deployment控制器(pod副本控制器)
实现pod的水平扩展和收缩功能 遵循滚动更新的方式来升级现有的容器
deployment操作的不是pod对象 而是控制replicaSet对象通过它来间接控制Pod滚动更新
Deployment 同样通过"控制器模式",来操作 ReplicaSet 的个数和属性,进而实现“水平扩展 / 收缩”和“滚动更新”这两个编排动作
将一个集群中正在运行的多个Pod版本,交替地逐一升级的过程,就是"滚动更新"创建成功一个新的Pod后 再删除一个旧版本的Pod
如果创建新的pod没有正常运行起来 那么deployment控制器就不会删除旧的pod 中止滚动更新
Deployment实际上是一个两层控制器.首先,它通过ReplicaSet的个数来描述应用的版本.然后,它再通过ReplicaSet 的属性(比如replicas 的值)来保证Pod的副本数量
Deployment只允许容器的restartPolicy=Always
一个应用的所有Pod是完全一样的.所以,它们互相之间没有顺序也无所谓运行在哪台宿主机上
需要的时候Deployment就可以通过Pod模板创建新的Pod,不需要的时候Deployment就可以“杀掉”任意一个Pod
Deployment无法适用的场景
分布式应用,它的多个实例之间,往往有依赖关系,比如:主从关系/主备关系
数据存储类应用,它的多个实例,往往都会在本地磁盘上保存一份自己独立的数据 而这些实例一旦被杀掉,即便重建出来,实例与数据之间的对应关系也已经丢失
Deployment和ReplicaSet的关系

1. 一个定义了replicas=3的Deployment与它的ReplicaSet以及Pod的关系,实际上是一种“层层控制”的关系
2.ReplicaSet负责通过“控制器模式”保证系统中Pod的个数永远等于指定的个数(比如3个)
3.Deployment同样通过“控制器模式”来操作ReplicaSet的个数和属性,进而实现“水平扩展 / 收缩”和“滚动更新”这两个编排动作
DaemonSet控制器
在Kubernetes集群里的每一个节点(Node)上运行一个指定的Pod实例
跟其他编排对象不一样,DaemonSet开始运行的时机,很多时候比整个Kubernetes集群出现的时机都要早.
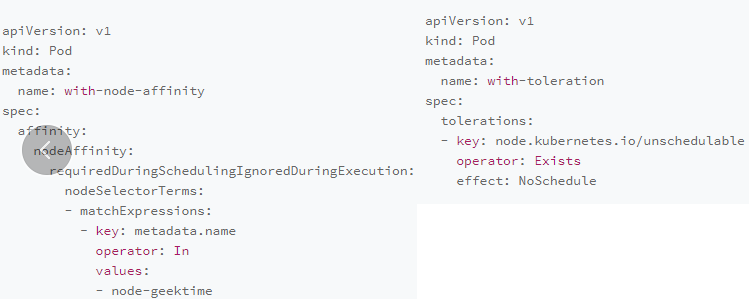
在集群中指定的节点(不是所有节点)创建Daemon Pod 通过spec.nodeAffinity字段来设置 nodeAffinity相当于是过滤不相关的节点
DaemonSet Controller会在创建Pod的时候,自动在Pod 的API对象里加上一个nodeAffinity定义.其中,需要绑定的节点名字正是当前正在遍历的这个节点
DaemonSet还会给这个Pod自动加上另外一个与调度相关的字段,叫作 tolerations.这个字段意味着这个Pod会“容忍”(Toleration)某些Node的“污点”(Taint)
相比于 Deployment,DaemonSet只管理Pod对象,然后通过 nodeAffinity 和Toleration 这两个调度器的小功能,保证了每个节点上有且只有一个 Pod
DaemonSet 使用 ControllerRevision,来保存和管理自己对应的“版本”.这种“面向API对象”的设计思路简化了控制器本身逻辑正是K8s“声明式 API”的优势
StatefulSet也是直接控制Pod对象的,那么它也在使用ControllerRevision 进行版本管理
在Kubernetes项目里ControllerRevision 其实是一个通用的版本管理对象
statefuset(有状态应用)控制器
把所有的有状态应用分为两种情况:
拓扑状态
应用的多个实例之间不是完全对等的关系.这些应用实例必须按照某些顺序启动,比如应用的主节点A要先于从节点B启动.而如果你把A和B两个Pod 删除掉,它们再次被创建出来时也必须严格按照这个顺序才行.并且新创建出来的 Pod,必须和原来Pod 的网络标识一样.这样原先的访问者才能使用同样的方法访问到这个新Pod
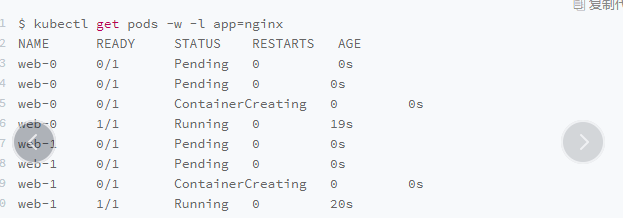
Pod 的创建,也是严格按照编号顺序进行的.比如,在 web-0 进入到 Running 状态、并且细分状态(Conditions)成为 Ready 之前web-1 会一直处于 Pending 状态
Kubernetes 就成功地将 Pod 的拓扑状态(比如:哪个节点先启动,哪个节点后启动),按照 Pod 的“名字 + 编号”的方式固定了下来.此外,Kubernetes 还为每一个 Pod 提供了一个固定并且唯一的访问入口,即:这个 Pod 对应的 DNS 记录。这些状态,在 StatefulSet 的整个生命周期里都会保持不变
存储状态
应用的多个实例分别绑定了不同的存储数据.对于这些应用实例来说,Pod A第一次读取到的数据和隔了十分钟之后再次读取到的数据应该是同一份
哪怕在此期间 Pod A 被重新创建过。这种情况最典型的例子,就是一个数据库应用的多个存储实例
PVC/PV 的设计 也使得 StatefulSet 对存储状态的管理成为了可能
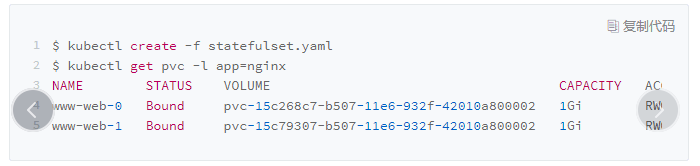
PVC都以"<PVC 名字 >-<StatefulSet 名字 >-< 编号 >"的方式命名并且处于 Bound 状态
StatefulSet管理的 Pod,都会声明一个对应的PVC;而这个PVC的定义,就来自于volumeClaimTemplates 这个模板字段。
更重要的是这个 PVC 的名字会被分配一个与这个 Pod 完全一致的编号
StatefulSet的滚动更新
StatefulSet Controller就会按照与Pod编号相反的顺序从最后一个 Pod 开始,逐一更新这个 StatefulSet 管理的每个 Pod.而如果更新发生了错误,这次“滚动更新”就会停止.此外,StatefulSet的“滚动更新”还允许我们进行更精细的控制,比如金丝雀发布(Canary Deploy)或者灰度发布,这意味着应用的多个实例中被指定的一部分不会被更新到最新的版本
service介绍
用来将一组Pod暴露给外部访问的一种机制
normal service
通过虚拟IP(vip)的方式把请求转发到所代理的某一个Pod上
通过service的DNS方式解析到vip(my-svc.my-namespace.svc.cluster.local)
headless service
clusterIP=None的service Headless Service 不需要分配一个VIP,而是可以直接以DNS记录的方式解析出被代理Pod的IP地址
创建了一个Headless Service之后,它所代理的所有Pod的IP 地址都会被绑定一个这样格式的DNS记录(podname.svcname.namespace.svc.cluster.local)
这个DNS记录 正是Kubernetes项目为Pod 分配的唯一的“可解析身份”(Resolvable Identity).有了这个“可解析身份”
只要你知道了一个Pod的名字以及它对应的 Service 的名字,你就可以非常确定地通过这条DNS记录访问到Pod的IP地址
statefuset的实现原理
StatefulSet 这个控制器的主要作用之一,就是使用 Pod 模板创建 Pod 的时候,对它们进行编号,并且按照编号顺序逐一完成创建工作
StatefulSet 的“控制循环”发现 Pod 的“实际状态”与“期望状态”不一致,需要新建或者删除 Pod 进行“调谐”的时候,它会严格按照这些 Pod 编号的顺序,逐一完成这些操作
与此同时,通过 Headless Service 的方式,StatefulSet 为每个 Pod 创建了一个固定并且稳定的 DNS 记录,来作为它的访问入口
在部署“有状态应用”的时候,应用的每个实例拥有唯一并且稳定的“网络标识”,是一个非常重要的假设
StatefulSet的控制器直接管理的是Pod
Kubernetes 通过 Headless Service,为这些有编号的 Pod,在 DNS 服务器中生成带有同样编号的DNS记录
StatefulSet 还为每一个 Pod 分配并创建一个同样编号的 PVC
StatefulSet 其实就是一种特殊的 Deployment,而其独特之处在于,它的每个 Pod 都被编号了.而且,这个编号会体现在Pod的名字和hostname等标识信息上,这不仅代表了 Pod 的创建顺序也是Pod的重要网络标识(即:在整个集群里唯一的、可被的访问身份).
有了这个编号后,StatefulSet 就使用 Kubernetes 里的两个标准功能:Headless Service 和 PV/PVC,实现了对 Pod 的拓扑状态和存储状态的维护
statefuset实现mysql集群
1.搭建好k8s集群
2.下载好镜像
docker pull gcr.io/google-samples/xtrabackup:1.0
docker pull mysql:5.7
3.创建好pv
使用nfs服务实现远程存储


vi /etc/exports /data/volumes/pv1 192.168.164.0/24(insecure,rw,async,no_root_squash) /data/volumes/pv2 192.168.164.0/24(insecure,rw,async,no_root_squash) /data/volumes/pv3 192.168.164.0/24(insecure,rw,async,no_root_squash)
kubectl apply -f pvs.yaml
apiVersion: v1 kind: PersistentVolume metadata: name: pv001 labels: name: pv001 spec: nfs: path: /data/volumes/pv1 server: 192.168.164.141 accessModes: ["ReadWriteMany","ReadWriteOnce"] capacity: storage: 20Gi --- apiVersion: v1 kind: PersistentVolume metadata: name: pv002 labels: name: pv002 spec: nfs: path: /data/volumes/pv2 server: 192.168.164.141 accessModes: ["ReadWriteMany","ReadWriteOnce"] capacity: storage: 10Gi --- apiVersion: v1 kind: PersistentVolume metadata: name: pv003 labels: name: pv003 spec: nfs: path: /data/volumes/pv3 server: 192.168.164.141 accessModes: ["ReadWriteMany","ReadWriteOnce"] capacity: storage: 10Gi

4.创建configmap
apiVersion: v1 kind: ConfigMap metadata: name: mysql labels: app: mysql data: master.cnf: | [mysqld] log-bin slave.cnf: | [mysqld] super-read-only
5.创建service
apiVersion: v1 kind: Service metadata: name: mysql labels: app: mysql spec: ports: - name: mysql port: 3306 clusterIP: None selector: app: mysql --- apiVersion: v1 kind: Service metadata: name: mysql-read labels: app: mysql spec: ports: - name: mysql port: 3306 selector: app: mysql
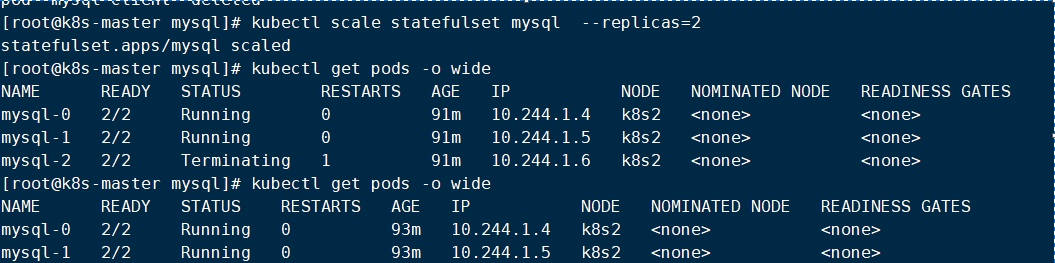
7.检测结果

总结: