RDD 与分布式共享内存的异同
分布式共享内存 (Distributed Shared Memory ,DSM) 是一种通用的内存数据抽象 ,这种通用性同时也使其在商用集群上实现有效的容错 性和一致性更加困难。
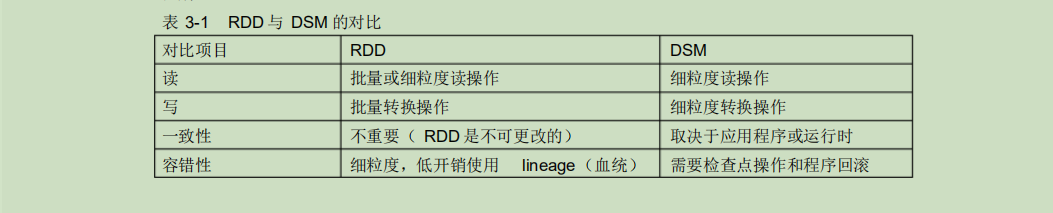
此外, RDD对于扫描类型操作, 如果内存不足以缓存整个RDD,就进行部分缓存, 将内存容纳不下的分区存储到磁盘上。
Spark算子的作用
1)输入:在 Spark 程序运行中,数据从外部数据空间(如分布式存储:textFile 读取HDFS等, parallelize 方法输入 Scala集合或数据)输入
Spark,数据进入 Spark 运行时数据空间,转化为 Spark 中的数据块,通过BlockManager 进行管理。
2)运行:在 Spark 数据输入形成 RDD后便可以通过变换算子,如fliter 等,对数据进行操作并将 RDD转化为新的 RDD,通过 Action 算子,触发 Spark 提交作业。如果数据需要复用,可通过Cache算子,将数据缓存到内存。
3)输出:程序运行结束数据会输出
Spark 运行时空间,存储到分布式存储中(如saveAsTextFile输出到 HDFS),或 Scala数据或集合中( collect 输出到 Scala集合, count 返回 Scalaint 型数据)。
Spark的核心数据模型是RDD,但 RDD是个抽象类,具体由各子类实现, 如 MappedRDD、ShuffledRDD等子类。 Spark 将常用的大数据操作都转化成为RDD的子类。
算子分类
算子大致可以分为三大类。
1)Value 型的 Transformation 算子, 这种变换并不触发提交作业,针对处理的数据项是Value 型的数据。
2) Key-Value 型的 Transfromation 算子, 这种变换并不触发提交作业,针对处理的数据项是 Key-Value 型的数据对。
3)Action 算子,这类算子会触发SparkContext 提交作业 Job。