Apriori算法是很多数据挖掘算法的基础,很多算法都以此算法为基础。
该算法的目的是找到数据集中的频繁项集,以及这些项集之间的关联规则。
频繁项集是指那些经常出现在一起的集合。
1.Apriori算法的基本标准
频繁项集中最重要的标准是支持度和可信度。
支持度被定义为数据集中包含该项集的记录所占的比例。通俗来讲,支持度就是这一项集占总共项集的百分比。
可信度是针对一条关联规则定义的,例如尿布>葡萄酒;这条规则的可信度被定义为“支持度({尿布,葡萄酒})/ 支持度({尿布})”,用符号表示就是:
X对于Y的置信度,Confidence(X⇐Y)=P(X|Y)=P(XY)/P(Y)
举例来说,(豆奶,尿布)的支持度为百分之十,同时购买尿布和豆奶的人只有百分之十,豆奶对于尿布的置信度为百分之50,意思就是,在购买尿布的人中,有百分之五十也购买了豆奶。(后对前)
2.Apriori算法的基本原理
原理是说如果某个项集是频繁的,那么他的所有子集也是频繁的。反过来更有用,也即是说一个子集是非频繁的,那么他的所有超集也一定是非频繁的。
该算法发现频繁集的方法如下:
首先生成所有单个物品的项集,扫描每个项集的支持度,把小于最小支持度的项集去掉;
然后对剩下来的集合进行组合生成比上一项多一个元素的项集,重新扫描每个项集的支持度,去掉不满足的;
重复执行上述步骤,直到所有项集都去掉(或者是:直到无法找到频繁k+1项集为止,对应的频繁k项集的集合即为算法的输出结果)。
可以参考如下例子:
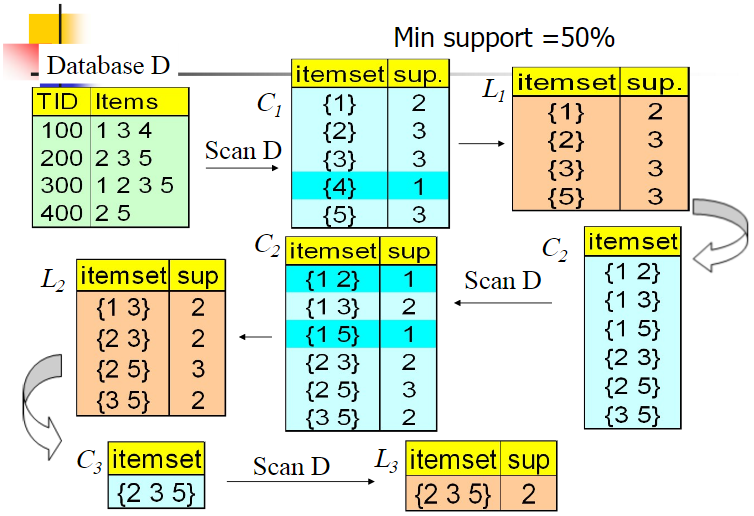
在重新组合生成k+1个元素的时候,采用一种方法,是将前k-2个项相同时,才将两个集合合并原因是:
k-2
当利用{0,1}、{0,2}、{1,2}创建时,如果将每两个合并就会得到同样结果的集合,若只对k-2=1,第一个元素相同的集合求并,则只有一次操作,确保了遍历次数最少。
发现关联规则的方法:
计算所有关联规则的置信度,设置阈值,筛选规则。
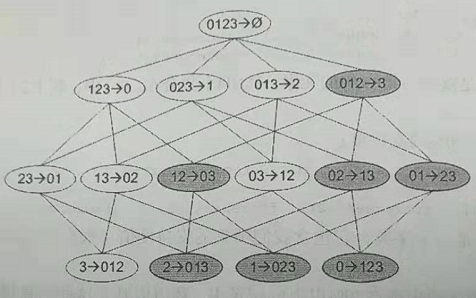
例如从项集{0,1,2,3}产生的所有关联规则,灰色部分代表小于某一可信度的项集,可以直接去掉。
类似于频繁集的规则,假设规则0,1,2 --> 3不满足最小可信度,则以3作为后件的规则可信度也会较低。而且任何以(0,1,2)为子集的左部也不会满足最小可信度。