索引的概念
索引是特殊数据结构: 定义在查找时作为查找条件的字段
索引实现在存储引擎
功能:
1.约束数据
2.加速查询
优点:
索引可以降低服务需要扫描的数据量,减少了IO次数
索引可以帮助服务器避免排序和使用临时表
索引可以帮助将随机I/O转为顺序I/O
缺点:
占用额外空间,影响插入速度
索引的查询方式
b+tree索引
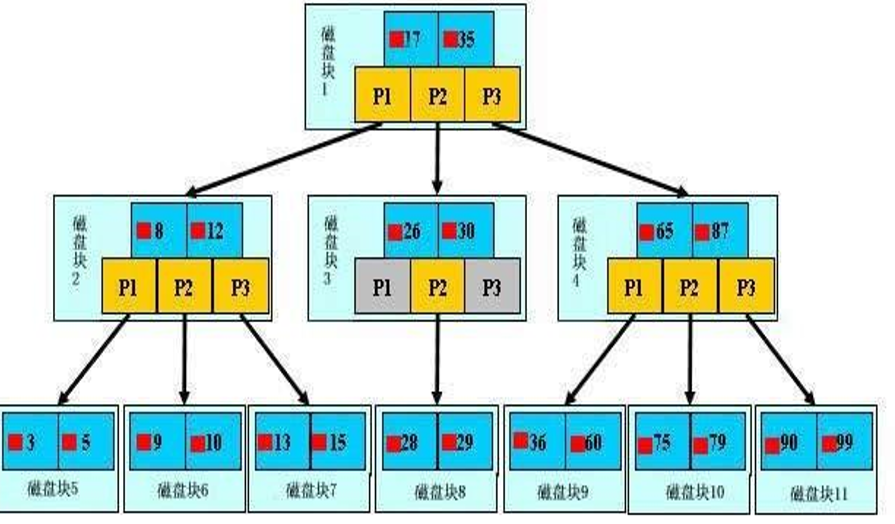
二叉树结构二分查找(按顺序存储) 在2的n次方的总记录数中,找到某条记录只需要n次查询即可
索引列的行数据最终都会在叶子页按顺序存储,节点页存储的是索引值的索引.非叶子节点只是为了方便算法寻找叶子节点
叶子节点比较特别,他们的指针指向的是被索引的数据,而不是其他的节点页(不同的引擎指针类型不同),其实在根节点与叶子节点之间可能有很多层节点页,树的深度和表的大小直接相关
btree树索引列是顺序组织存储的,所以很适合查找范围数据
创建索引 key(last_name,first_name,dob))
索引对多个值进行排序的依据是create table语句中定义索引时的列顺序
可以使用btree索引的查询类型,btree索引使用用于全键值、键值范围、或者键前缀查找,其中键前缀查找只适合用于根据最左前缀的查找。前面示例中创建的多列索引对如下类型的查询有效:
A:全值匹配
全值匹配指的是和索引中的所有列进行匹配,即可用于查找姓名和出生日期
B:匹配最左前缀
只查找姓,即只使用索引的第一列
C:匹配列前缀
可以只匹配某一列值的开头部分,如:匹配以J开头的姓的人,这里也只是使用了索引的第一列,且是第一列的一部分
D:匹配范围值
如查找姓在allen和barrymore之间的人,这里也只使用了索引的第一列
E:精确匹配某一列并范围匹配另外一列
如查找所有姓为allen,并且名字字母是K开头的,即,第一列last_name精确匹配,第二列first_name范围匹配
F:只访问索引的查询
btree通常可以支持只访问索引的查询,即查询只需要访问索引,而无需访问数据行,即,这个就是覆盖索引的概念。需要访问的数据直接从索引中取得。
索引排序
因为索引树中的节点是有序的,所以除了按值查找之外,索引还可以用于查询中的order by操作,一般来说,如果btree可以按照某种方式查找的值,那么也可以按照这种方式用于排序
所以,如果order by子句满足前面列出的几种查询类型,则这个索引也可以满足对应的排序需求
btree索引的使用限制
A:如果不是按照索引的最左列开始查找的,则无法使用索引(注意,这里不是指的where条件的顺序,即where条件中,不管条件顺序,只要where中出现的列在多列索引中能够从最左开始连贯起来就能使用到多列索引)
B:不能跳过索引中的列,如:查询条件为姓和出生日期,跳过了名字列,这样,多列索引就只能使用到姓这一列
C:如果查询中有某个列的范围查询,则其右边所有列都无法使用索引优化查询,如:where last_name=xxx and first_name like ‘xxx%’ and dob=’xxx’;这样,first_name列可 以使用索引,这列之后的dob列无法使用索引。
hash索引
基于哈希表实现,只有精确匹配索引所有列的查询才有效,对于每一行数据,存储引擎都会对所有的索引列的值计算一个哈希码,哈希码是一个较小的值,并且不同键值的行计算出来的哈希码不一样,哈希索引将所有的哈希码存储在索引中,同时在哈希表中保存指向每个数据行的指针。
mysql> select * from testhash;
A:哈希索引只包含哈希值和行指针,而不存储字段值,所以不能使用索引中的值来避免读取行(即不能使用哈希索引来做覆盖索引扫描),不过,访问内存中的行的速度很快 (因为memory引擎的数据都保存在内存里),所以大部分情况下这一点对性能的影响并不明显。
B:哈希索引数据并不是按照索引列的值顺序存储的,所以也就无法用于排序
C:哈希索引也不支持部分索引列匹配查找,因为哈希索引始终是使用索引的全部列值内容来计算哈希值的.如:数据列(a,b)上建立哈希索引,如果只查询数据列a,则无法使用该索引
D:哈希索引只支持等值比较查询,如:=,in(),<=>(注意,<>和<=>是不同的操作),不支持任何范围查询(必须给定具体的where条件值来计算hash值,所以不支持范围查询)
索引的种类
普通索引
加速查询速度
主键索引
加速查找 + 不能为空 + 不能重复
唯一索引
加速查找 + 不能重复
组合索引(多列组成一个索引)
组合索引的效率要高于索引合并
1.联合主键索引
2.联合唯一索引
3.联合普通索引
全文索引
给整个数据库创建索引表
覆盖索引
id是一个主键索引
查询的数据直接从索引文件中就可以获取无需再次到表中读取数据
select id from testdata where id=10000;
索引合并
name 是一个普通索引
id 是一个主键索引
在过滤条件的时候组合使用了多个单列索引
select * from testdata where id=999 and name="aaa"