问题定义
在这个项目中会采用20 Newgroups的数据(http://qwone.com/~jason/20Newsgroups/),这时网上非常流行的对文本进行分类和聚类的数据集。
数据集中的数据分为两部分,一部分是用来训练算法模型的数据,一部分是用来评估算法的新数据。
网上提供了3个数据集,这里采用20news-bydate这个数据集进行项目研究。这个数据集是按照日期进行排序的,并去掉了部分重复数据和Header,共包含18846个文档。
导入数据
这里使用scikit-learn的Loadfiles导入文档数据,文档是按照不同的分类目录来保存的,文件目录名称即所属类别,文档目录结构如下:

在导入文档数据之前,要导入项目中所需的类库:
1 from sklearn.datasets import load_files 2 from sklearn.feature_extraction.text import CountVectorizer 3 from sklearn.feature_extraction.text import TfidfVectorizer 4 from sklearn.linear_model import LogisticRegression 5 from sklearn.naive_bayes import MultinomialNB 6 from sklearn.neighbors import KNeighborsClassifier 7 from sklearn.svm import SVC 8 from sklearn.tree import DecisionTreeClassifier 9 from sklearn.metrics import classification_report 10 from sklearn.metrics import accuracy_score 11 from sklearn.model_selection import cross_val_score 12 from sklearn.model_selection import KFold 13 from sklearn.model_selection import GridSearchCV 14 15 from sklearn.ensemble import AdaBoostClassifier 16 from sklearn.ensemble import RandomForestClassifier 17 from matplotlib import pyplot as plt 18 19 #导入数据 20 categories=['alt.atheism', 'rec.sport.hockey', 'comp.graphics', 21 'sci.crypt','comp.os.ms-windows.misc','sci.electronics', 22 'comp.sys.ibm.pc.hardware', 23 'sci.med','comp.sys.mac.hardware', 'sci.space', 24 'comp.windows.x','soc.religion.christian','misc.forsale', 25 'talk.politics.gus','rec.autos','talk.politics.mideast', 26 'rec.motorcycles','talk.politics.misc','rec.sport.baseball', 27 'talk.religion.misc' 28 ] 29 #导入训练数据 30 train_path='/home/aistudio/work/20news-bydate-train' 31 dataset_train=load_files(container_path=train_path,categories=categories) 32 #导入评估数据 33 test_path='/home/aistudio/work/20news-bydate-test' 34 dataset_test=load_files(container_path=test_path,categories=categories)
利用机器学习对文本进行分类,与对数值特征进行分类最大的区别是,对文本进行分类时先要提取文本特征,相对于之前的项目来说,提取道德文本特征属性个数是巨大的,会有超过万个的特征属性,甚至超过10万个。
文本特征提取
文本数据属性属于非结构化的数据,一般要转换成结构化的数据才能够通过机器学习算法进行文本分类,常见的做法是将文本转换成文档词项矩阵,矩阵中的元素可以使用词频或TF-IDF值等。
TF-IDF值是一种用于信息检索与数据挖掘的常用加权术。TF的意思是词频(Term Frequency),IDF是逆向文件频率(Inverse Document Frequency)。
TF-IDF的主要思想是:如果某一个词或短语在一篇文章中出现的频率高,并且在其他文章中很少出现,则认为此词或短语具有很好的类别区分能力,适合用来分类。
IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。
如果某一类文档C中包含词条t的文档数为m,而其他类包含t的文档总数为k,显然,所有包含t的文档数为n=m+k,当m大的时候,n也大,按照IDF公式得到的IDF值小,这说明该词条t的类别区分能力不强。但实际上,如果一个词条在一个类的文档中频繁出现,则说明该词条能够很好的代表这个类的文本特征,以区别于其他类文档,这就是IDF的不足之处。
在一份给定的文件中,TF值某一个给定的词语在该文件中出现的频率,这是对词数(Term Count)的归一化,以防止它偏向长的文件。
IDF是一个词语普遍重要性的度量,某一个特定的词语IDF,可以有总文件数目除以包含该词语的文件数目,再将得到的商取对数得到。
在scikit-learn中提供了词频和TF-IDF来进行文档特征提取的实现,分别是CountVectorizer和TfidTransformer。下面对训练数据集分别进行词频和TF-IDF的计算:
1 #数据准备和理解 2 #计算词频 3 count_vect=CountVectorizer(stop_words='english',decode_error='ignore') 4 x_train_counts=count_vect.fit_transform(dataset_train.data) 5 #查看数据维度 6 print(x_train_counts.shape)
词频的计算结果如下:
(10768, 124899)
接下来计算一下TF-IDF,
1 #计算TF-IDF 2 tf_transformer=TfidfVectorizer(stop_words='english',decode_error='ignore') 3 x_train_counts_tf=tf_transformer.fit_transform(dataset_train.data) 4 #查看数据维度 5 print(x_train_counts_tf.shape)
TF-IDF的计算结果如下:
(10768, 124899)
两次得到的结果相同。
评估算法
通过简单的查看数据维度,不能确定哪个算法对这个问题比较有效。下面采用10折交叉验证方式比较算法的准确度。
1 #设置评估算法的基准 2 num_folds=10 3 seed=7 4 scoring='accuracy'
接下来将会利用提取到的文本特征TF-IDF来对算法进行审查,审查的算法如下:
线性算法:逻辑回归(LR)
非线性算法:分类与回归树(CART),支持向量机(SVM),朴素贝叶斯分类器(MNB)可K近邻(KNN)
算法模型的初始化代码如下:
1 #评估算法:生成算法模型 2 models={} 3 models['LR']=LogisticRegression() 4 models['SVM']=SVC() 5 models['CART']=DecisionTreeClassifier() 6 models['MNB']=MultinomialNB() 7 models['KNN']=KNeighborsClassifier()
所有的算法使用默认参数,比较算法模型的准确度和标准方差,以便从中选择两道三种可以进一步研究的算法:
1 #比较算法 2 results=[] 3 for key in models: 4 kfold=KFold(n_splits=num_folds,random_state=seed) 5 cv_results=cross_val_score(models[key],x_train_counts_tf,dataset_train.target,cv=kfold,scoring=scoring) 6 results.append(cv_results) 7 print('%s : %f (%f)' % (key, cv_results.mean(),cv_results.std()))
执行结果显示,罗辑回归(LR)具有最好的准确度,朴素贝叶斯分类器(MNB)和K近邻(KNN)也值得进一步研究。
LR : 0.900726 (0.007471)
SVM : 0.049873 (0.013272) CART : 0.662983 (0.007810) MNB : 0.882708 (0.007777) KNN : 0.795786 (0.009604)
接下来看一下算法每次执行结果的分布情况--采用箱线图:
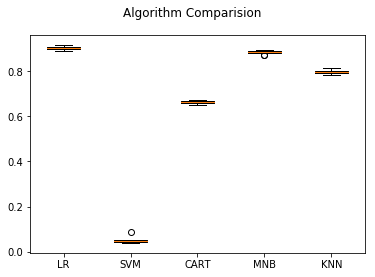
从图中可以看到,朴素贝叶斯分类器数据离散程度比较好,罗辑回归的偏差比较大。
算法结果的离散程度能够反应算法对数据的使用情况,所以对罗辑回归和朴素贝叶斯进行进一步研究,实行算法调参。
算法调参
通过上面的分析,逻辑回归(LR)和朴素贝叶斯分类器(MNB)效果比较好,可以对其进行参数调参来进一步提高准确度。
在逻辑回归中的超参数是C,C是目标的约束函数,C值越小则正则化强度越大。对C进行调参,每次给C设定一定数量的值,重复这个步骤,直到找到最优值。
1 #算法调参--LR 2 param_grid={} 3 param_grid['C']=[0.1,3,5,13,15] 4 model=LogisticRegression() 5 kfold=KFold(n_splits=num_folds,random_state=seed) 6 grid=GridSearchCV(estimator=model,param_grid=param_grid,scoring=scoring,cv=kfold) 7 grid_result=grid.fit(X=x_train_counts_tf,y=dataset_train.target) 8 print('最优:%s s使用 %s' % (grid_result.best_score_,grid_result.best_params_))
可以看到C的最优参数是15(15是通过多次调整param_grid参数得到的)。执行结果如下:
最优:0.9221768202080238 s使用 {'C': 15}
通过对罗辑回归调参,准确度提升到0.92,提升还是比较大的。
朴素贝叶斯分类器有一个alpha参数,该参数是一个平滑参数,默认值为1.0,可以尝试对此进行调试。
1 #算法调参--MNB 2 param_grid={} 3 param_grid['alpha']=[0.001,0.01,0.1,1.5] 4 model=MultinomialNB() 5 kfold=KFold(n_splits=num_folds,random_state=seed) 6 grid=GridSearchCV(estimator=model,param_grid=param_grid,scoring=scoring,cv=kfold) 7 grid_result=grid.fit(X=x_train_counts_tf,y=dataset_train.target) 8 print('最优:%s s使用 %s' % (grid_result.best_score_,grid_result.best_params_))
同样,通过多次调整param_grid,得到朴素贝叶斯分类器的alpha参数最优值0.01.
最优:0.9153046062407132 s使用 {'alpha': 0.01}
接下来审查集成算法。
集成算法
除了调参,提高算法准确度的方法是使用集成算法。下面对以下两种集成算法进行比较,看看能否进一步提高模型的准确度。
- 随机森林(RF)
- AdaBoost(AB)
1 #集成算法 2 ensembles={} 3 ensembles['RF']=RandomForestClassifier() 4 ensembles['AB']=AdaBoostClassifier() 5 #比较集成算法 6 results=[] 7 for key in ensembles: 8 kfold=KFold(n_splits=num_folds,random_state=seed) 9 cv_results=cross_val_score(ensembles[key],x_train_counts_tf,dataset_train.target,cv=kfold,scoring=scoring) 10 results.append(cv_results) 11 print('%s: %f (%f)' % (key,cv_results.mean(),cv_results.std())) 12 #箱线图 13 fig=plt.figure() 14 fig.suptitle('Algorithm Comparision') 15 ax=fig.add_subplot(111) 16 plt.boxplot(results) 17 ax.set_xticklabels(ensembles.keys()) 18 plt.show()
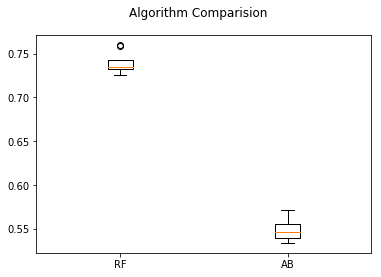
RF: 0.739134 (0.011091) AB: 0.548477 (0.011514)
从箱线图来看,随机森林(RF)的分布比较均匀,对数据的适用性比较高,更值得进一步研究。
集成算法调参
通过集成算法的分析,发现随机森林算法具有较高的准确度和非常稳定的数据分布。随机森林有一根很重要的参数n_estimators,下面对n_estimators进行调参优化,争取找到最优解。
1 #调参RF 2 param_grid={} 3 param_grid['n_estimators']=[10,100,150,200] 4 model=RandomForestClassifier() 5 kfold=KFold(n_splits=num_folds,random_state=seed) 6 grid=GridSearchCV(estimator=model,param_grid=param_grid,scoring=scoring,cv=kfold) 7 grid_result=grid.fit(X=x_train_counts_tf,y=dataset_train.target) 8 print('最优:%s s使用 %s' % (grid_result.best_score_,grid_result.best_params_))
调参之后的最优结果如下:
最优:0.8697065378900446 s使用 {'n_estimators': 200}
确定最终模型
通过对算法的比较和调参发现,逻辑回归具有最高的准确度,因此使用逻辑回归算法生成算法模型。
为了保持数据特征的一致性,对新数据进行文本特征提取时应进行特征扩充,下面使用之前生成的tf_transformer的transform方法来处理评估数据集。
1 #生成模型 2 model=LogisticRegression(C=15) 3 model.fit(x_train_counts_tf,dataset_train.target) 4 x_test_counts=tf_transformer.transform(dataset_test.data) 5 predictions=model.predict(x_test_counts) 6 print(accuracy_score(dataset_test.target,predictions)) 7 print(classification_report(dataset_test.target,predictions))
从结果可以看到,准确度大概达到85%,与期待的结果比较一致。
0.8515625
precision recall f1-score support
0 0.81 0.76 0.79 319
1 0.74 0.80 0.77 389
2 0.78 0.74 0.76 394
3 0.70 0.75 0.73 392
4 0.82 0.85 0.84 385
5 0.85 0.77 0.81 395
6 0.81 0.90 0.85 390
7 0.90 0.90 0.90 396
8 0.96 0.95 0.96 398
9 0.90 0.94 0.92 397
10 0.96 0.97 0.97 399
11 0.96 0.93 0.95 396
12 0.78 0.79 0.78 393
13 0.91 0.87 0.89 396
14 0.90 0.92 0.91 394
15 0.84 0.93 0.88 398
16 0.97 0.88 0.92 376
17 0.87 0.76 0.81 310
18 0.67 0.62 0.64 251
micro avg 0.85 0.85 0.85 7168
macro avg 0.85 0.84 0.85 7168
weighted avg 0.85 0.85 0.85 7168