原题连接: http://118.190.20.162/view.page?gpid=T79
试题编号: 201809-1
试题名称: 卖菜
时间限制: 1.0s
内存限制: 256.0MB
题目背景
在一条街上有n个卖菜的商店,按1至n的顺序排成一排,这些商店都卖一种蔬菜。
第一天,每个商店都自己定了一个价格。店主们希望自己的菜价和其他商店的一致,第二天,每一家商店都会根据他自己和相邻商店的价格调整自己的价格。具体的,每家商店都会将第二天的菜价设置为自己和相邻商店第一天菜价的平均值(用去尾法取整)。
注意,编号为1的商店只有一个相邻的商店2,编号为n的商店只有一个相邻的商店n-1,其他编号为i的商店有两个相邻的商店i-1和i+1。
给定第一天各个商店的菜价,请计算第二天每个商店的菜价。
样例输入
8
4 1 3 1 6 5 17 9
样例输出
2 2 1 3 4 9 10 13
输入格式
输入的第一行包含一个整数n,表示商店的数量。
第二行包含n个整数,依次表示每个商店第一天的菜价。
输出格式
输出一行,包含n个正整数,依次表示每个商店第二天的菜价。
题解
头尾注意下,中间是除以3
n=int(input())
shop=list(map(int, input().split()))
p=[]
i=0
while(i<n):
if i==0 and i+1<n:
p.append((shop[i]+shop[i+1])//2)
i+=1
elif i==n-1 and i-1>=0:
p.append((shop[i]+shop[i-1])//2)
i+=1
else:
p.append((shop[i]+shop[i-1]+shop[i+1])//3)
i+=1
print(' '.join(map(str, p)))
原题连接: http://118.190.20.162/view.page?gpid=T78
试题编号: 201809-2
试题名称: 买菜
时间限制: 1.0s
内存限制: 256.0MB
问题描述:
问题描述
小H和小W来到了一条街上,两人分开买菜,他们买菜的过程可以描述为,去店里买一些菜然后去旁边的一个广场把菜装上车,两人都要买n种菜,所以也都要装n次车。具体的,对于小H来说有n个不相交的时间段[a1,b1],[a2,b2]...[an,bn]在装车,对于小W来说有n个不相交的时间段[c1,d1],[c2,d2]...[cn,dn]在装车。其中,一个时间段[s, t]表示的是从时刻s到时刻t这段时间,时长为t-s。
由于他们是好朋友,他们都在广场上装车的时候会聊天,他们想知道他们可以聊多长时间。
输入格式
输入的第一行包含一个正整数n,表示时间段的数量。
接下来n行每行两个数ai,bi,描述小H的各个装车的时间段。
接下来n行每行两个数ci,di,描述小W的各个装车的时间段。
输出格式
输出一行,一个正整数,表示两人可以聊多长时间。
样例输入
4
1 3
5 6
9 13
14 15
2 4
5 7
10 11
13 14
样例输出
3
数据规模和约定
对于所有的评测用例,1 ≤ n ≤ 2000, ai < bi < ai+1,ci < di < ci+1,对于所有的i(1 ≤ i ≤ n)有,1 ≤ ai, bi, ci, di ≤ 1000000。
题解
这道题最好想到的就是打表模拟,因为使用python语言时,给的内存空间都很大,所以第二题的难度一般行得通
注意一下,时间段的长度
n = int(input())
list1 = [0]*1000001
summ = 0
x = []
h = []
for i in range(n):
s = list(map(int,input().split()))
t1, t2 = s[0], s[1]
while t1 < t2:
list1[t1] += 1
t1 += 1
x += [s]
# print(list1[:16])
for i in range(n):
s = list(map(int,input().split()))
t1, t2 = s[0], s[1]
while t1 < t2:
list1[t1] += 1
t1 += 1
h += [s]
# print(list1[:16])
minn = min(x[0][0], h[0][0])
maxx = max(x[n-1][1], h[n-1][1])
for i in range(minn, maxx):
if list1[i] == 2:
summ += 1
print(summ)
方法二
方法二是把两类时间段交叠的情况全部列举出来
如下所示,可以把这个过程想象成为一艘船行驶的过程,相见----相交----包含(两种)----分别----远离
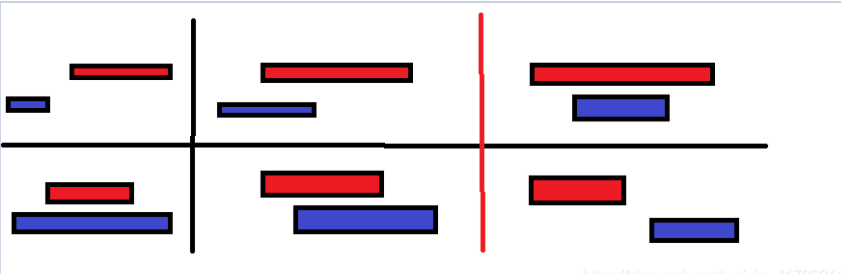
第二列情况判断时,要注意一下
n=(int)(input())
H=[]
W=[]
for i in range(n):
tmp = input().split()
H += [[int(tmp[0]), int(tmp[1])]]
for i in range(n):
tmp = input().split()
W += [[int(tmp[0]), int(tmp[1])]]
summ = 0
for i in H:
for j in W:
if i[0] >= j[1]:
continue
elif j[0] <= i[0] and j[1] <= i[1]:
summ += j[1] - i[0]
elif i[0] <= j[0] and j[1] <= i[1]:
summ += j[1]- j[0]
elif i[1] <= j[0]:
break # 一开始写成了continue,第六种情况,因为时间段是不连续增长的,小于此时,后面也就不用比较了
elif i[1] <= j[1] and i[0] <= j[0]:
summ += i[1] - j[0]
elif i[0] >= j[0] and i[1] <= j[1]:
summ += i[1] - i[0]
print(summ)
清纯打表法
n=int(input())
ans=[0]*1000001
for _ in range(n*2):
s,t=input().split()
s,t=int(s),int(t)
for i in range(s,t):
ans[i]+=1
summ=0
for i in range(1000001):
if ans[i]==2:
summ+=1
print(summ)
试题编号: 201809-3
试题名称: 元素选择器
时间限制: 1.0s
内存限制: 256.0MB




题解,实现了最简单的三个测试点(判断是否含有标签和id属性),其他的没写

'''
11 5
html
..head
....title
..body
....h1
....p #subtitle
....div #main
......h2
......p #one
......div
........p #two
p
#subtitle
h3
div p
div div p
'''
from copy import deepcopy
def deal_query(query_list, word):
lens=len(query_list)
ans=0
res=[]
if lens==1:
for j in range(n):
if query_list[0] in word[j][1]:
ans+=1
res.append(j+1)
print(ans,end=" ")
for r in res:
print(r,end=" ")
print()
else:
tmp_res={}
tmp_word=deepcopy(word)
#['div', 'div', 'p']
for q in query_list:
for j in range(n):
if q in tmp_word[j][1]:
pass
if __name__=="__main__":
n,m=input().split()
n,m=int(n),int(m)
word=[]
#[[0, 'html'],[2, 'p#subtitle'], [2, 'div#main']]
for _ in range(n):
tmp=input()
num_dot=tmp.count('.')//2
tmp=tmp.replace('.','')
word.append([num_dot,tmp.replace(' ','')])
# ['p'], ['#subtitle'], ['h3'], ['div', 'p'], ['div', 'div', 'p']
for _ in range(m):
tmp2=input().split(' ')
deal_query(tmp2,word)
试题编号: 201809-5
试题名称: 线性递推式
时间限制: 1.0s
内存限制: 256.0MB

样例输入
3 3 6
2 0 4
样例输出
12
32
80
208
样例说明
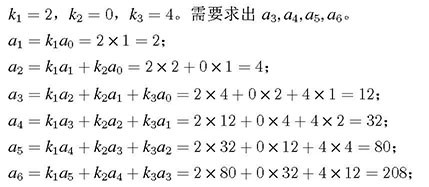
样例输入
2 1 11
1 1
样例输出
1
2
3
5
8
13
21
34
55
89
144
样例说明

样例输入
10 10 20
532737790 634932889 335818534 101179174 977780682 695192541 779962395 295668292 157661238 325351676
样例输出
119744921
651421717
601080475
163399777
291546699
108479226
406175654
344671679
459752012
489415425
349454810
数据规模和约定
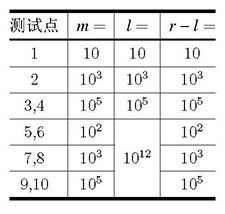
题解: 完全为了分数,两次一模一样的代码一次0分,一次20,考试的时候给的时间长,应该分数会多点

m,l,r=map(int, input().split())
k=[0]
k.extend(list(map(int, input().split())))
a=[1]
a.extend([0]*(r+1))
for i in range(1,r+1):
tmp=0
for j in range(1,min(i,m)+1):
tmp+=k[j]*a[i-j]
a[i]=tmp%998244353
for v in range(l,r+1):
print(a[v])
参考链接
https://blog.csdn.net/weixin_41706011/article/details/86601674