Redis-避免缓存穿透的利器之BloomFilter
Redis相关的问题的时候,经常提到BloomFilter(布隆过滤器)这玩意的使用场景是真的多,而且用起来是真的香,原理也好理解,看一下文章就可以在面试官面前侃侃而谈了
布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难

那应用的场景在哪里呢?一般我们都会用来防止缓存击穿
简单来说就是你数据库的id都是1开始然后自增的,那我知道你接口是通过id查询的,我就拿负数去查询,这个时候,会发现缓存里面没这个数据,我又去数据库查也没有,一个请求这样,100个,1000个,10000个呢?你的DB基本上就扛不住了,如果在缓存里面加上这个,是不是就不存在了,你判断没这个数据就不去查了,直接return一个数据为空不就好了嘛
作者:敖丙
链接:https://juejin.im/post/5db69365518825645656c0de
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
https://www.cnblogs.com/Ccwwlx/p/11947257.html
redis常见问题
缓存和数据库双写一致性问题
缓存雪崩问题
缓存击穿问题
缓存的并发竞争问题
单线程的 Redis 为什么这么快
原因主要是以下三点:
- 纯内存操作
- 单线程操作,避免了频繁的上下文切换
- 采用了非阻塞 I/O 多路复用机制
Redis 的过期策略和内存淘汰机制
Redis 采用的是定期删除+惰性删除策略。
Redis 和数据库双写一致性问题
一致性问题还可以再分为最终一致性和强一致性。数据库和缓存双写,就必然会存在不一致的问题。前提是如果对数据有强一致性要求,不能放缓存。我们所做的一切,只能保证最终一致性。
另外,我们所做的方案从根本上来说,只能降低不一致发生的概率。因此,有强一致性要求的数据,不能放缓存。首先,采取正确更新策略,先更新数据库,再删缓存。其次,因为可能存在删除缓存失败的问题,提供一个补偿措施即可,例如利用消息队列。
缓存雪崩,即缓存同一时间大面积的失效,这个时候又来了一波请求,结果请求都怼到数据库上,从而导致数据库连接异常。
zadd marvel:user:f1:grade0:1010:20190731 2 1008
setnx mykey myvalue ,在redis sentinel集群中,这条命令先是落到了主库。假设这时主库down了,而这条数据还没来得及同步到从库,sentinel将从库中的一台选举为主库了。这时,我们的新主库中并没有mykey这条数据,若此时另外一个client执行 setnx mykey hisvalue , 也会成功,即也能得到锁。这就意味着,此时有两个client获得了锁Redis常用命令
keys键操作
exists-----测试key是否存在
del-----删除key
type-----返回key的类型
keys-----匹配满足的key
rename------改key名
dbsize-----当前数据库key的数量
expire-----设置key过期时间
ttl-----key剩余过期时间
move-----将key移动到指定数据库
flushdb-----删除当前数据库的所有key
flushall-----删除所有数据库的key
String键操作
set-----设置单个key
mset-----批量添加key
mget-----批量获取
incr-----key值+1
decr-----key值-1
incrby-----对key加指定值
decrby-----对key减定值
appeand-----在key值后追加
substr-----截取字符串(包前包后)
List类型操作
lpush-----在list头部添加
rpop-----批量添加
llen-----(存在对应key返回长度,反之-1,类型不对应会报错)
lrange-----在指定区间查找元素
rpush-----删除尾部元素
lpop-----删除头部元素
ltrim-----截取list(保留)
Set类型操作
sadd-----添加set
srem-----删除set中的指定元素
smove set1 set2-----将元素从set1转移到set2
scard-----返回set中元素的个数
sismember-----判断元素是否在set中
sinter set1 set2 set3...-----给所定set的交集
sunion
set1 set2 set3...-----给所定set的并集
sdiff set1 set2 set3...-----给所定set的差集
smembers-----返回set所对应的元素
Scort set
zadd-----添加
zrem--删除
zincrby (键 加值 元素) -----对set指定元素加值
zrank-----返回元素下标(按‘权’从小到大排列)
zrevrank-----返回元素下标(按‘权’从大到小排列)
zrange-----返回集合,(按‘权’从小到大排列)
zrevrange-----返回集合(按‘权’从大到小排列)
zcard-----返回集合元素个数zscorde-----返回给定元素的‘权’
zremrangebyrank-----删除集合指定区间的元素
使用命令fdisk -l查看当前磁盘的分区状态
df -lh(df -k或者df -m) 是来自于coreutils 软件包,系统安装时,就自带的;我们通过这个命令可以查看磁盘的使用情况以及文件系统被挂载的位置;
查询项目日志 : tail -f catalina.out
总结
Redis初始化会创建一批数据库,每个数据库的内部数据结构都是字典,key-value的最终存储也会落到字典上。
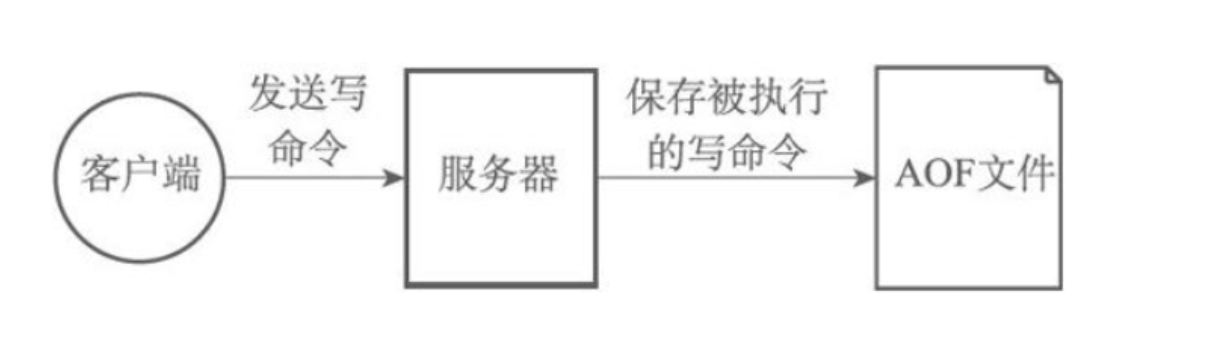
AOF持久化比RDB持久化频率更高、速度更快;当有AOF持久化时,RDB持久化命令不会再执行;但当RDB持久化命令执行时,AOF命令会等待其执行完成后再执行,而其他RDB命令不会执行。
AOF文件重写过程不会影响旧的AOF文件,即便AOF重写过程失败,也不会干扰原来的AOF恢复数据,只有在成功之后才会替换原来的文件。
RDB持久化是最直接的持久化方式,直接将内存中的数据保存到RDB文件中,当恢复时也是直接从RDB文件中恢复
1. redis 支持的 java 客户端都有哪些?
Redisson、Jedis、lettuce等等,官方推荐使用Redisson。
2. jedis 和 redisson 有哪些区别?
Jedis是Redis的Java实现的客户端,其API提供了比较全面的Redis命令的支持。
Redisson实现了分布式和可扩展的Java数据结构,和Jedis相比,功能较为简单,不支持字符串操作,不支持排序、事务、管道、分区等Redis特性。Redisson的宗旨是促进使用者对Redis的关注分离,从而让使用者能够将精力更集中地放在处理业务逻辑上。
3. 怎么保证缓存和数据库数据的一致性?
-
合理设置缓存的过期时间。
-
新增、更改、删除数据库操作时同步更新 Redis,可以使用事物机制来保证数据的一致性。
4. redis 持久化有几种方式?
Redis 的持久化有两种方式,或者说有两种策略:
-
RDB(Redis Database):指定的时间间隔能对你的数据进行快照存储。
-
AOF(Append Only File):每一个收到的写命令都通过write函数追加到文件中。
5. redis 怎么实现分布式锁?
Redis 分布式锁其实就是在系统里面占一个“坑”,其他程序也要占“坑”的时候,占用成功了就可以继续执行,失败了就只能放弃或稍后重试。
占坑一般使用 setnx(set if not exists)指令,只允许被一个程序占有,使用完调用 del 释放锁。
6. redis 分布式锁有什么缺陷?
Redis 分布式锁不能解决超时的问题,分布式锁有一个超时时间,程序的执行如果超出了锁的超时时间就会出现问题。
AOF