【实验目的】
通过完成预测分析法的语法分析程序,了解预测分析法和递归子程序法的区别和联系。使了解语法分析的功能,掌握语法分析程序设计的原理和构造方法,训练掌握开发应用程序的基本方法。
【实验内容】
u 根据某一文法编制调试 LL ( 1 )分析程序,以便对任意输入的符号串进行分析。
u 构造预测分析表,并利用分析表和一个栈来实现对上述程序设计语言的分析程序。
u 分析法的功能是利用LL(1)控制程序根据显示栈顶内容、向前看符号以及LL(1)分析表,对输入符号串自上而下的分析过程。
【设计思想】
(1)定义部分:定义常量、变量、数据结构。
(2)初始化:设立LL(1)分析表、初始化变量空间(包括堆栈、结构体、数组、临时变量等);
(3)控制部分:从键盘输入一个表达式符号串;
(4)利用LL(1)分析算法进行表达式处理:根据LL(1)分析表对表达式符号串进行堆栈(或其他)操作,输出分析结果,如果遇到错误则显示错误信息。
1.主程序流程图

2.核心算法流程图

3.预测分析控制程序流程图

4.程序源代码
#include<stdio.h> #include<stdlib.h> #include<string.h> #include<dos.h> char A[20]; /*分析栈*/ char B[20]; /*剩余串*/ char v1[20] = { 'i' , '+' , '*' , '(',')' , '#' }; /*终结符 */ char v2[20] = { 'E' , 'G' , 'T' , 'S' , 'F' }; /*非终结符 */ int j = 0, b = 0, top = 0, l; /*L 为输入串长度 */ typedef struct type/*产生式类型定义 */ { char origin; /*大写字符 */ char array[5];/*产生式右边字符 */ int length; /*字符个数 */ } type; type e, t, g, g1, s, s1, f, f1; /*结构体变量 */ type C[10][10]; /*预测分析表 */ void print() /*输出分析栈 */ { int a; /*指针*/ for (a = 0; a <= top + 1; a++) printf("%c", A[a]); printf(" "); } void print1() /*输出剩余串*/ { int j; for (j = 0; j<b; j++) /*输出对齐符*/ printf(" "); for (j = b; j <= l; j++) printf("%c", B[j]); printf(" "); } void main() { int m, n, k = 0, flag = 0, finish = 0; char ch, x; type cha; /*用来接受 C[m][n]*/ /*把文法产生式赋值结构体*/ e.origin = 'E'; strcpy_s(e.array, "TG"); e.length = 2; t.origin = 'T'; strcpy_s(t.array, "FS"); t.length = 2; g.origin = 'G'; strcpy_s(g.array, "+TG"); g.length = 3; g1.origin = 'G'; g1.array[0] = '^'; g1.length = 1; s.origin = 'S'; strcpy_s(s.array, "*FS"); s.length = 3; s1.origin = 'S'; s1.array[0] = '^'; s1.length = 1; f.origin = 'F'; strcpy_s(f.array, "(E)"); f.length = 3; f1.origin = 'F'; f1.array[0] = 'i'; f1.length = 1; for (m = 0; m <= 4; m++) /*初始化分析表*/ for (n = 0; n <= 5; n++) C[m][n].origin = 'N'; /*全部赋为空*/ /*填充分析表*/ C[0][0] = e; C[0][3] = e; C[1][1] = g; C[1][4] = g1; C[1][5] = g1; C[2][0] = t; C[2][3] = t; C[3][1] = s1; C[3][2] = s; C[3][4] = C[3][5] = s1; C[4][0] = f1; C[4][3] = f; printf("提示: 本程序只能对由'i' , '+' , '*' , '(',')' 构成的以' #' 结束的字符串进行分析, "); printf("请输入要分析的字符串: "); do/*读入分析串*/ { scanf_s("%c", &ch); if ((ch != 'i') && (ch != '+') && (ch != '*') && (ch != '(') && (ch != ')') && (ch != '#')) { printf("输入串中有非法字符 "); exit(1); } B[j] = ch; j++; } while (ch != '#'); l = j; /*分析串长度*/ ch = B[0]; /*当前分析字符*/ A[top] = '#'; A[++top] = 'E'; /*' #' , ' E' 进栈*/ printf("步骤 分析栈 剩余字符 所用产生式 "); do { x = A[top--]; /*x 为当前栈顶字符*/ printf("%d", k++); printf(" "); for (j = 0; j <= 5; j++) /*判断是否为终结符*/ if (x == v1[j]) { flag = 1; break; } if (flag == 1) /*如果是终结符*/ { if (x == '#') { finish = 1; /*结束标记*/ printf("acc! "); /*接受 */ getchar(); getchar(); exit(1); } /*if*/ if (x == ch) { print(); print1(); printf("%c 匹配 ", ch); ch = B[++b]; /*下一个输入字符*/ flag = 0; /*恢复标记*/ } /*if*/ else/*出错处理*/ { print(); print1(); printf("%c 出错 ", ch); /*输出出错终结符*/ exit(1); } } else/*非终结符处理*/ { for (j = 0; j <= 4; j++) if (x == v2[j]) { m = j; /*行号*/ break; } for (j = 0; j <= 5; j++) if (ch == v1[j]) { n = j; /*列号*/ break; } cha = C[m][n]; if (cha.origin != 'N') /*判断是否为空*/ { print(); print1(); printf("%c->", cha.origin); /*输出产生式*/ for (j = 0; j<cha.length; j++) printf("%c", cha.array[j]); printf(" "); for (j = (cha.length - 1); j >= 0; j--) /*产生式逆序入栈*/ A[++top] = cha.array[j]; if (A[top] == '^') /*为空则不进栈*/ top--; } /*if*/ else/*出错处理*/ { print(); print1(); printf("%c 出错 ", x); /*输出出错非终结符*/ exit(1); } } } while (finish == 0); }
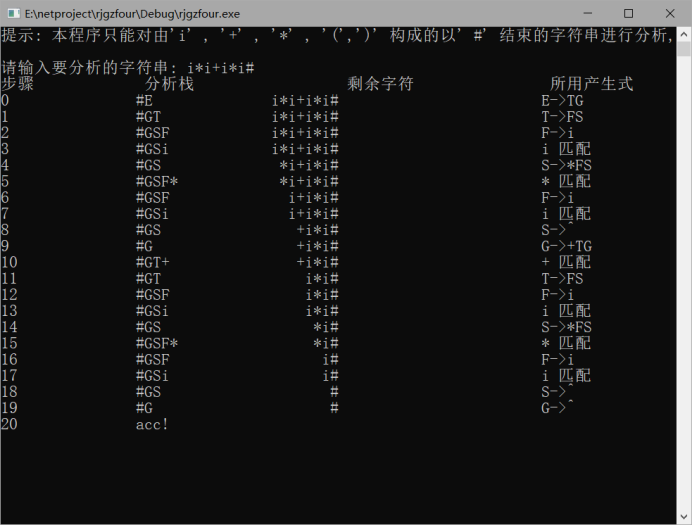
6.程序运行截图