Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel Aggregation Network
PAN是一个任意形状文字检测模型,称之为像素聚合网络(PAN)。是psenet的改进版本,最突出的特点是既快又好。
核心是: 可学习的后处理方法——像素聚合法,它能够通过预测出的相似向量来引导文字像素去纠正核参数
本文作者之一谢恩泽的另一篇SPCnet( Supervised Pyramid Context Network)其中有一个亮点rescore模块,感觉跟本文的文本实例重建有一点点的联系。
PAN的简单流程如图 2,有两个步骤
(1)用分割网络预测文字区域、核区域(与psenet中的核类似,为文本区域的缩放)以及相似向量;
(2)从预测的核中重建完整的文字实例

1.网络特征提取及预测部分
整体结构如下:
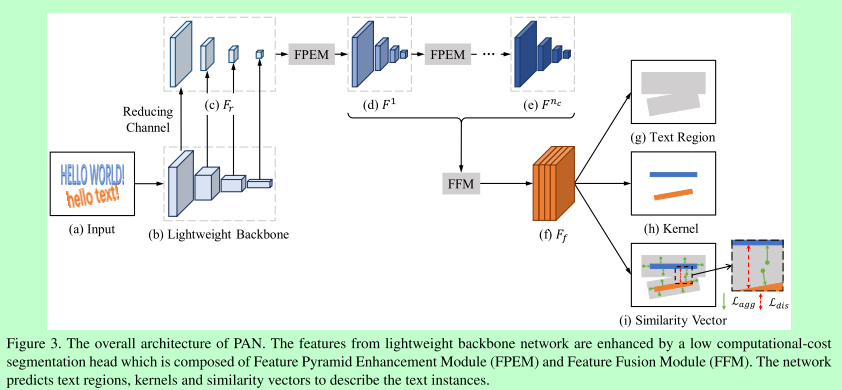
FPEM(特征金字塔增强模块)以及FFM(特征融合)模块,目的是构造轻量级的FPN,提取更好的特征
为了加快网络的速度,对resnet18得出的feature map的维度进行了减小,对应上图的reducing channel过程;
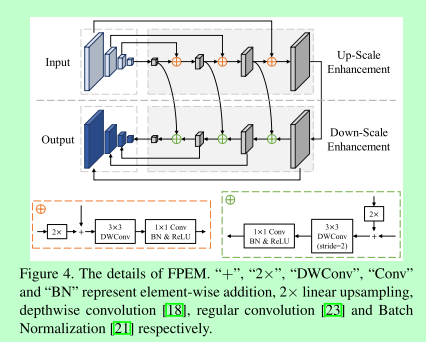
其次是特征图的多层融合,单个FPEM模块借鉴FPN(如图4),FPEM是一个 U形模组,由两个阶段组成,up-scale 增强、down-scale 增强,特征从上到下融合,又从下往上融合,
不断增强各个尺度的特征信息,因维度小以及DWConv使得计算量小;
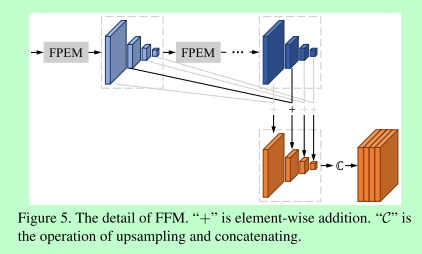
FPEM模块可以级联,多个模块产生多个结果,这些结果可以通过FFM模块进行融合(如图5),同样尺寸的feature map采用+操作,然后进行upsampling再拼接得到最终的feature map.
在得到最终的feature map后,网络的输出包含三个部分:如图3(g)、(h)、(i)
(g)文本区域,(h)核区域,(i)每个元素的相似向量(4channels,用于像素聚合)
2.像素聚合阶段:(核心部分文字实例重建)

上面 这一段是旷视官方总结的,非常精练清楚。需要结合loss计算对于原理会理解更清楚。
融合过程:
从kernel中通过连通域确定初始的文本实例集合 K 对于每一个文本实例Ki,按4方向从text_region中融合文本像素。
融合条件: 文本像素点 p 和 Ki 之间similarity vectors的欧式距离< d (测试过程中d默认为6)。
重复步骤直到text_region没有文本像素
3.Loss计算:
loss部分包含文本区域、核区域、agg(使类内距离小)、dis(使类间距离大)

文本区域和核区域的Loss与Psenet一样,采用dice loss,因为文本和非文本的数量严重不均衡。
主要是agg和dis两部分loss的计算比较复杂。
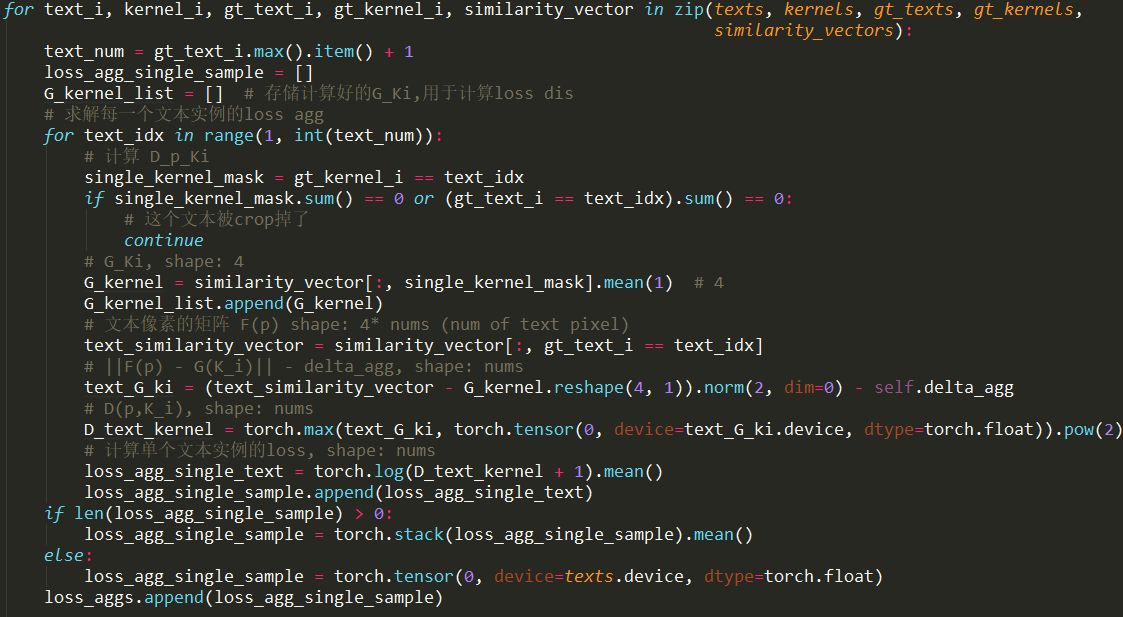
agg_loss的公式讲解以及代码如下图:(转自知乎周军,以及github周军的PAN代码)
结合代码更好理解:

dis_loss讲解以及代码:

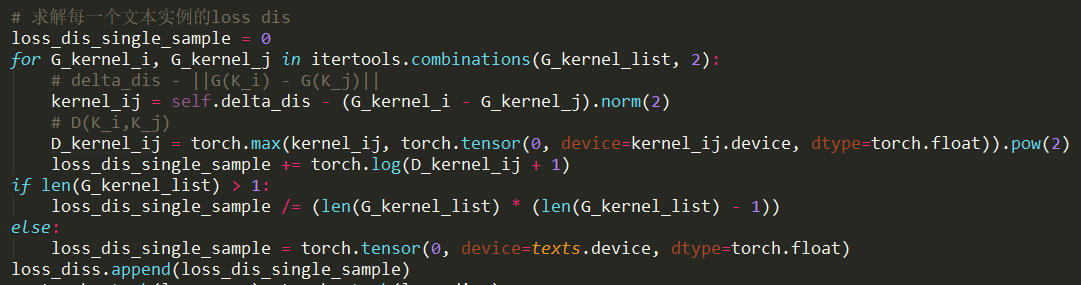
计算Loss时,文本loss采用ohem,agg和dis两部分Loss只关心ground truth 区域内的像素(去除冗余与Psenet一样)。
实验结果略,论文中sota对比以及消融实验非常详细。
参考:
https://www.zhihu.com/search?type=content&q=%20Pixel%20Aggregation%20Network
https://zhuanlan.zhihu.com/p/81415166