接着上一篇继续.....
E-R 关系的数据分片策略,子表的记录与所关联的父表记录存放在同一个数据分片上,即子表依赖于父表,通过表分组(Table Group)保证数据 Join 不会跨库操作。
表分组(Table Group)是解决跨分片数据 join 的一种很好的思路,也是数据切分规划的重要一条规则。
MyCAT的官方文档是通过customer这张表来讲解E-R分片策略的,现记录如下:
1.在schema.xml配置文件中schema标签中配置customer table 的分库策略
<!-- ER表配置示例-->
<table name="customer" primaryKey="ID" dataNode="dn1,dn2,dn3" rule="sharding-by-intfile">
<childTable name="orders" primaryKey="ID" joinKey="customer_id" parentKey="id">
<childTable name="order_items" joinKey="order_id" parentKey="id" /> </childTable>
<childTable name="customer_addr" primaryKey="ID" joinKey="customer_id" parentKey="id" />
</table>
配置说明: table标签表明这是配置表信息; name = "customer" 说明这张表的名称叫customer, id 是 主键, 表分布在dn1,dn2,dn3这三个数据库中, 表的分片策略是sharding-by-intfile.
childTable表明子表信息, 此示例中说明customer关联了两张子表,分别是orders,customer_addr;我们以orders表为例说明.
orders表的主键是id,它通过joinKey关联父表的parentKey.本例中orders表就是以customer_id去关联customer表的id.也就是说,当customer表中id = 1 在dn1时,那么orders表中customer_id = 1这条数据也会在dn1这个数据库. 这样设置就避免了跨库join,提高了查询效率.
同样的,order_items表关联的父表是orders. 原理一样.
2. 测试
创建customer表:
customer(id int not null primary key,name varchar(100),company_id int not null,sharding_id int not null);
插入数据:
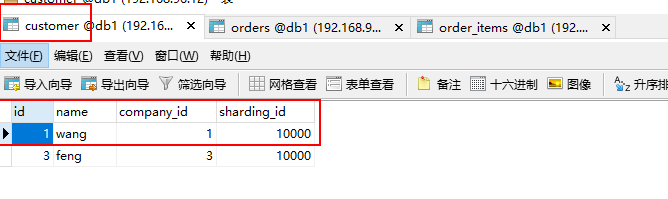
insert into customer (id,name,company_id,sharding_id )values(1,'wang',1,10000);
insert into customer (id,name,company_id,sharding_id )values(2,'xue',2,10010);
insert into customer (id,name,company_id,sharding_id )values(3,'feng',3,10000);
insert into customer (id,name,company_id,sharding_id )values(4,'test',4,10010);
insert into customer (id,name,company_id,sharding_id )values(5,'admin',5,10010);
创建orders表:
create table orders (id int not null primary key ,customer_id int not null,sataus int ,note varchar(100) );
插入数据:
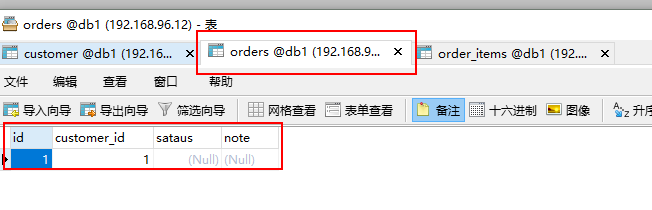
insert into orders(id,customer_id) values(1,1);
insert into orders(id,customer_id) values(2,2);
insert into orders(id,customer_id,sataus,note) values(3,4,2,'xxxx');
insert into orders(id,customer_id,sataus,note) values(4,5,2,'xxxx');
创建order_items表:
create table order_items (id int not null primary key ,order_id int not null,remark varchar(100) );
插入数据:
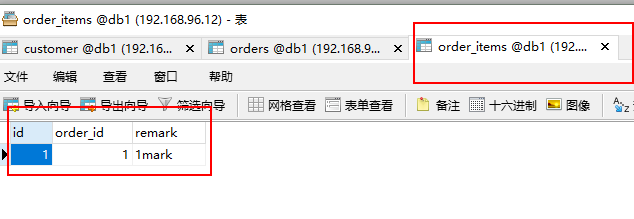
insert into order_items(id,order_id,remark) VALUES (1,1,'1mark');
insert into order_items(id,order_id,remark) VALUES (2,2,'2mark');
insert into order_items(id,order_id,remark) VALUES (3,3,'3mark');
insert into order_items(id,order_id,remark) VALUES (4,4,'4mark');
观察结果:
验证完毕!!!