一种树,适合于写多读少的场景。主要是利用了延迟更新、批量写、顺序写磁盘(磁盘sequence access比random access快)。
背景
回顾数据存储的两个“极端”发展方向
加快读:加索引(B+树、二分查找树等)
目的是为了尽快查到目标数据,从而提高查询速度;但由于写入数据时同时要维护索引,故写效率较低。
加快写:纯日志型,不加索引,数据以append方式追加写入
append利用了“磁盘顺序写比任意写性能高”的特性,使得写入速度非常高(接近磁盘理论写入速度);因缺乏索引支持故需要扫描所有记录,故查询性能低。典型的是Kafka数据存储。
if we are interested in write throughput, what is the best method to use? A good starting point is to simply append data to a file. This approach, often termed logging, journaling or a heap file, is fully sequential so provides very fast write performance equivalent to theoretical disk speeds (typically 200-300MB/s per drive).
Benefiting from both simplicity and performance log/journal based approaches have rightfully become popular in many big data tools. Yet they have an obvious downside. Reading arbitrary data from a log will be far more time consuming than writing to it, involving a reverse chronological scan, until the required key is found.
This means logs are only really applicable to simple workloads, where data is either accessed in its entirety, as in the write-ahead log of most databases, or by a known offset, as in simple messaging products like Kafka.
LSM Tree
LSM Tree以第二种为基础再结合了第一种,其目标在于在尽可能保证高写入性能的同时提高查询性能。
LSM trees sit in the middle-ground between a journal/log file and a traditional single-fixed-index such as a B+ tree or Hash index.
In essence they do everything they can to make disk access sequential.
其也是采用顺序append,但进一步做了文件层次组织、延迟更新、保证key有序等处理,使得文件本身相当于一种索引,从而相比于纯日志型在查询速度方面有所提高。
原理
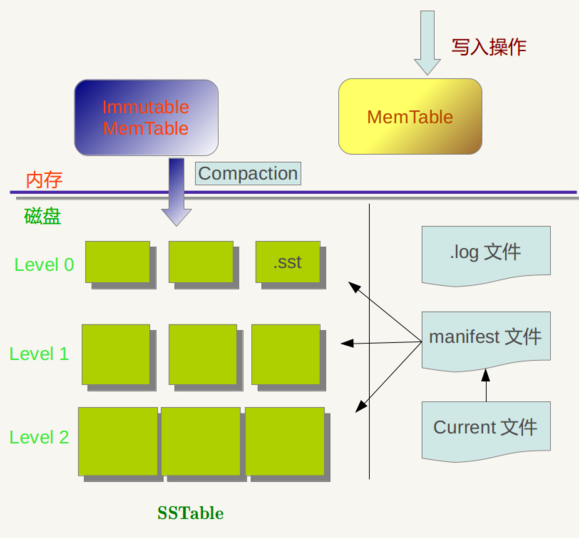
1、数据读写时均需指定key。
2、add数据时先写入内存Buffer(称为Memtable)。
这里面的数据按key排序(可通过跳表或各种树实现);
数据写入Memtable前会以WAL(write-ahead-log)方式先写log到disk,以使Memtable中数据在机器故障后可根据log恢复。更好的方式是Memtable满后变成Immutable Memtable并生成一个新的Buffer接收写入,每个接收写入的Memtable对应一个WAL文件。
3、当Memtable里数据达到一定量(个数、大小等)后数据被批量地、以append方式顺序写入disk成为一个文件,可见此时文件内部是按key有序的了(成为SSTable)。
4、所有写入Memtable或disk的数据均不会被修改:新的add、delete、update操作在内部实现上都是产生新的entry,而不会去修改同key的entry,因此存在冗余:同一个key有多个版本的数据、不同文件间有相同key的entry。
5、解决冗余:系统内部会周期性对disk上若干文件进行合并,合并时会remove any duplicated updates or deletions(是以谓之“延迟更新”)。由于各文件内部是有序的故合并非常快。
Level Based Compaction:Level DB中逻辑上以level对文件分类(如上图),下层level的文件由上层level的文件合并而成;level0中不同文件中可能有相同key,但level1及以下level不再会有冗余。
6、read操作:先从Memtable中查,若未查到则对各disk文件按文件创建时间由新到旧对各文件遍历查。
由于文件内部是有序的,故相比于纯日志型存储,LSM Tree查询更快(如可用二分查找);
由于需要遍历各文件故查询速度相比于B+树差,且文件越多查的性能越慢;
为提高查询效率,措施:增加合并操作以减少文件数量、生成大的排序的文件;对每个文件使用布隆过滤器以可快速确定此文件是否有指定key的entry;Level Based Compaction使得可以记录每个level中key的范围(mainfest文件)从而查询时每个level只要查一个文件。
总结
特点:
写入的数据优先写内存,且在内存按key排序了;
disk写是批量、顺序写;
写入的数据不可变,不会被修改。add、delete、update在内部都是add操作,存在冗余,由定期的合并操作来消除冗余;
因数据在内存排过序,故在写入disk后每个文件内部也按key有序;
文件内部按key有序,故合并操作很快(线性复杂的);有利于查询(二分查找等)
高写入性能的原因:写入disk是批量、顺序写
与加B+树等树型索引结构的存储方式比:写性能大幅度提高,读性能差些。
与纯日志型比:多了合并操作(虽是额外开销但因文件是各自内部有序的故合并很快)、查询性能提高
典型应用:Level DB,写性能远大于读性能;缺点之一是还不支持分布式。此外,HBase、Cassandra、SQLLite、Mongodb等亦是基于之。
参考资料
http://www.benstopford.com/2015/02/14/log-structured-merge-trees/(主)