攻击
特征:应用程序是否使用特定的系统调用,以及使用特定的硬件组件或访问Internet。(one-hot 稀疏向量)
网络:DNN+dropout
制作对抗样本:(我们的目标是将恶意应用程序分类为良性,即给定一个恶意输入X,我们希望分类结果y0 = 0。)
为了制作一个对抗性的样本,我们主要采取两个步骤。首先,我们计算F关于X的梯度来估计X的扰动会改变F输出的方向。在第二步中,我们选择一个具有最大正梯度的扰动δ到我们的目标类y0中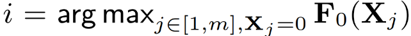 。注意,我们只考虑Xj = 0时位置j的正变化,这对应于向X中添加特征。
。注意,我们只考虑Xj = 0时位置j的正变化,这对应于向X中添加特征。
理想情况下,我们保持这个变化很小,以确保不会由于梯度的中间变化而引起F的负变化。对于计算机视觉来说,这不是问题,因为像素的值是连续的,可以在非常小的步骤中改变。然而,在恶意软件检测的情况下,我们没有连续的数据,而是离散的输入值:因为x20;1m是一个二进制指示向量,我们唯一的选择是将X中的一个分量正好增加1,以保留对F的有效输入。对抗性的示例构建过程是迭代的:在计算梯度之后,我们选择一个梯度最大的特性用于目标类,并更改它在X中的值(即通过对应用程序进行相应的更改),以获得新的输入向量X(1)。然后我们重新计算这个新输入X(1)下的梯度,并找到第二个要改变的特征。我们重复这个过程,直到a)我们达到了允许更改的最大数量限制,或者b)我们成功地造成了错误分类。

在视觉中使用无穷范数限制扰动的变化,但在这里,每一个扰动变化都是1,所以我们使用L1范数限制扰动的变化。(k设置为20)
误分类率是由应用了对抗性制作算法后被误分类但在此之前被正确分类的恶意软件样本的百分比定义的。
防御
我们考虑简单的特征约简,一种基于它们出现的位置和频率来包含特征的简单方法,以及一种基于相互信息的更复杂的特征约简。我们的目标是评估在一般情况下特征约简是否可以用来加强神经网络对抗对抗加工。distillation [18], and re-training [21].
简单的特征约简:对数据集施加特征限制。限制1. apk的AnroidManifest.xml中,通过将神经网络的训练限制为只使用manifestonly特征,我们将分类器的重点放在我们实际改变的特征上。限制2.我们只考虑在r最大的特性类中没有出现的特性。我们在表1中演示了8个特性类的基数。很大一部分特性(超过50%)是由url组成的,这些url对每个应用程序来说都是惟一的,因此不能帮助区分良性应用程序和恶意应用程序。在最大的特性类中出现的其他特性也表现出类似的行为。有了这个我们称为smallonly的特性限制,我们尝试定义一种简单的方法来过滤掉所有这些特性。我们仅为r = 1和2实例化了small,这使得我们在应用特性限制之后分别拥有234845和49116个特性。限制3. 有了这个限制,我们只考虑至少出现在r应用程序中的特性。因此,我们直接过滤掉那些在一个目标类的代表中不一致出现的特性,因此这些特性不会被用来检测属于它们的应用程序。我们称这个特性限制为onlyfreq。实际上,onlyfreq试图实现与onlysmall类似的目标,但是限制特性集的确定是不同的。这也反映在应用限制之后剩下的特性的数量上:我们为r2f1实例化了onlyfreq;2;3;4g,分别有177438、95871、60052、44942个功能。简单的特征约简并不是一种合适的机制来加强你的神经网络在恶意软件检测领域的对抗机制。
基于相互信息的更复杂的特征约简:为了使用互信息来选择特征,我们为每个特征/目标类对计算它,即我们计算互信息I,其中X是一个特征的概率,Y是一个目标类的概率。然后根据它们与目标类的相互信息对所有特性进行排序,并从中挑选出n个最高的。
在前一节中,我们的发现表明使用较少的特性并不一定会使对抗性的制作更加困难。似乎很少有数字特性会导致容易的干扰,因为每个单独的特性对应用程序的分类都有更大的影响。通过使用基于互信息的特征约简,我们使得我们的网络更容易受到敌对工艺的影响。然而,在选择最重要特征的情况下,在某些情况下,经过训练的模型不太容易出现对抗性样本。因此,我们不希望排除这样一种可能性,即提高对使用特性缩减的对抗性:更细粒度的分析可能导致积极的结果,我们将其留给未来的工作。
接下来我们来看看蒸馏。虽然蒸馏最初是由Hinton等人[10]提出的, 知识蒸馏将知识从一个复杂的机器学习模型迁移到另一个紧凑的机器学习模型,而一般紧凑的模型在性能上会有一些降低。本文探讨了同等复杂度模型之间的知识迁移,并发现知识蒸馏中的学生模型在性能上要比教师模型更强大(相当于)。但Papernot at等人[18]最近也提出将其作为对抗对抗加工的防御机制。蒸馏的基本思想如下:假设我们已经有了一个神经网络分类训练数据集F (X)到目标类Y和生产作为输出概率分布/ Y(softmax)。此外,假设我们想要在相同的数据集X上训练第二个神经网络F0,以获得相同(甚至更好)的性能。现在,我们不使用随数据集而来的目标类标签,而是使用网络F的输出F(X)作为X的标签来训练F0。F不会分配一个唯一的标签Y给X,而是一个概率分布在Y .因此, 与输出一个简单的标签,就选择最可能的类对比,新的标签包含更多关于X的不同的目标类的信息。(不使用常规的softmax归一化,而是用: 其中T是蒸馏的参数)。当T较大时,输出概率更趋于均匀分布,当T较小时,F的输出更小。为了达到良好的蒸馏效果,我们使用了在高温T下产生的原始网络F的输出,并将其作为类标签来训练新的网络F’。
其中T是蒸馏的参数)。当T较大时,输出概率更趋于均匀分布,当T较小时,F的输出更小。为了达到良好的蒸馏效果,我们使用了在高温T下产生的原始网络F的输出,并将其作为类标签来训练新的网络F’。
作为最后的对策,我们尝试使用对抗性样本重新训练分类器(Re-training)。该方法最初是由Szegedy等人在[21]提出的,包括以下几个步骤:在原始数据集D = B +M上训练分类器F,其中B为良性应用集,M为恶意应用集2。使用3.3节中描述的正向梯度法制作F的对抗性样本A。3.使用最后一步中的对抗样例作为附加的恶意样例,在F上迭代额外的训练时间。
通过再训练,我们的目标是提高F的泛化性能,即提高F在训练集外样本上的分类性能。良好的泛化性能通常会使分类器对小扰动的敏感性降低,从而提高对对抗加工的弹性。
Goodfellow等人[7]提出了对抗再训练的一般思想的另一种方法:他们不是在实际制作的对抗样本上进行训练,而是制定了一个对抗损失函数,该函数通过对网络梯度方向的扰动来整合了对抗再训练的可能性。这使得他们可以在训练过程中不断地加入逆向制作的样本,并提供无限的样本。我们认为这种方法也应该在安全关键领域进行进一步的研究,并认为这是未来工作的一个有前途的方向。
结论:我们考虑了四种潜在的防御机制,并评估了它们对神经网络对抗对抗加工的易感性的影响。特征约简,既简单又通过相互信息实现,通常会使神经网络在对抗机制下变得更弱。更少的重要特征使得制作对抗性样本更容易。这是由于每个特性对网络输出分布的影响较大造成的。在这一点上,我们不建议将特征减少作为一种防御机制。未来的工作将不得不识别,潜在的更复杂的,特征减少方法,实际上增加了网络对对抗工艺的抵抗。我们还研究了精馏和再训练,它们最初都被提出作为对抗计算机视觉领域中对抗性加工的防御机制。精馏确实有一个积极的影响,但在计算机视觉领域表现不佳。造成这种情况的原因在今后的工作中必须加以研究。简单的再培训可以在不同的网络中一致地降低误分类率。然而,选择适当数量的对抗性训练样本对这种减少有显著的影响。迭代地对网络应用再培训可能会进一步提高网络的抵抗力。