网络I/O模型
人多了,就会有问题。web刚出现的时候,光顾的人很少。近年来网络应用规模逐渐扩大,应用的架构也需要随之改变。C10k的问题,让工程师们需要思考服务的性能与应用的并发能力。
网络应用需要处理的无非就是两大类问题,网络I/O,数据计算。相对于后者,网络I/O的延迟,给应用带来的性能瓶颈大于后者。网络I/O的模型大致有如下几种:
- 阻塞I/O(bloking I/O)
- 非阻塞I/O(non-blocking I/O)
- 多路复用I/O(multiplexing I/O)
- 异步I/O(asynchronous I/O)
1 阻塞IO
由于用户态转内核态,向系统发起数据请求,系统处于等待数据状态(阻塞)当数据来了将数据从内核态拷贝到用户态
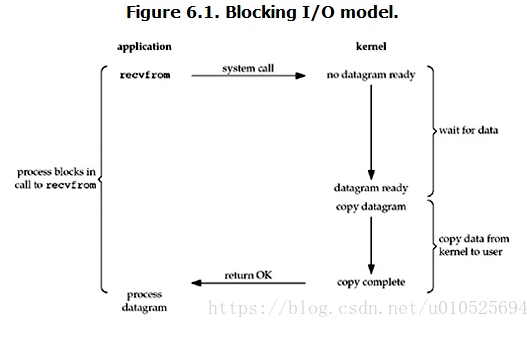
当用户进程调用了recvfrom这个系统调用,kernel就开始了IO的第一个阶段:准备数据。对于network io来说,很多时候数据在一开始还没有到达(比如,还没有收到一个完整的UDP包),这个时候kernel就要等待足够的数据到来。
而在用户进程这边,整个进程会被阻塞。当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。
所以,blocking IO的特点就是在IO执行的两个阶段(等待数据和拷贝数据两个阶段)都被block了。
几乎所有的程序员第一次接触到的网络编程都是从listen()、send()、recv() 等接口开始的,使用这些接口可以很方便的构建服务器/客户机的模型。然而大部分的socket接口都是阻塞型的。如下图
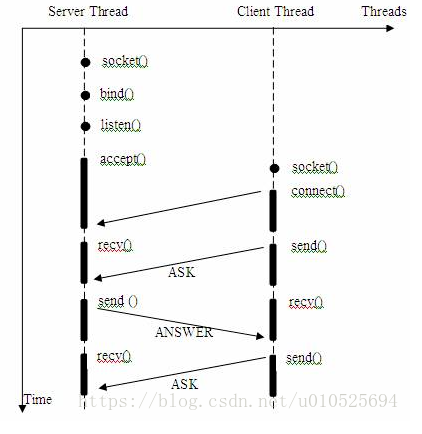
所谓阻塞型接口是指系统调用(一般是IO接口)不返回调用结果并让当前线程一直阻塞,只有当该系统调用获得结果或者超时出错时才返回。
非阻塞IO(non-blocking IO)
在网络I/O时候,非阻塞I/O也会进行recvform系统调用,检查数据是否准备好,与阻塞I/O不一样,"非阻塞将大的整片时间的阻塞分成N多的小的阻塞, 所以进程不断地有机会 '被' CPU光顾"。
也就是说非阻塞的recvform系统调用调用之后,进程并没有被阻塞,内核马上返回给进程,如果数据还没准备好,此时会返回一个error。进程在返回之后,可以干点别的事情,然后再发起recvform系统调用。重复上面的过程,循环往复的进行recvform系统调用。这个过程通常被称之为轮询。轮询检查内核数据,直到数据准备好,再拷贝数据到进程,进行数据处理。需要注意,拷贝数据整个过程,进程仍然是属于阻塞的状态。

我们再用钓鱼的方式来类别,当我们抛竿入水之后,就看下鱼漂是否有动静,如果没有鱼上钩,就去干点别的事情,比如再挖几条蚯蚓。然后不久又来看看鱼漂是否有鱼上钩。这样往返的检查又离开,直到鱼上钩,再进行处理。
非阻塞 IO的特点是用户进程需要不断的主动询问kernel数据是否准备好。
多路复用I/O(multiplexing I/O)
可以看出,由于非阻塞的调用,轮询占据了很大一部分过程,轮询会消耗大量的CPU时间。结合前面两种模式。如果轮询不是进程的用户态,而是有人帮忙就好了。多路复用正好处理这样的问题。
多路复用有两个特别的系统调用select或poll。select调用是内核级别的,select轮询相对非阻塞的轮询的区别在于---前者可以等待多个socket,当其中任何一个socket的数据准好了,就能返回进行可读,然后进程再进行recvform系统调用,将数据由内核拷贝到用户进程,当然这个过程是阻塞的。多路复用有两种阻塞,select或poll调用之后,会阻塞进程,与第一种阻塞不同在于,此时的select不是等到socket数据全部到达再处理, 而是有了一部分数据就会调用用户进程来处理。如何知道有一部分数据到达了呢?监视的事情交给了内核,内核负责数据到达的处理。也可以理解为"非阻塞"吧。

对于多路复用,也就是轮询多个socket。钓鱼的时候,我们雇了一个帮手,他可以同时抛下多个钓鱼竿,任何一杆的鱼一上钩,他就会拉杆。他只负责帮我们钓鱼,并不会帮我们处理,所以我们还得在一帮等着,等他把收杆。我们再处理鱼。多路复用既然可以处理多个I/O,也就带来了新的问题,多个I/O之间的顺序变得不确定了,当然也可以针对不同的编号。
多路复用的特点是通过一种机制一个进程能同时等待IO文件描述符,内核监视这些文件描述符(套接字描述符),其中的任意一个进入读就绪状态,select, poll,epoll函数就可以返回。对于监视的方式,又可以分为 select, poll, epoll三种方式。
了解了前面三种模式,在用户进程进行系统调用的时候,他们在等待数据到来的时候,处理的方式不一样,直接等待,轮询,select或poll轮询,第一个过程有的阻塞,有的不阻塞,有的可以阻塞又可以不阻塞。当时第二个过程都是阻塞的。从整个I/O过程来看,他们都是顺序执行的,因此可以归为同步模型(asynchronous)。都是进程主动向内核检查。
异步I/O(asynchronous I/O)
相对于同步I/O,异步I/O不是顺序执行。用户进程进行aio_read系统调用之后,无论内核数据是否准备好,都会直接返回给用户进程,然后用户态进程可以去做别的事情。等到socket数据准备好了,内核直接复制数据给进程,然后从内核向进程发送通知。I/O两个阶段,进程都是非阻塞的。

比之前的钓鱼方式不一样,这一次我们雇了一个钓鱼高手。他不仅会钓鱼,还会在鱼上钩之后给我们发短信,通知我们鱼已经准备好了。我们只要委托他去抛竿,然后就能跑去干别的事情了,直到他的短信。我们再回来处理已经上岸的鱼。
同步和异步的区别
通过对上述几种模型的讨论,需要区分阻塞和非阻塞,同步和异步。他们其实是两组概念。区别前一组比较容易,后一种往往容易和前面混合。在我看来,所谓同步就是在整个I/O过程。尤其是拷贝数据的过程是阻塞进程的,并且都是应用进程态去检查内核态。而异步则是整个过程I/O过程用户进程都是非阻塞的,并且当拷贝数据的时是由内核发送通知给用户进程。

对于同步模型,主要是第一阶段处理方法不一样。而异步模型,两个阶段都不一样。这里我们忽略了信号驱动模式。这几个名词还是容易让人迷惑,只有同步模型才考虑阻塞和非阻塞,因为异步肯定是非阻塞,异步非阻塞的说法感觉画蛇添足。