx标签的Pod个数永远等于spec.replicas指定的个数,即两个
那究竟是Kubernetes项目中的哪个组件在执行这些操作呢?
是kube-controller-manage组件。这个组件是一系列控制器的集合,它们被统一放在pkg/controller目录下,因为它们遵循Kubernetes中一个通用的编排方式,控制循环(control loop)
$ cd kubernetes/pkg/controller/ $ ls -d */ deployment/ job/ podautoscaler/ cloud/ disruption/ namespace/ replicaset/ serviceaccount/ volume/ cronjob/ garbagecollector/ nodelifecycle/ replication/ statefulset/ daemon/ ...
上面这个目录的每一个控制器都以独有的方式负责某种编排功能,Deployment是这些控制器中的一种。
例如,如果现在有一种待编排的对象X,它有一个对应的控制器,那可以用一段伪代码描述这个控制循环
for { 实际状态 := 获取集群中对象 X 的实际状态(Actual State) 期望状态 := 获取集群中对象 X 的期望状态(Desired State) if 实际状态 == 期望状态{ 什么都不做 } else { 执行编排动作,将实际状态调整为期望状态 } }
实际状态一般来自于Kubernetes集群本身(kubelet心跳汇报容器状态和节点状态)
期望状态一般用于用户提交的YAML文件
像这种控制器设计原理就是用一种对象管理另一种对象。其中控制器对象本身负责定义被管理对象的期望状态(如replicas=2),而被控制对象的定义,则来自于一个模板(如template)
Deployment中template字段里的内容跟一个标准Pod对象的API定义丝毫不差,所有被这个Deployment管理的Pod实例,都是根据这个template字段内容创建出来的。

Deployment看似简单,实际上它实现了Kubernetes项目中一个非常重要的功能:Pod水平扩展伸缩(horizontal scaling out/in)
如果更新Deployment的Pod模板(比如修改了容器的镜像),Deployment就需要遵循滚动更新(rolling update)的方式来升级现有的容器。而这个能力的实现,依赖的是一个API对象:ReplicaSet
apiVersion: apps/v1 kind: ReplicaSet metadata: name: nginx-set labels: app: nginx spec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.7.9
从这个YAML文件中可以看到,一个ReplicaSet对象,七九就是由副本数目定义和一个Pod模板组成的,它的定义起就是Deployment的一个子集。Deployment控制器实际操纵的是这个ReplicaSet对象,而不是Pod对象。
它们三个之间的关系如下图:
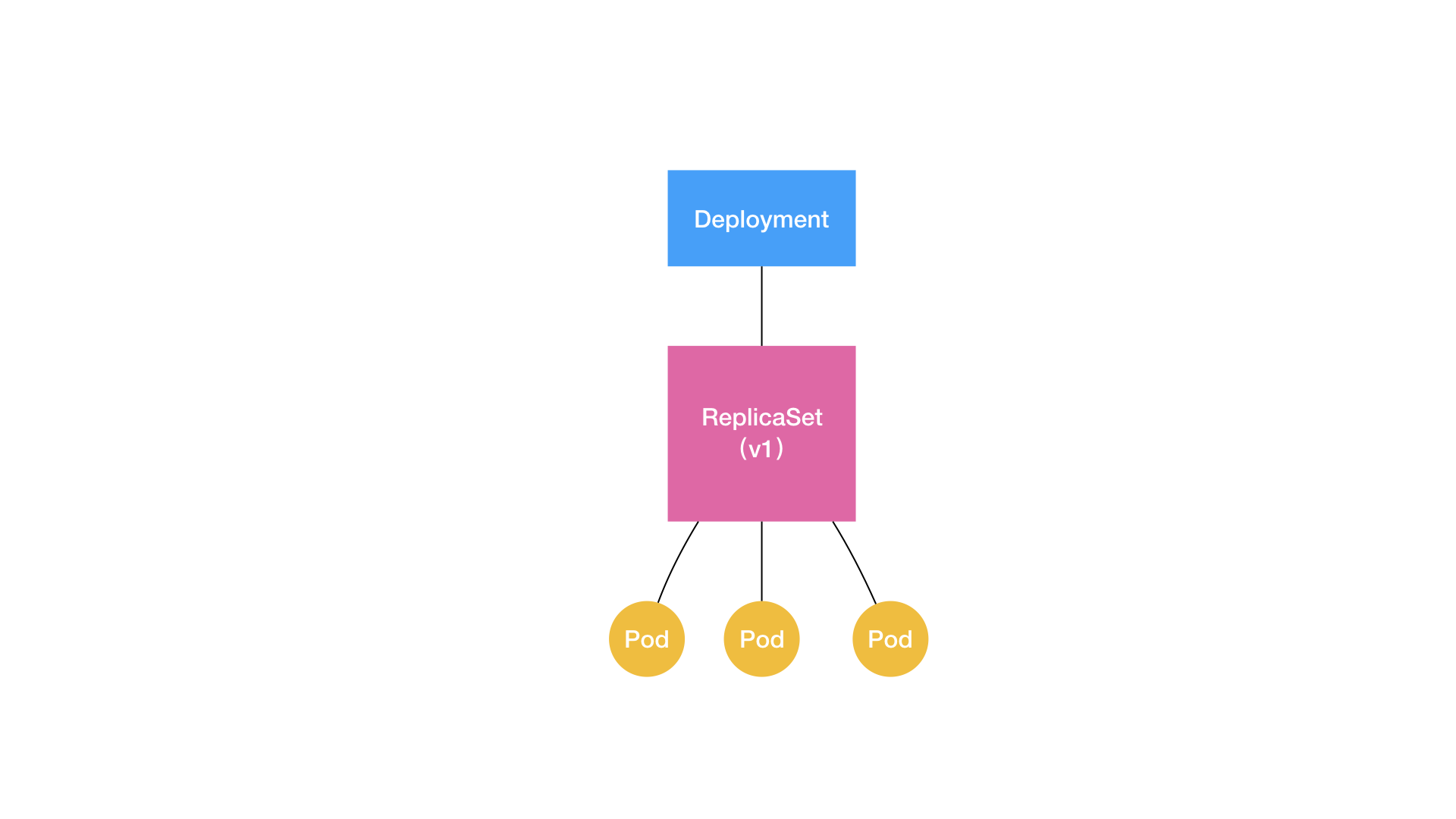
从上图中可以看出,Deployment是两层控制器,首先它通过ReplicaSet的个数来描述应用的版本,然后再通过ReplicaSet的属性来保证Pod的副本数量。即Deployment控制ReplicaSet,ReplicaSet控制Pod。
水平扩展的指令也就非常简单
$ kubectl scale deployment nginx-deployment --replicas=4 deployment.apps/nginx-deployment scaled