第六章 利用社交网络数据
6.2 社交网络数据简介
用图G(V,E,W)描述社交网络数据,V为顶点集合对应用户集;E为边集,两个用户之间有社交网络关系则就有一条边联系;W为每条边的权重.Facebook对应的社交网络为无向图(关系需要双方的确认),Twitter为有向图(朋友关系是单向的).
三种社交网络数据:
> 双向确认的社交网络数据
> 单向关注的社交网络数据
> 基于社区的社交网络数据( 用户之间没有明确的关系,只是包含了用户属于哪些社区的信息,例如喜欢海贼王的会有一些自己的圈子,都是天南地北的娃)
6.2 基于社交网络的推荐
优点:
> 基于好友的推荐可以增加推荐的信任度
> 社交网络可以解决冷启动问题
基于领域的社会化推荐算法:
用$p_{ui} =sum_{v{in}out(u)}w_{uv}r_{vi}$表示用户u对物品i的兴趣度.$out(u)$是用户的好友集合.$w_{uv}$由用户u,v的熟悉度以及兴趣相似度来衡量.熟悉度可以用两者的共同好友比例来度量$familiarity(u,v) =frac{left| out(u)cap out(v) ight|}{left| out(u) cup out(v) ight|}$.兴趣的相似度可以用两者喜欢物品的重合度来衡量$similiarity(u,v)= frac{left| N(u)cap N(v) ight|}{left| N(u) cup N(v) ight|}$N(u)表示用户u喜欢的物品集合.
基于图的社会化推荐算法:
将用户物品二分图以及社交网络图融合为一个二分图,如下图所示:
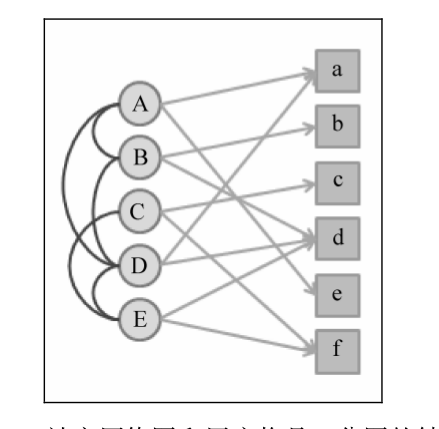
左侧为用户,右侧为商品,如果用户有好友关系,则有边相连.用户之间的边权可以定义为用户之间的相似度,用户物品之间的边权则可以定义为喜欢程度.
信息流推荐
关注的好友展示的信息并不都是用户感兴趣的信息,信息流推荐主要解决的是从好友的信息墙中推荐用户感兴趣的内容.最流行的信息流推荐算法是Facebook的EdgeRank.算法将其他用户对当前用户信息流中的会话产生过行为的行为称为 edge ,而一条会话的权重定义为:![]() .$u_e$为产生行为用户和当前用户的相似度.$w_e$指行为的权重,$d_e$表示时间衰减参数,越早的行为影响越小.上述算法可以理解为:如果一个会话被你熟悉的好友最近产生过重要的行为,它会有较高的权重.上述算法仅仅重视了"我"周围用户的社会化兴趣,并没与关注"我"个人的兴趣,主要加入了以下三个考虑:
.$u_e$为产生行为用户和当前用户的相似度.$w_e$指行为的权重,$d_e$表示时间衰减参数,越早的行为影响越小.上述算法可以理解为:如果一个会话被你熟悉的好友最近产生过重要的行为,它会有较高的权重.上述算法仅仅重视了"我"周围用户的社会化兴趣,并没与关注"我"个人的兴趣,主要加入了以下三个考虑:
> 会话的长度
> 话题相关性(用关键词向量去比对和用户历史感兴趣话题的相关度) (item-base?)
> 用户熟悉程度
给用户推荐好友
好友推荐算法也称为链接预测(Link Prediction in Social Network - Jon Kleinberg)
(1) 基于内容的匹配 (计算内容相似度)
(2) 基于兴趣的好友推荐 (计算用户之间的兴趣相似度 UserCF 以及 兴趣标签)
(3) 基于社交网络图的好友推荐 (相似度的计算要规避热门人或物品带来的影响,冷门的东西更能发掘出个性)