错误信息
19/01/15 19:36:40 WARN consumer.ConsumerConfig: The configuration max.poll.records = 1 was supplied but isn't a known config. 19/01/15 19:36:40 INFO utils.AppInfoParser: Kafka version : 0.9.0-kafka-2.0.2 19/01/15 19:36:40 INFO utils.AppInfoParser: Kafka commitId : unknown 19/01/15 19:36:40 ERROR streaming.StreamExecution: Query queryMyBatchTopicData [id = 25b0620e-20b5-4efe-babb-dda94ef3ccc6, runId = 013d0674-23f7-4ebe-a5fb-84c8699ea1b9] terminated with error java.lang.NoSuchMethodError: org.apache.kafka.clients.consumer.KafkaConsumer.subscribe(Ljava/util/Collection;)V at org.apache.spark.sql.kafka010.SubscribeStrategy.createConsumer(ConsumerStrategy.scala:63) at org.apache.spark.sql.kafka010.KafkaOffsetReader.createConsumer(KafkaOffsetReader.scala:297) at org.apache.spark.sql.kafka010.KafkaOffsetReader.<init>(KafkaOffsetReader.scala:78) at org.apache.spark.sql.kafka010.KafkaSourceProvider.createSource(KafkaSourceProvider.scala:88) at org.apache.spark.sql.execution.datasources.DataSource.createSource(DataSource.scala:243) at org.apache.spark.sql.execution.streaming.StreamExecution$$anonfun$2$$anonfun$applyOrElse$1.apply(StreamExecution.scala:158) at org.apache.spark.sql.execution.streaming.StreamExecution$$anonfun$2$$anonfun$applyOrElse$1.apply(StreamExecution.scala:155) at scala.collection.mutable.MapLike$class.getOrElseUpdate(MapLike.scala:194) at scala.collection.mutable.AbstractMap.getOrElseUpdate(Map.scala:80) at org.apache.spark.sql.execution.streaming.StreamExecution$$anonfun$2.applyOrElse(StreamExecution.scala:155) at org.apache.spark.sql.execution.streaming.StreamExecution$$anonfun$2.applyOrElse(StreamExecution.scala:153) at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$2.apply(TreeNode.scala:267) at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$2.apply(TreeNode.scala:267) at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:70) at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:266) at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$transformDown$1.apply(TreeNode.scala:272) at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$transformDown$1.apply(TreeNode.scala:272) at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$4.apply(TreeNode.scala:306) at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:187)
原因分析
其实这个在官方文档中有介绍。地址如下:https://www.cloudera.com/documentation/spark2/latest/topics/spark2_kafka.html#running_jobs
方案一:错误信息中可以看出kafka的版本:Kafka version : 0.9.0-kafka-2.0.2,而我在pom.xml中应用的jar是0.10,因此导致包不一致。直接修改pom.xml对应jar版本号即可。
# Set the environment variable for the duration of your shell session: export SPARK_KAFKA_VERSION=0.10 spark-submit arguments # Or: # Set the environment variable for the duration of a single command: SPARK_KAFKA_VERSION=0.10 spark-submit arguments
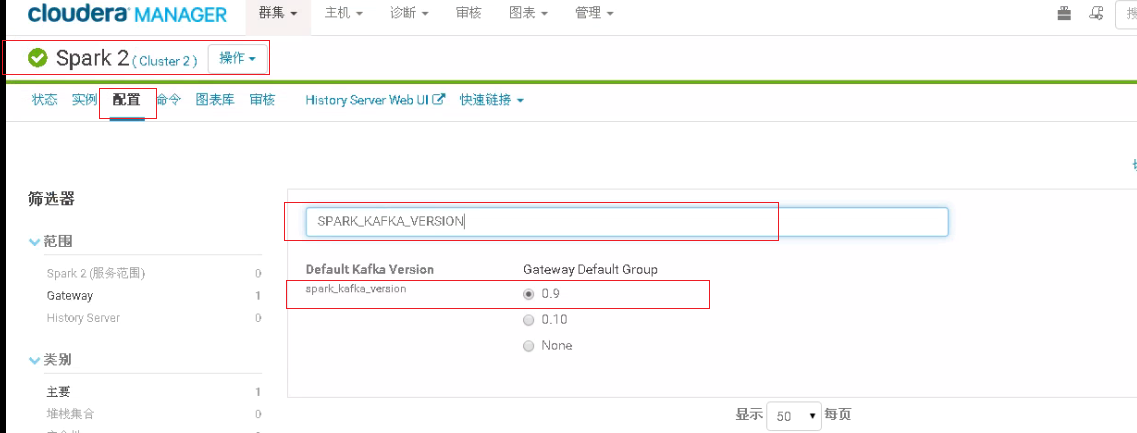
方案二:就是kafka集成spark2,需要在CDH中进行设置。进入CDH的spark2配置界面,在搜索框中输入SPARK_KAFKA_VERSION,出现如下图,然后选择对应版本,这里我应该选择的是0.10,然后保存配置,重启生效。重新跑sparkstreaming任务,问题解决。