如何搭建配置centos虚拟机请参考《Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网。》
如何安装hadoop2.9.0请参考《Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二)安装hadoop2.9.0》
如何配置zookeeper3.4.12 请参考《Kafka:ZK+Kafka+Spark Streaming集群环境搭建(八)安装zookeeper-3.4.12》
安装hadoop的服务器:
192.168.0.120 master 192.168.0.121 slave1 192.168.0.122 slave2 192.168.0.123 slave3
前言:
配置高可用(HA)集群在实际生产中可保证集群安全稳定高效的运行,下面讲解一下HA中的各个节点的作用。
1,zookeeper的java进程:QuorumPeermain,各种分布式服务(如hdfs,hbase,resourcemanager)注册到zookeeper上去,即可启动2个以上的相同进程(其中一个状态为active,其他为standby),那么,其中active节点挂了,可通过zookeeper进行切换到standby,让他active,保证进程正常运行。
2,namenode:hdfs的主节点,保存hdfs正常运行的各种必要元数据(保存在edits和fsimage文件中),万一挂了,整个集群就挂了,所以要配置多namenode。
3,datanode:hdfs的数据节点,保存真实数据的节点。
4,journalnode:日志节点,将namenode上的edits文件分离出来,弄成一个集群,保证namenode不被挂。
5,zkfc:全称DFSZKFailoverController,监控并管理namenode的状态和切换。
6,Resourcemanager:管理并分配集群的资源,如为nodemanager分配计算资源等。
7,nodemanager:管理datanode,并随datanode的启动而启动。

其实,最好每个节点跑一个进程,奈何机器性能不足,跑不了那么多虚拟机,就将几个节点放在同一个节点上,只将重要的进程(namenode和resourcemanager)放在不同的节点。
搭建集群前的工作:
首先是系统环境:
如何搭建配置centos虚拟机请参考《Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网。》
如何安装hadoop2.9.0请参考《Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二)安装hadoop2.9.0》
然后搭建zookeeper3.4.12请参考《Kafka:ZK+Kafka+Spark Streaming集群环境搭建(八)安装zookeeper-3.4.12》
三,修改配置文件
先在master节点上修改配置文件,然后传到其他节点。
1)停掉hadoop服务并清除slaves上hadoop安装目录
master上:关闭hadoop服务,并清除dfs、logs、tmp目录
cd /opt/hadoop-2.9.0 sbin/stop-all.sh rm -r dfs rm -r logs rm -r tmp
slaves上:关闭hadoop服务,清除hadoop安装目录
cd /opt/hadoop-2.9.0 sbin/stop-all.sh rm -r *
2)etc/hadoop/hadoop-env.sh
cd /opt/hadoop-2.9.0/etc/hadoop vi hadoop-env.sh export JAVA_HOME = path_to_jdk #添加配置
3)core-site.xml修改
cd /opt/hadoop-2.9.0/etc/hadoop vi core-site.xml <configuration> <!-- 指定hdfs的nameservice为ns1 --> <property> <name>fs.defaultFS</name> <!-- <value>hdfs://master:9000/</value>--> <value>hdfs://HA</value> </property> <!-- 指定hadoop临时目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop-2.9.0/tmp</value> <description>这里的路径默认是NameNode、DataNode、JournalNode等存放数据的公共目录</description> </property> <property> <name>io.file.buffer.size</name> <value>131702</value> </property> <!-- 指定zookeeper地址 --> <property> <name>ha.zookeeper.quorum</name> <value>master:2181,slave1:2181,slave2:2181</value> <description>这里是ZooKeeper集群的地址和端口。注意,数量一定是奇数,且不少于三个节点</description> </property> <!-- 下面的配置可解决NameNode连接JournalNode超时异常问题--> <property> <name>ipc.client.connect.retry.interval</name> <value>10000</value> <description>Indicates the number of milliseconds a client will wait for before retrying to establish a server connection. </description> </property> </configuration>
4)hdfs-site.xml修改
cd /opt/hadoop-2.9.0/etc/hadoop vi hdfs-site.xml <configuration> <!--指定hdfs的nameservice为HA,需要和core-site.xml中的保持一致 --> <property> <name>dfs.nameservices</name> <value>HA</value> </property> <!-- HA下面有两个NameNode,分别是nn1,nn2 --> <property> <name>dfs.ha.namenodes.HA</name> <value>nn1,nn2</value> </property> <!-- nn1的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.HA.nn1</name> <value>master:9000</value> <description>9000为HDFS 客户端接入地址(包括命令行与程序),有的使用8020</description> </property> <!-- nn1的http通信地址 --> <property> <name>dfs.namenode.http-address.HA.nn1</name> <value>master:50070</value> <description> namenode web的接入地址</description> </property> <!-- nn2的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.HA.nn2</name> <value>slave1:9000</value> <description>9000为HDFS 客户端接入地址(包括命令行与程序),有的使用8020</description> </property> <!-- nn2的http通信地址 --> <property> <name>dfs.namenode.http-address.HA.nn2</name> <value>slave1:50070</value> <description> namenode web的接入地址</description> </property> <!-- 指定NameNode的edits元数据在JournalNode上的存放位置 --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://master:8485;slave1:8485;slave2:8485/HA</value> <description>指定 nn1 的两个NameNode共享edits文件目录时,使用的JournalNode集群信息。masterslave1主机中使用这个配置</description> </property> <!-- 指定JournalNode在本地磁盘存放数据的位置 --> <property> <name>dfs.journalnode.edits.dir</name> <value>/opt/hadoop-2.9.0/tmp/journal</value> </property> <!-- 开启NameNode失败自动切换 --> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <!-- 配置失败自动切换实现方式 --> <property> <name>dfs.client.failover.proxy.provider.HA</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行--> <property> <name>dfs.ha.fencing.methods</name> <value> sshfence shell(/bin/true) </value> </property> <!-- 使用sshfence隔离机制时需要ssh免登陆 --> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/spark/.ssh/id_rsa</value> <description> [spark@master hadoop]$ cd /home/spark/.ssh/ [spark@master .ssh]$ ls authorized_keys id_rsa.pub id_rsa.pub.slave2 known_hosts id_rsa id_rsa.pub.slave1 id_rsa.pub.slave3 </description> </property> <!-- 配置sshfence隔离机制超时时间 --> <property> <name>dfs.ha.fencing.ssh.connect-timeout</name> <value>30000</value> </property> <!-- <property> <name>dfs.namenode.secondary.http-address</name> <value>master:9001</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/opt/hadoop-2.9.0/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/opt/hadoop-2.9.0/dfs/data</value> </property> --> <property> <name>dfs.replication</name> <value>3</value> <description>指定DataNode存储block的副本数量。默认值是3个,我们现在有4个DataNode,该值不大于4即可</description> </property> <property> <name>dfs.blocksize</name> <value>134217728</value> <description> The default block size for new files, in bytes. You can use the following suffix (case insensitive): k(kilo), m(mega), g(giga), t(tera), p(peta), e(exa) to specify the size (such as 128k, 512m, 1g, etc.), Or provide complete size in bytes (such as 134217728 for 128 MB). 注:1.X及以前版本默认是64M,而且配置项名为dfs.block.size </description> </property> <property> <name>dfs.permissions.enabled</name> <value>false</value> <description>注:如果还有权限问题,请执行下“/opt/hadoop-2.9.0/bin/hdfs dfs -chmod -R 777 /”命令</description> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration>
注意:这里可能出现问题:The ratio of reported blocks 1.0000 has reached the threshold 0.9990. Safe mode will be turned off automatically in 27 seconds.
原因:
hadoop默认情况下在安全模式运行。可以通过下面hadoop dfsadmin -safemode 参数,查看相关的状态和设置安全模块是否启用。
enter 进入安全模式
leave 强制NameNode离开安全模式
get 返回安全模式是否开启的信息
wait 等待,一直到安全模式结束。
解决办法有二种:
《1》可能运行命令hadoop dfsadmin -safemode leave 离开安全模式,但是每次都需要手动去设置。
《2》通过配置dfs.safemode.threshold.pct的参数。默认情况下是0.9990f。这个配置可以在hdfs-defalut.xml中找到。我们可以把这个参数配置为0,永久关闭安全模式。
在hadoop中的hdfs-site.xml添加如下配置:
<property> <name>dfs.safemode.threshold.pct</name> <value>0f</value> <description> Specifies the percentage of blocks that should satisfy the minimal replication requirement defined by dfs.replication.min. Values less than or equal to 0 mean not to wait for any particular percentage of blocks before exiting safemode. Values greater than 1 will make safe mode permanent. </description> </property>
重启NameNode就可以了。
5)mapred-site.xml 修改
cd /opt/hadoop-2.9.0/etc/hadoop vi mapred-site.xml <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobtracker.http.address</name> <value>master:50030</value> <description>注:每台机器上配置都不一样,需要修改成对应的主机名,端口不用修改,比如 slave1:50030 slave2:50030 slave3:50030 ,拷贝过去后请做相应修改</description> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> <description>注:每台机器上配置都不一样,需要修改成对应的主机名,端口不用修改,比如 slave1:10020、 slave2:10020、 slave3:10020 ,拷贝过去后请做相应修改</description> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> <description>注:每台机器上配置都不一样,需要修改成对应的主机名,端口不用修改,比如 slave1:19888、 slave2:19888、 slave3:19888 ,拷贝过去后请做相应修改</description> </property> <property> <name>mapred.job.tracker</name> <value>http://master:9001</value> <description>注:每台机器上配置都不一样,需要修改成对应的主机名,端口不用修改,比如 http://slave1:9001 、 http://slave2:9001 、 http://slave3:9001 ,拷贝过去后请做相应修改</description> </property> </configuration>
6)yarn-site.xml 修改
cd /opt/hadoop-2.9.0/etc/hadoop vi yarn-site.xml <configuration> <!-- <property> <name>yarn.resourcemanager.address</name> <value>master:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8035</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>master:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>master:8088</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>2048</value> </property> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> <description>Whether virtual memory limits will be enforced for containers</description> </property> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>4</value> <description>Ratio between virtual memory to physical memory when setting memory limits for containers</description> </property> --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <!-- 开启RM高可用 --> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!-- 指定RM的cluster id --> <property> <name>yarn.resourcemanager.cluster-id</name> <value>yarn-cluster</value> </property> <!-- 分别指定RM的地址 --> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>master</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>slave1</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>master:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>slave1:8088</value> </property> <!-- 指定zk集群地址 --> <property> <name>yarn.resourcemanager.zk-address</name> <value>master:2181,slave1:2181,slave2:2181</value> </property> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> <description>RM的数据默认存放在ZK上的/rmstore中,可通过yarn.resourcemanager.zk-state-store.parent-path 设定</description> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> <description>开启日志收集,这样会将每台执行任务的机上产生的本地日志文件集中拷贝到HDFS的某个地方,这样就可以在任何一台集群中的机器上集中查看作业日志了</description> </property> <property> <name>yarn.log.server.url</name> <value>http://master:19888/jobhistory/logs</value> <description>注:每台机器上配置都不一样,需要修改成对应的主机名,端口不用修改,比如http://slave1:19888/jobhistory/logs、http://slave2:19888/jobhistory/logs、http://slave3:19888/jobhistory/logs,拷贝过去后请做相应修改</description> </property> </configuration>
7) slaves 修改
cd /opt/hadoop-2.9.0/etc/hadoop vi slaves [spark@master hadoop]$ more slaves #localhost slave1 slave2 slave3
8)配置好后,将配置文件传到其他节点上
scp -r /opt/hadoop-2.9.0 spark@slave1:/opt/ scp -r /opt/hadoop-2.9.0 spark@slave2:/opt/ scp -r /opt/hadoop-2.9.0 spark@slave3:/opt/
分别在slave1,slave2,slave3上修改配置:
修改yarn-site.xml
cd /opt/hadoop-2.9.0/etc/hadoop vi yarn-site.xml
修改内容
<property> <name>yarn.log.server.url</name> <value>http://master:19888/jobhistory/logs</value> <description>注:每台机器上配置都不一样,需要修改成对应的主机名,端口不用修改,比如http://slave1:19888/jobhistory/logs、http://slave2:19888/jobhistory/logs、http://slave3:19888/jobhistory/logs,拷 贝过去后请做相应修改</description> </property>
修改mapred-site.xml
cd /opt/hadoop-2.9.0 vi mapred-site.xml
修改内容
<configuration> <property> <name>mapreduce.jobtracker.http.address</name> <value>master:50030</value> <description>注:每台机器上配置都不一样,需要修改成对应的主机名,端口不用修改,比如 slave1:50030 slave2:50030 slave3:50030 ,拷贝过去后请做相应修改</description> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> <description>注:每台机器上配置都不一样,需要修改成对应的主机名,端口不用修改,比如 slave1:10020、 slave2:10020、 slave3:10020 ,拷贝过去后请做相应修改</description> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> <description>注:每台机器上配置都不一样,需要修改成对应的主机名,端口不用修改,比如 slave1:19888、 slave2:19888、 slave3:19888 ,拷贝过去后请做相应修改</description> </property> <property> <name>mapred.job.tracker</name> <value>http://master:9001</value> <description>注:每台机器上配置都不一样,需要修改成对应的主机名,端口不用修改,比如 http://slave1:9001 、 http://slave2:9001 、 http://slave3:9001 ,拷贝过去后请做相应修改</description> </property> </configuration>
初始化集群,严格按照一下步骤!
1,在3台节点(master,slave1,slave2)启动zookeeper集群,jps查看有没有启动。
cd /opt/zookeeper-3.4.12/bin ./zkServer.sh start ./zkServer.sh status
master
[spark@master hadoop-2.9.0]$ cd /opt/zookeeper-3.4.12/bin [spark@master bin]$ ./zkServer.sh start ZooKeeper JMX enabled by default Using config: /opt/zookeeper-3.4.12/bin/../conf/zoo.cfg Starting zookeeper ... STARTED [spark@master bin]$ [spark@master bin]$ ./zkServer.sh status ZooKeeper JMX enabled by default Using config: /opt/zookeeper-3.4.12/bin/../conf/zoo.cfg Mode: follower
slave1
[spark@slave1 hadoop]$ cd /opt/zookeeper-3.4.12/bin [spark@slave1 bin]$ ./zkServer.sh start ZooKeeper JMX enabled by default Using config: /opt/zookeeper-3.4.12/bin/../conf/zoo.cfg ./zkServer.sh status Starting zookeeper ... STARTED [spark@slave1 bin]$ [spark@slave1 bin]$ ./zkServer.sh status ZooKeeper JMX enabled by default Using config: /opt/zookeeper-3.4.12/bin/../conf/zoo.cfg Mode: leader
slave2
[spark@slave2 hadoop]$ cd /opt/zookeeper-3.4.12/bin [spark@slave2 bin]$ ./zkServer.sh start ZooKeeper JMX enabled by default Using config: /opt/zookeeper-3.4.12/bin/../conf/zoo.cfg Starting zookeeper ... ./zkServer.sh status STARTED [spark@slave2 bin]$ [spark@slave2 bin]$ ./zkServer.sh status ZooKeeper JMX enabled by default Using config: /opt/zookeeper-3.4.12/bin/../conf/zoo.cfg Mode: follower
2,在3台节点(master,slave1,slave2)启动journalnode集群,jps查看有没有启动。
cd /opt/hadoop-2.9.0 sbin/hadoop-daemon.sh start journalnode
master
[spark@master hadoop]$ cd /opt/hadoop-2.9.0 [spark@master hadoop-2.9.0]$ sbin/hadoop-deamon.sh start journalnode starting journalnode, logging to /opt/hadoop-2.9.0/logs/hadoop-spark-journalnode-master.out [spark@master hadoop-2.9.0]$ jps 1808 Jps 1757 JournalNode 1662 QuorumPeerMain [spark@master hadoop-2.9.0]$
slave1
[spark@slave1 bin]$ cd /opt/hadoop-2.9.0 [spark@slave1 hadoop-2.9.0]$ sbin/hadoop-daemon.sh start journalnode starting journalnode, logging to /opt/hadoop-2.9.0/logs/hadoop-spark-journalnode-slave1.out [spark@slave1 hadoop-2.9.0]$ jps 2003 JournalNode 2054 Jps 1931 QuorumPeerMain [spark@slave1 hadoop-2.9.0]$
slave2
[spark@slave2 bin]$ cd /opt/hadoop-2.9.0 [spark@slave2 hadoop-2.9.0]$ sbin/hadoop-daemon.sh start journalnode starting journalnode, logging to /opt/hadoop-2.9.0/logs/hadoop-spark-journalnode-slave2.out [spark@slave2 hadoop-2.9.0]$ jps 1978 QuorumPeerMain 2044 JournalNode 2095 Jps [spark@slave2 hadoop-2.9.0]$
3,在 master 上格式化hdfs
cd /opt/hadoop-2.9.0 bin/hdfs namenode -format #等同 bin/hadoop namenode -format [spark@master HA]$ cd /opt/hadoop-2.9.0 [spark@master hadoop-2.9.0]$ bin/hdfs namenode -format 18/07/01 22:26:11 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = master/192.168.0.120 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.9.0 STARTUP_MSG: classpath = /opt/hadoop-2.9.0/etc/hadoop:/opt/hadoop-2.9.0/share/hadoop/common/lib/nimbus-jose-jwt-3.9.jar:/opt/hadoop-2.9.0/share/hadoop/common/li.... STARTUP_MSG: build = https://git-wip-us.apache.org/repos/asf/hadoop.git -r 756ebc8394e473ac25feac05fa493f6d612e6c50; compiled by 'arsuresh' on 2017-11-13T23:15Z STARTUP_MSG: java = 1.8.0_171 ************************************************************/ 18/07/01 22:26:11 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT] 18/07/01 22:26:11 INFO namenode.NameNode: createNameNode [-format] Formatting using clusterid: CID-01f8ecdf-532b-4415-807e-90b4aa179e29 18/07/01 22:26:12 INFO namenode.FSEditLog: Edit logging is async:true 18/07/01 22:26:12 INFO namenode.FSNamesystem: KeyProvider: null 18/07/01 22:26:12 INFO namenode.FSNamesystem: fsLock is fair: true 18/07/01 22:26:12 INFO namenode.FSNamesystem: Detailed lock hold time metrics enabled: false 18/07/01 22:26:12 INFO namenode.FSNamesystem: fsOwner = spark (auth:SIMPLE) 18/07/01 22:26:12 INFO namenode.FSNamesystem: supergroup = supergroup 18/07/01 22:26:12 INFO namenode.FSNamesystem: isPermissionEnabled = false 18/07/01 22:26:12 INFO namenode.FSNamesystem: Determined nameservice ID: HA 18/07/01 22:26:12 INFO namenode.FSNamesystem: HA Enabled: true 18/07/01 22:26:12 INFO common.Util: dfs.datanode.fileio.profiling.sampling.percentage set to 0. Disabling file IO profiling 18/07/01 22:26:12 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit: configured=1000, counted=60, effected=1000 18/07/01 22:26:12 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true 18/07/01 22:26:12 INFO blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to 000:00:00:00.000 18/07/01 22:26:12 INFO blockmanagement.BlockManager: The block deletion will start around 2018 Jul 01 22:26:12 18/07/01 22:26:12 INFO util.GSet: Computing capacity for map BlocksMap 18/07/01 22:26:12 INFO util.GSet: VM type = 64-bit 18/07/01 22:26:12 INFO util.GSet: 2.0% max memory 966.7 MB = 19.3 MB 18/07/01 22:26:12 INFO util.GSet: capacity = 2^21 = 2097152 entries 18/07/01 22:26:12 INFO blockmanagement.BlockManager: dfs.block.access.token.enable=false 18/07/01 22:26:12 WARN conf.Configuration: No unit for dfs.namenode.safemode.extension(30000) assuming MILLISECONDS 18/07/01 22:26:12 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.threshold-pct = 0.9990000128746033 18/07/01 22:26:12 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.min.datanodes = 0 18/07/01 22:26:12 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.extension = 30000 18/07/01 22:26:12 INFO blockmanagement.BlockManager: defaultReplication = 3 18/07/01 22:26:12 INFO blockmanagement.BlockManager: maxReplication = 512 18/07/01 22:26:12 INFO blockmanagement.BlockManager: minReplication = 1 18/07/01 22:26:12 INFO blockmanagement.BlockManager: maxReplicationStreams = 2 18/07/01 22:26:12 INFO blockmanagement.BlockManager: replicationRecheckInterval = 3000 18/07/01 22:26:12 INFO blockmanagement.BlockManager: encryptDataTransfer = false 18/07/01 22:26:12 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000 18/07/01 22:26:12 INFO namenode.FSNamesystem: Append Enabled: true 18/07/01 22:26:12 INFO util.GSet: Computing capacity for map INodeMap 18/07/01 22:26:12 INFO util.GSet: VM type = 64-bit 18/07/01 22:26:12 INFO util.GSet: 1.0% max memory 966.7 MB = 9.7 MB 18/07/01 22:26:12 INFO util.GSet: capacity = 2^20 = 1048576 entries 18/07/01 22:26:12 INFO namenode.FSDirectory: ACLs enabled? false 18/07/01 22:26:12 INFO namenode.FSDirectory: XAttrs enabled? true 18/07/01 22:26:12 INFO namenode.NameNode: Caching file names occurring more than 10 times 18/07/01 22:26:12 INFO snapshot.SnapshotManager: Loaded config captureOpenFiles: falseskipCaptureAccessTimeOnlyChange: false 18/07/01 22:26:12 INFO util.GSet: Computing capacity for map cachedBlocks 18/07/01 22:26:12 INFO util.GSet: VM type = 64-bit 18/07/01 22:26:12 INFO util.GSet: 0.25% max memory 966.7 MB = 2.4 MB 18/07/01 22:26:12 INFO util.GSet: capacity = 2^18 = 262144 entries 18/07/01 22:26:12 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10 18/07/01 22:26:12 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10 18/07/01 22:26:12 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25 18/07/01 22:26:12 INFO namenode.FSNamesystem: Retry cache on namenode is enabled 18/07/01 22:26:12 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis 18/07/01 22:26:12 INFO util.GSet: Computing capacity for map NameNodeRetryCache 18/07/01 22:26:12 INFO util.GSet: VM type = 64-bit 18/07/01 22:26:12 INFO util.GSet: 0.029999999329447746% max memory 966.7 MB = 297.0 KB 18/07/01 22:26:12 INFO util.GSet: capacity = 2^15 = 32768 entries Re-format filesystem in Storage Directory /opt/hadoop-2.9.0/tmp/dfs/name ? (Y or N) y Re-format filesystem in QJM to [192.168.0.120:8485, 192.168.0.121:8485, 192.168.0.122:8485] ? (Y or N) y 18/07/01 22:26:19 INFO namenode.FSImage: Allocated new BlockPoolId: BP-4950294-192.168.0.120-1530455179314 18/07/01 22:26:19 INFO common.Storage: Will remove files: [/opt/hadoop-2.9.0/tmp/dfs/name/current/VERSION, /opt/hadoop-2.9.0/tmp/dfs/name/current/seen_txid] 18/07/01 22:26:19 INFO common.Storage: Storage directory /opt/hadoop-2.9.0/tmp/dfs/name has been successfully formatted. 18/07/01 22:26:19 INFO namenode.FSImageFormatProtobuf: Saving image file /opt/hadoop-2.9.0/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression 18/07/01 22:26:19 INFO namenode.FSImageFormatProtobuf: Image file /opt/hadoop-2.9.0/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 322 bytes saved in 0 seconds. 18/07/01 22:26:19 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 18/07/01 22:26:19 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at master/192.168.0.120 ************************************************************/
4,配置 slave1 上的namenode
先在 master 上启动namenode
cd /opt/hadoop-2.9.0 sbin/hadoop-daemon.sh start namenode [spark@master hadoop-2.9.0]$ cd /opt/hadoop-2.9.0 [spark@master hadoop-2.9.0]$ sbin/hadoop-daemon.sh start namenode starting namenode, logging to /opt/hadoop-2.9.0/logs/hadoop-spark-namenode-master.out [spark@master hadoop-2.9.0]$ jps 2016 Jps 1939 NameNode 1757 JournalNode 1662 QuorumPeerMain [spark@master hadoop-2.9.0]$
再在 slave1 上执行命令:
cd /opt/hadoop-2.9.0 bin/hdfs namenode -bootstrapStandby [spark@slave1 HA]$ cd /opt/hadoop-2.9.0 [spark@slave1 hadoop-2.9.0]$ bin/hdfs namenode -bootstrapStandby 18/07/01 22:28:58 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = slave1/192.168.0.121 STARTUP_MSG: args = [-bootstrapStandby] STARTUP_MSG: version = 2.9.0 STARTUP_MSG: classpath = /opt/hadoop-2.9.0/etc/hadoop:/opt/hadoop-2.9.0/share/hadoop/common/lib... STARTUP_MSG: build = https://git-wip-us.apache.org/repos/asf/hadoop.git -r 756ebc8394e473ac25feac05fa493f6d612e6c50; compiled by 'arsuresh' on 2017-11-13T23:15Z STARTUP_MSG: java = 1.8.0_171 ************************************************************/ 18/07/01 22:28:58 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT] 18/07/01 22:28:58 INFO namenode.NameNode: createNameNode [-bootstrapStandby] ===================================================== About to bootstrap Standby ID nn2 from: Nameservice ID: HA Other Namenode ID: nn1 Other NN's HTTP address: http://master:50070 Other NN's IPC address: master/192.168.0.120:9000 Namespace ID: 1875840257 Block pool ID: BP-4950294-192.168.0.120-1530455179314 Cluster ID: CID-01f8ecdf-532b-4415-807e-90b4aa179e29 Layout version: -63 isUpgradeFinalized: true ===================================================== 18/07/01 22:28:59 INFO common.Storage: Storage directory /opt/hadoop-2.9.0/tmp/dfs/name has been successfully formatted. 18/07/01 22:28:59 INFO namenode.FSEditLog: Edit logging is async:true 18/07/01 22:29:00 INFO namenode.TransferFsImage: Opening connection to http://master:50070/imagetransfer?getimage=1&txid=0&storageInfo=-63:1875840257:1530455179314:CID-01f8ecdf-532b-4415-807e-90b4aa179e29&bootstrapstandby=true 18/07/01 22:29:00 INFO namenode.TransferFsImage: Image Transfer timeout configured to 60000 milliseconds 18/07/01 22:29:00 INFO namenode.TransferFsImage: Combined time for fsimage download and fsync to all disks took 0.02s. The fsimage download took 0.01s at 0.00 KB/s. Synchronous (fsync) write to disk of /opt/hadoop-2.9.0/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 took 0.00s. 18/07/01 22:29:00 INFO namenode.TransferFsImage: Downloaded file fsimage.ckpt_0000000000000000000 size 322 bytes. 18/07/01 22:29:00 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at slave1/192.168.0.121 ************************************************************/
5,格式化ZKFC(在 master 上执行一次即可)
cd /opt/hadoop-2.9.0 bin/hdfs zkfc -formatZK [spark@master hadoop-2.9.0]$ cd /opt/hadoop-2.9.0 [spark@master hadoop-2.9.0]$ bin/hdfs zkfc -formatZK 18/07/01 22:31:25 INFO tools.DFSZKFailoverController: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting DFSZKFailoverController STARTUP_MSG: host = master/192.168.0.120 STARTUP_MSG: args = [-formatZK] STARTUP_MSG: version = 2.9.0 STARTUP_MSG: classpath = /opt/hadoop-2.9.0/etc/hadoop:/opt/hadoop-2.9.0/share/hadoop/common/lib/nimbus-jose-jwt-3.9.jar:/opt/hadoop-2.9.0/share/hadoop/common/lib/java-xmlbuilder-0.4.jar.... STARTUP_MSG: build = https://git-wip-us.apache.org/repos/asf/hadoop.git -r 756ebc8394e473ac25feac05fa493f6d612e6c50; compiled by 'arsuresh' on 2017-11-13T23:15Z STARTUP_MSG: java = 1.8.0_171 ************************************************************/ 18/07/01 22:31:25 INFO tools.DFSZKFailoverController: registered UNIX signal handlers for [TERM, HUP, INT] 18/07/01 22:31:25 INFO tools.DFSZKFailoverController: Failover controller configured for NameNode NameNode at master/192.168.0.120:9000 18/07/01 22:31:25 INFO zookeeper.ZooKeeper: Client environment:zookeeper.version=3.4.6-1569965, built on 02/20/2014 09:09 GMT 18/07/01 22:31:25 INFO zookeeper.ZooKeeper: Client environment:host.name=master 18/07/01 22:31:25 INFO zookeeper.ZooKeeper: Client environment:java.version=1.8.0_171 18/07/01 22:31:25 INFO zookeeper.ZooKeeper: Client environment:java.vendor=Oracle Corporation 18/07/01 22:31:25 INFO zookeeper.ZooKeeper: Client environment:java.home=/opt/jdk1.8.0_171/jre 18/07/01 22:31:25 INFO zookeeper.ZooKeeper: Client environment:java.class.path=/opt/hadoop-2.9.0/etc/hadoop:/opt/hadoop-2.9.0/share/hadoop/common/lib/nimbu..... 18/07/01 22:31:25 INFO zookeeper.ZooKeeper: Client environment:java.library.path=/opt/hadoop-2.9.0/lib/native 18/07/01 22:31:25 INFO zookeeper.ZooKeeper: Client environment:java.io.tmpdir=/tmp 18/07/01 22:31:25 INFO zookeeper.ZooKeeper: Client environment:java.compiler=<NA> 18/07/01 22:31:25 INFO zookeeper.ZooKeeper: Client environment:os.name=Linux 18/07/01 22:31:25 INFO zookeeper.ZooKeeper: Client environment:os.arch=amd64 18/07/01 22:31:25 INFO zookeeper.ZooKeeper: Client environment:os.version=3.10.0-862.el7.x86_64 18/07/01 22:31:25 INFO zookeeper.ZooKeeper: Client environment:user.name=spark 18/07/01 22:31:25 INFO zookeeper.ZooKeeper: Client environment:user.home=/home/spark 18/07/01 22:31:25 INFO zookeeper.ZooKeeper: Client environment:user.dir=/opt/hadoop-2.9.0 18/07/01 22:31:25 INFO zookeeper.ZooKeeper: Initiating client connection, connectString=master:2181,slave1:2181,slave2:2181 sessionTimeout=5000 watcher=org.apache.hadoop.ha.ActiveStandbyElector$WatcherWithClientRef@6ca8564a 18/07/01 22:31:26 INFO zookeeper.ClientCnxn: Opening socket connection to server master/192.168.0.120:2181. Will not attempt to authenticate using SASL (unknown error) 18/07/01 22:31:26 INFO zookeeper.ClientCnxn: Socket connection established to master/192.168.0.120:2181, initiating session 18/07/01 22:31:26 INFO zookeeper.ClientCnxn: Session establishment complete on server master/192.168.0.120:2181, sessionid = 0x100006501250000, negotiated timeout = 5000 18/07/01 22:31:26 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/HA in ZK. 18/07/01 22:31:26 INFO zookeeper.ZooKeeper: Session: 0x100006501250000 closed 18/07/01 22:31:26 WARN ha.ActiveStandbyElector: Ignoring stale result from old client with sessionId 0x100006501250000 18/07/01 22:31:26 INFO zookeeper.ClientCnxn: EventThread shut down 18/07/01 22:31:26 INFO tools.DFSZKFailoverController: SHUTDOWN_MSG: /************************************************************
现在可以启动集群啦
1,首先启动zookeeper(在master,slave1,slave2)
cd /opt/zookeeper-3.4.12/bin ./zkServer.sh start
2,在master上启动hdfs和yarn
cd /opt/hadoop-2.9.0 sbin/start-dfs.sh sbin/start-yarn.sh [spark@master sbin]$ cd /opt/hadoop-2.9.0 [spark@master hadoop-2.9.0]$ sbin/start-dfs.sh sbin/start-yarn.shStarting namenodes on [master slave1] slave1: starting namenode, logging to /opt/hadoop-2.9.0/logs/hadoop-spark-namenode-slave1.out master: namenode running as process 1939. Stop it first. slave3: starting datanode, logging to /opt/hadoop-2.9.0/logs/hadoop-spark-datanode-slave3.out slave2: starting datanode, logging to /opt/hadoop-2.9.0/logs/hadoop-spark-datanode-slave2.out slave1: starting datanode, logging to /opt/hadoop-2.9.0/logs/hadoop-spark-datanode-slave1.out Starting journal nodes [master slave1 slave2] slave2: journalnode running as process 2044. Stop it first. # 前边我们已经启动过了,是手动启动的。 master: journalnode running as process 1757. Stop it first. # 前边我们已经启动过了,是手动启动的。 slave1: journalnode running as process 2003. Stop it first. # 前边我们已经启动过了,是手动启动的。 Starting ZK Failover Controllers on NN hosts [master slave1] master: starting zkfc, logging to /opt/hadoop-2.9.0/logs/hadoop-spark-zkfc-master.out slave1: starting zkfc, logging to /opt/hadoop-2.9.0/logs/hadoop-spark-zkfc-slave1.out [spark@master hadoop-2.9.0]$ sbin/start-yarn.sh starting yarn daemons starting resourcemanager, logging to /opt/hadoop-2.9.0/logs/yarn-spark-resourcemanager-master.out slave1: starting nodemanager, logging to /opt/hadoop-2.9.0/logs/yarn-spark-nodemanager-slave1.out slave2: starting nodemanager, logging to /opt/hadoop-2.9.0/logs/yarn-spark-nodemanager-slave2.out slave3: starting nodemanager, logging to /opt/hadoop-2.9.0/logs/yarn-spark-nodemanager-slave3.out [spark@master hadoop-2.9.0]$ jps 2466 DFSZKFailoverController 1939 NameNode 2567 ResourceManager 2839 Jps 1757 JournalNode 1662 QuorumPeerMain [spark@master hadoop-2.9.0]$
3,slave1 上的resourcemanager需要手动启动
cd /opt/hadoop-2.9.0 sbin/yarn-deamon.sh start resourcemanager [spark@slave1 hadoop-2.9.0]$ jps 2003 JournalNode 2292 DataNode 2501 NodeManager 2613 Jps 2424 DFSZKFailoverController 1931 QuorumPeerMain 2191 NameNode [spark@slave1 sbin]$ cd /opt/hadoop-2.9.0 [spark@slave1 hadoop-2.9.0]$ cd sbin/ [spark@slave1 sbin]$ ls distribute-exclude.sh hadoop-daemons.sh httpfs.sh refresh-namenodes.sh start-all.sh start-dfs.sh start-yarn.sh stop-balancer.sh stop-secure-dns.sh yarn-daemon.sh FederationStateStore hdfs-config.cmd kms.sh slaves.sh start-balancer.sh start-secure-dns.sh stop-all.cmd stop-dfs.cmd stop-yarn.cmd yarn-daemons.sh hadoop-daemon.sh hdfs-config.sh mr-jobhistory-daemon.sh start-all.cmd start-dfs.cmd start-yarn.cmd stop-all.sh stop-dfs.sh stop-yarn.sh [spark@slave1 sbin]$ ./yarn-daemon.sh start resourcemanager starting resourcemanager, logging to /opt/hadoop-2.9.0/logs/yarn-spark-resourcemanager-slave1.out [spark@slave1 sbin]$ jps 2689 ResourceManager 2003 JournalNode 2292 DataNode 2740 Jps 2501 NodeManager 2424 DFSZKFailoverController 1931 QuorumPeerMain 2191 NameNode [spark@slave1 sbin]$
此时slave2
[spark@slave2 HA]$ jps 2208 DataNode 2470 Jps 2345 NodeManager 1978 QuorumPeerMain 2044 JournalNode [spark@slave2 HA]$
此时slave3
[spark@slave3 hadoop-2.9.0]$ jps 2247 Jps 2123 NodeManager 2013 DataNode [spark@slave3 hadoop-2.9.0]$
至此,高可用hadoop配置完毕,可访问浏览器:
http://192.168.0.120:50070 //namenode active http://192.168.0.121:50070 //namenode standby http://192.168.0.120:8088 //resourcemanager active http://192.168.0.121:8088 //resourcemanager standby
此时 http://192.168.0.120:50070/可以访问(显示为: 'master:9000' (active)),http://192.168.0.121:50070/可以访问(显示为: 'slave1:9000' (standby))
此时 http://192.168.0.121:8088/ 不可以访问,而http://192.168.0.120:8088/ 可以访问。
关闭的时候按相反的顺序关闭
高可用验证
1,验证hdfs
首先kill掉 master 上active的namenode
kill -9 <pid of NN>
[spark@master hadoop-2.9.0]$ jps 2466 DFSZKFailoverController 1939 NameNode 2567 ResourceManager 1757 JournalNode 1662 QuorumPeerMain 2910 Jps [spark@master hadoop-2.9.0]$ kill -9 1939 [spark@master hadoop-2.9.0]$ jps 2466 DFSZKFailoverController 2567 ResourceManager 2920 Jps 1757 JournalNode 1662 QuorumPeerMain [spark@master hadoop-2.9.0]$
然后查看 slave1 上状态为standby的namenode状态变成active。
此时 slave1 jps
[spark@slave1 sbin]$ jps 2689 ResourceManager 2881 Jps 2003 JournalNode 2292 DataNode 2501 NodeManager 2424 DFSZKFailoverController 1931 QuorumPeerMain 2191 NameNode [spark@slave1 sbin]$
此时 http://192.168.0.120:50070/ 不可以访问,http://192.168.0.121:50070/可以访问(显示为: 'slave1:9000' (active))
此时 http://192.168.0.121:8088/ 不可以访问,而http://192.168.0.120:8088/ 可以访问。
2,验证yarn
同上,kill掉active状态的rm后,standby状态下的rm即变成active,继续工作。
[spark@master hadoop-2.9.0]$ jps 2466 DFSZKFailoverController 2948 Jps 2567 ResourceManager 1757 JournalNode 1662 QuorumPeerMain [spark@master hadoop-2.9.0]$ kill -9 2567 [spark@master hadoop-2.9.0]$ jps 2466 DFSZKFailoverController 1757 JournalNode 1662 QuorumPeerMain 2958 Jps
此时 http://192.168.0.121:8088/ 可以访问,而http://192.168.0.120:8088/ 不可以访问。
http://192.168.0.120:50070/dfshealth.html#tab-overview

http://192.168.0.121:50070/dfshealth.html#tab-overview

http://192.168.0.120:8088/cluster/apps/RUNNING
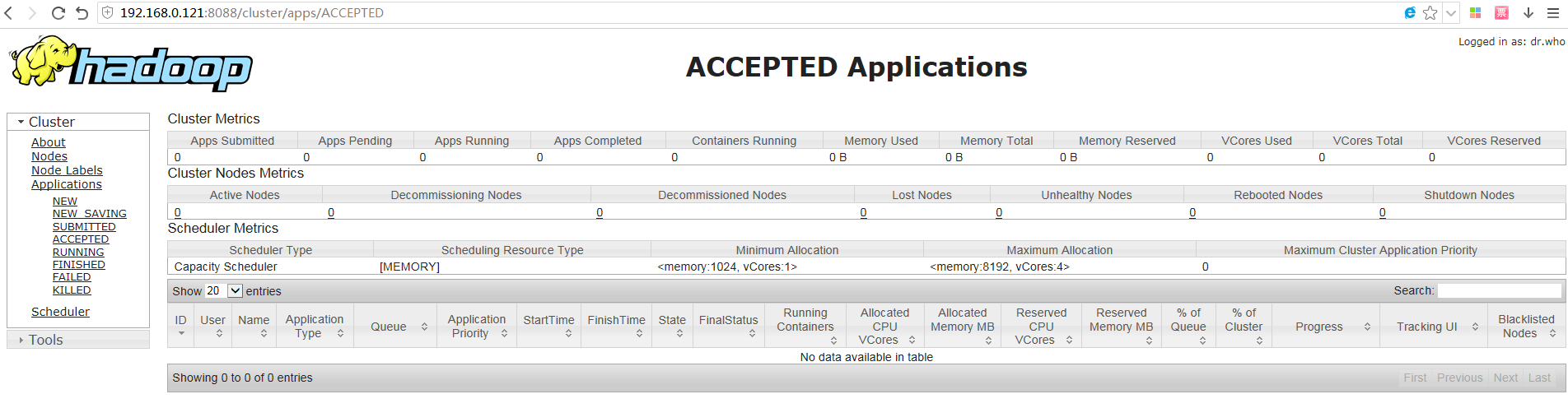
http://192.168.0.121:8088/cluster/apps/ACCEPTED
参考《https://www.cnblogs.com/jiangzhengjun/p/6347916.html》
《https://blog.csdn.net/qq_32166627/article/details/51553394》