本例子是参考崔老师的Python3网络爬虫开发实战写的
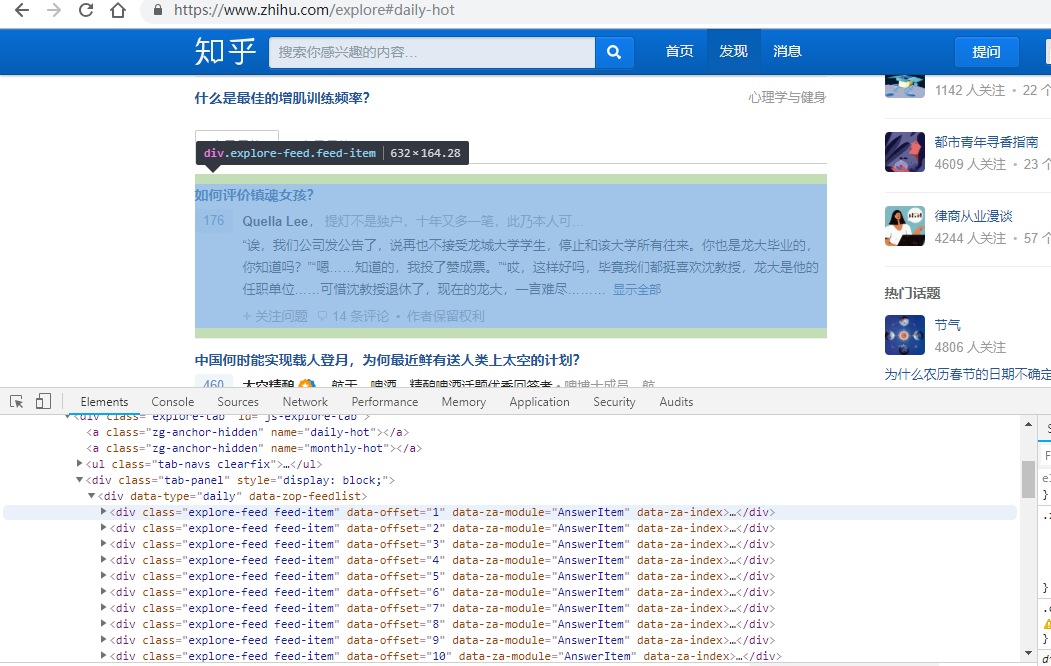
看网页界面:
热门话题都在 explore-feed feed-item的div里面
源码如下:
import requests from pyquery import PyQuery as pq url='https://www.zhihu.com/explore' #今日最热 #url='https://www.zhihu.com/explore#monthly-hot' #本月最热 headers={ 'User-Agent':"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", } html=requests.get(url,headers=headers).text doc=pq(html) #print(doc) items=doc('.explore-feed.feed-item').items() for item in items: question=item.find('h2').text() #获取问题 print(question) author=item.find('.author-link').text() #获取作者 print(author) answer=pq(item.find('.content').html()).text() #获取答案(老师写的没看懂,可能需要jquery知识) print(answer) print('===='*10) answer1=item.find('.zh-summary').text() #自己写的获取答案。。。 print(answer1) #第一种写入方法 file=open('知乎.txt','a',encoding='utf-8') file.write(' '.join([question,author,answer])) file.write(' '+'****'*50+' ') file.close() #第二种写入方法 不需要写关闭方法 with open('知乎.txt','a',encoding='utf-8') as fp: fp.write(' '.join([question, author, answer])) fp.write(' ' + '****' * 50 + ' ')
运行结果如下:

不过比较奇怪的地方是 url为今日最热和本月最热 所爬取的结果一模一样。。而且都只能爬下五个div里面的东西,可能是因为知乎是动态界面。需要用到selenium吧
还有就是
answer=pq(item.find('.content').html()).text()
#获取答案(老师写的没看懂,可能需要jquery知识)
这行代码没有看懂。。。。
还得学习jQuery