作者:Dafna Shahaf
会议:ACM 2015.
研究大背景:自动化地从很大数据集中提取结构化的知识变得越来越难。在本篇文章中,我们将探索我们在文献中(25,26,27)中创立的方法来自动提取信息的“地铁地图”(metro maps)。
问题1: 什么是信息的地铁地图? 这是一个隐喻,信息就像地铁一样用直线表示,每一条线代表着一个故事;多条线可以代表多个故事,也可以代表一个故事从不同的方面来叙述。而每一个停站点,代表着文档集群。
问题2: 一个好的信息地铁图有哪些标准?很难说,但是想象以下,在实体世界,怎样的地铁规划算好呢? 尽可能的以较少的线路覆盖尽可能多的地点 --- 多样性(多个线路尽可能多的包含最重要的主题); 每一条线路都要尽可能有连贯性有意义(比如,地铁1号线主要是连接高铁站,机场,起着交通枢纽的作用;地铁2号线主要连接市区到市区,起着通勤日常起居作用)---- 每一条上的信息要有故事的连贯性; 线路跟线路之间要有合理的换乘站 ------ 故事与故事之间的关系和联系。
相关工作
虽然目前,在主题探测,摘要跟踪,时间文档挖掘等方向有大量的研究,但是自动构建地图目前为止是很新颖。我们与之前的研究不同之点在于:
1. 首先,我们的输出是结构化的 - 它不仅展示了信息的结构块,并且还展现了它们之间的联系。在摘要任务上(参考2,20,22),目标通常是通过列出一列表的句子来总结语料库。其他的方法(参考18,31,30)旨在发现新的事件。
也有很多尝试不仅仅限于列表的信息检索上的努力,而是尝试展示更丰富的信息界面,包括不同概念层次上的故事线(参考1,2,28,29);新闻分析的图形展示也很常见(参考10,14,17,19);同时也有考虑路径层面上的线的相关性的方法(参考5,6),但是它们没有考虑到文档的顺序。已有多个总结和可视化的文献和工具(参考4)。不像我们的系统,参考12,16中,使用单一的概念作为分析的单元,也就是粒度太精细了不太适合专家用。参考8,13中的可视化工具粒度与我们类似,但是他们关注与引用和共同引用。
最后,引用地铁的隐喻也曾经被引用过(参考文献21),但是这个地图是手动的,而不是自动生成的。
找到一个好地图
我们先形式化好的地图的一些特征, 然后阐述它们的构造作为优化问题。然后我们提供一些方法来构造这些地图。然后解释如何将这个概念应用到其它领域。
-------------------
目标函数
目标函数不明确。但是我们可以给出我们的问题定义:给定一个文档集,我们想要计算出总结和组织文档的地图。在这个地图里:
1. 由多条线组成,每条线都有站的顺序,
2. 每一站都是文档的集合/集群,
3. 每一条线都有自己的“主人公”的故事,并且线与线来自不同的方面,
4. “换乘站”表示主题与主题之间的联系
那么,要求我们可以知道:
要求一: 连贯性. 每一条故事要讲述一个故事/主题。为了方便描述,我们这里用一个文档表示一个站,评价是否连贯性通常来说,就是计算这两个文档的相似度/距离。因为每条链都有很多个连接点,那么我们评价这条链的连贯性,就是看最差的那个节点。(如图:上传不了。博客园服务器不是一般的垃圾,见链接吧:https://cacm.acm.org/magazines/2015/11/193323-information-cartography/fulltext) 如图2.我们可以发现,链条A中单词时而出现,时而消失然后再出现。而链条B中单词的持续性更长。由此,我们可以看出连贯性的定义。
我们把问题转换成线性规划优化问题,目标是选择一小组单词集,然后根据这个单词集进行评分。为了确保每个每个过渡的强度,链条的分数就是最弱的链接的分数(见参考文献24)。一条单独的链条的分数可能依赖于domain。在参考(文献26)中,我们展现了如何仅根据文档内容,来计算得分。在参考(文献25)中,我们展现了如何利用文章间的连接。
要求二:覆盖性. 覆盖性也就是多样性的同义词。一个高覆盖率的地图可以涵盖很多重要的单词。
问题转化为计算一个覆盖函数 , 来计算每个文档覆盖所有元素的程度好坏。同样的思路,我们可以将它扩展为一系列覆盖函数,来计算一群文档覆盖元素的好坏。 为了鼓励多样性,这个函数应该是子模块化。想想一下,如果一个地图已经很好的覆盖了一些元素,这时候再增加一个同样很好地覆盖了元素的文档,此时结果并不会有多少提升。这很少的提升会促使我们去选择那些覆盖了新的主题的文档(类似边际效用递减原则)。 接下来,我们引入了每个元素的权重概念,表明每个元素的重要程度。这个重要程度会因人而异,所以我们在(文献26)一文中,讨论了从用户反馈来调整参数,这也就引入了“个性化覆盖”的概念。
要求三:联结性. 不同的故事有着不同的结构,有些故事是简单的线性,而有些故事就复杂得多。为了捕捉故事的结构,我们仅仅计算出最少线路,来覆盖尽可能多的站。直观来看,我们的目标是,计算出尽可能长的线。
-------------------
总结以上我们讨论的来看,现在给出地铁图的标准目的:
必须满足:O1 高覆盖性
O2 结构高质量
受到的约束: C1 最小的线连贯性
C2 最小聚类质量
C3 最大地图大小
算法的标准描述和优化,请看"nformation cartography : Creating zoomable, large-scale maps of information"
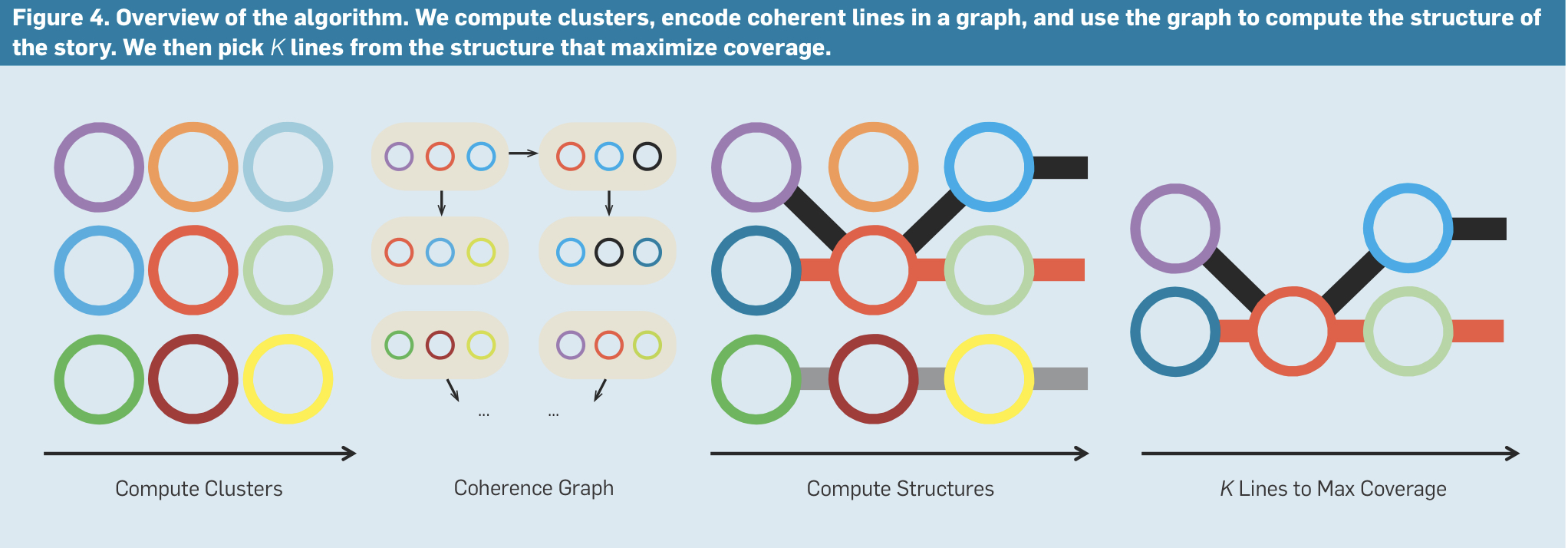
算法:
step1:根据查询计算出一个文档集合
step2:把文章分类成时间窗口,然后通过在word coocurrence graph上使用“COMMUNITY DETECTION算法”来为每个时间窗计算出好的聚类(约束2)(详见文献3)。 这些聚类就被视作站。
step3:一旦我们有了集群,我们就可以计算连贯的线(约束1)。
step4:编码了所有的连贯性的线后,我们确定故事的结构,优化联结性(目标2),然后尽可能的选择更长的线。
step5:根据用户,选择合适的地图大小(目标1和约束3)。
算法一览图如下:
-----------------------
复杂性和运行时间
给定一个查询和一系列文档,我们首先运行一个线性时间的算法 - 把文档集合D编译成一系列的单词出现图(翻译不准确,目前我不懂这个词)。 图的大小并不取决于集合D的大小,而取决于单词总量W(参考文献2 和 3)。 而我们最大的瓶颈是覆盖这个福州,因为复杂度是W数量的高次数多项式。一个平行的实施和简单的评估可以实现近似的情况下大大的加速。在实际执行时,我们系统运行1万个文档可以在不到1分钟的时间内完成。
-----------------------
参数
约束的C1-C3都需要手动调整,并且另一个参数也需要调整,那就是m,也就是用户的“历史窗口”大小/原先的线上用户能够记住的文章数量
应用
主要有四个应用领域:新闻、科学、法律文件、书籍
--------------
新闻
一、使用方法
我们使用上面的算法来计算有关新闻事件的新闻,然后集合多个数据集,包含了十万个帖子。系统演示请见:http://metromaps.stanford.edu/
二、评估
不好评估,一般使用外包
--------------
科学研究
目的是为了帮助新进入该领域的人最快的掌握研究动向(新的研究生之类,例如我)
一、方法
我们的数据集包括了超过3w5k个ACM会议和杂志的paper。与新闻不同的是,论文不能交叉。此时,我们稍微调整了下算法,把换乘站改成了引用。
二、评估
--------------
剩下两个应用与我的研究无关,因此略去。
使用地图
结论
下一篇:
connecting the dots between news articles". Shahaf.D. SIGKDD. 2010
参考:https://cacm.acm.org/magazines/2015/11/193323-information-cartography/fulltext
文献1:"Unfield analysis of streaming news". Ahmed.A. WWW.2011
文献2: "Termporal summaries of new topics". Allan. J . ACM SIGIR. 2001
文献4:"VIsualizing what we know". Borner.K. MIT. 2010
文献5:"Creation of a highly detailed, dynamic, global model and map of science." Boyack.W.W AIST.2014
文献6:"Mapping of science by combined co-citation and word analysis." Braam.R.R AIST.1999
文献8:"Detecting and visualizing emerging trends and transient patterns in scientific literature." Chen.C AIST.2006
文献10:"Fast discovery of connection subgraphs" Faloutsos. SIGKDD. 2004
文献12:"Exploring the computing literature with visualization and stepping stones and pathways." Fox.E.A. ACM.2006
文献13:
文献14:"Discovering diverse and salient threds in document collections". Gillenwater. 2012
文献16:"Connecting the dots between PubMed abstracts." Hossain. 2012.
文献17:"The web of topics: discovering the topology of topic evolution in a corpus". Jo. 2011
文献19:"Event threading within news topics". Nallapati.R. ACM.2004
文献18: "Bursty and hierarchical structure in steams". Kleinberg. J. DMKD.2003
文献20:"A survey of text summarization techiques". Nenkova.A. 2012
文献21:"Getting to more abstract places using the metro map metaphor". Nesbitt. IEEE.2004.
文献22:"Summarizing online news topics". Radev.D. ACM 2005
文献24: "connecting the dots between news articles". Shahaf.D. SIGKDD. 2010 ( 24)
文献25: "metro maps of science". SIGKDD.2012 Shahaf. D (25)
文献26: "Trains of thought: Generating information maps." WWW. 2012. Shahaf.D (26)
文献27: "Information cartography : Creating zoomable, large-scale maps of information" . SIGKDD. 2013. Shahaf.D (27)
文献28:"TimeMines: Constructing timelines with statistical models of word usage". Swan.R SIGKDD. 2000
文献29:"Evolutionary timeline summarization: A balanced optimization framework via iterative substitution" Yan.R SIGIR. 2011.
文献30: "Improving text categorization methods for event tracking." Yang.Y. SIGIR. 2000
文献31:"Learning approaches for detecting and tracking news event." Yang.Y IEEE. 1999