List接口:
它的父类是 Collections
List接口派系的三大特点:

它下面的所有子类都是具有这些特性的。
List接口的自己的特有方法:
前面说过,List 接口的特点是带索引,所以 API文档中,看见带有索引的方法一般都是它自己特有的方法。


1 package cn.zcb.demo01; 2 import java.util.ArrayList; 3 import java.util.List; 4 5 public class Test { 6 public static void main(String[] args) { 7 List<Integer> arrayList = new ArrayList<>(); //多态调用。 8 9 for (int i=0;i<5;i++){ 10 arrayList.add(i); 11 } 12 System.out.println(arrayList); 13 14 //List接口特有方法1:void add(int idx,T e); 15 arrayList.add(1,15);//在 idx =1 处加上15 16 System.out.println(arrayList); 17 18 //List接口特有方法2:E get(int idx) 19 int a = arrayList.get(2); 20 System.out.println(a); 21 22 //List接口特有方法3:E remove(int idx) 23 int a2 = arrayList.remove(0); 24 System.out.println(arrayList); 25 System.out.println("被删除的元素是 "+a2); 26 27 //List接口特有方法4:E set(int idx,E); 28 int ret = arrayList.set(0,1); 29 System.out.println(arrayList); 30 System.out.println("被修改的元素是:"+ret); 31 32 } 33 }
注:带有索引的操作都要防止索引越界产生异常。
List接口的实现类对象的三种遍历方式:
1,集合的通用模式: 迭代器方式。
2,使用for循环 索引idx 并结合 E get(int idx);
3, 使用增强for循环
1 package cn.zcb.demo01; 2 import java.util.ArrayList; 3 import java.util.Iterator; 4 import java.util.List; 5 6 public class Test { 7 public static void main(String[] args) { 8 List<Integer> arrayList = new ArrayList<>(); //多态调用。 9 10 for (int i=0;i<5;i++){ 11 arrayList.add(i); 12 } 13 /*List三种遍历模式 14 * */ 15 //1 使用迭代器(集合通用的方法) 16 Iterator<Integer> iterator = arrayList.iterator(); //arrayList.iterator() 的返回值是 Iterator接口的实现类对象。 这里直接用Iterator来接收,发生了多态。 17 while (iterator.hasNext()){ 18 //这里的一个操作 .next() 返回一个值,并将指针往后挪一个。 19 int ret = iterator.next(); 20 System.out.print(ret); 21 } 22 23 //2 使用for循环 + 索引 + get(int idx) 24 for (int i=0;i< arrayList.size();i++){ 25 System.out.print(arrayList.get(i)); 26 } 27 //3 增强for 循环 28 for (int i:arrayList){ 29 System.out.print(i); 30 } 31 } 32 }
如果只是单单遍历的话,推荐使用增强for 循环,简单好用。
迭代器的并发修改异常:
其实就是当使用迭代器遍历的过程中,我们却修改了集合中存储的长度!。

例如如下代码:就出现了并发修改异常:
1 package cn.zcb.demo01; 2 import java.util.ArrayList; 3 import java.util.Iterator; 4 import java.util.List; 5 6 public class Test { 7 public static void main(String[] args) { 8 List<Integer> arrayList = new ArrayList<>(); //多态调用。 9 10 for (int i=0;i<5;i++){ 11 arrayList.add(i); 12 } 13 Iterator <Integer> iterator = arrayList.iterator(); 14 while (iterator.hasNext()){ 15 int ret = iterator.next(); 16 System.out.println(ret); 17 if(ret == 3){ 18 arrayList.add(10); 19 } 20 } 21 } 22 }
注: 如果使用set修改某个元素的值也可以。但是就是不能修改长度!!!长度不能变!
补充:
我们平时用来比较两个东西是否相等,
对于基础类型之间的比较,我们可以使用 ==
但是对于引用类型的比较,我们应该使用 .equals() 方法。
List接口下实现类的数据存储 的结构:
List 接口下有很多个实现类。它们存储元素采用的结构方式是不同的,这样就导致了这些集合有它们各自的特点,供我们在不同的环境下使用。
数据存储的常用结构有:堆栈,队列,数组,链表。
1,堆栈:

2,堆栈:

3,数组:

4,链表:

List接口的实现类--ArrayList 类:
它是List接口的一个实现类,它的底层实现是用数组来做的。
ArrayList自身的特点:
它是一个可变长的数组。
查询快,增删慢。

List接口的实现类--LinkedList 类:
它也是List 的一个实现类,它的底层是用链表(单向链表) 来实现的。
LinkedList自身的特点:
增删快,查询慢。

主要是对首尾进行操作。
LinkedList特有的方法 :



代码省略。
List接口的实现类--Vector 类:
它基本上和ArrayList 一样,只不过它是同步的,是安全的(速度慢)。
而ArrayList 是异步,(速度快)。(虽然不安全),所以Vector基本已经被ArrayList取代了。
补充:通常速度快的不安全,速度慢的安全。
Set接口:

Set接口介绍:

它的遍历方式只有两种:
1,迭代器,
2,增强for
没有索引的遍历方式。
Set接口中的特有方法:
它几乎和它的父亲Collections接口中的方法一模一样,所以没有什么它独有的方法可看。
Set接口的实现类--HashSet类:
底层数据结构是哈希表。不同步,运行速度快。增删和查询都比较快。
它由哈希表(实际上是一个HashMap实例)支持。
集合分两大接口,Interable和 Map 两个
所以,学了HashSet 就相当于学了HashMap 。
HashSet 类的特点:


代码:
1 package cn.zcb.demo01; 2 import java.util.HashSet; 3 import java.util.Iterator; 4 5 public class Test { 6 public static void main(String[] args) { 7 /*Set接口的实现类 HashSet(哈希表) 的使用*/ 8 HashSet<String> hashSet = new HashSet(); 9 10 for (int i=0;i<5;i++){ 11 hashSet.add("a"+i); 12 } 13 //使用迭代器遍历 hashSet 14 Iterator<String> iterator = hashSet.iterator(); 15 while (iterator.hasNext()){ 16 String ret = iterator.next(); 17 System.out.println(ret); 18 } 19 } 20 }
注:它的输出顺序和 代码中存储的顺序无关。
它是无序的。
哈希表的数据结构:
哈希表是 链表,数组的结合体!!!所以它 增删元素(链表) 和 查询元素(数组)都比较快。
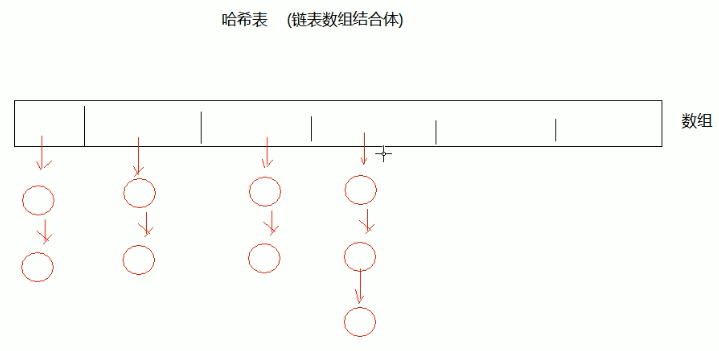

这里的桶是个比喻,指的是链表的节点。
初始容量:指的是数组的长度,默认是16.

加载因子指的是:当数组中的实际长度达到容量的百分比之后,就会自动扩容了。所以加载因子不能太小。
当比例达到加载因子的时候,数组就会进行扩容了,这个动作叫做 再哈希 ,rehash()。
对象的哈希值:
它就是个普通的十进制值。
它是父类Object中的一个方法 public int hashCode();
正因为它是Object 中的一个方法,所以所有的对象都是可以调用它的。
如下代码:
1 package cn.zcb.demo01; 2 3 public class Person { 4 5 6 }
1 package cn.zcb.demo01; 2 3 public class Test { 4 public static void main(String[] args) { 5 Person person = new Person(); 6 System.out.println(person.hashCode()); 7 } 8 }
.hashCode() 它的源码我们不能看到。
但是因为它不是final ,也不是private ,所以我们可以重写它。
重写:
1 package cn.zcb.demo01; 2 3 public class Person { 4 5 public int hashCode(){ 6 return 0; 7 } 8 }
1 package cn.zcb.demo01; 2 3 public class Test { 4 public static void main(String[] args) { 5 Person person = new Person(); 6 System.out.println(person.hashCode()); 7 } 8 }
hash值是HashSet 中存储数据的依据。
String类 重写了Object的方法 .hashCode():
前面是我们自己的类 重写了.hashCode() ,下面看String如何重写的。

原因是:String类继承了Object 类,它重写了Object 的方法hashCode(),它有它自己的计算hash值的方法。所以二者的hash值一样。
1 package cn.zcb.demo01; 2 3 public class Test { 4 public static void main(String[] args) { 5 6 String s1 = new String("abc"); 7 String s2 = new String("abc"); 8 String s3 = new String("abc"); 9 System.out.println(s1.hashCode()); 10 System.out.println(s2.hashCode()); 11 System.out.println(s3.hashCode()); 12 } 13 }
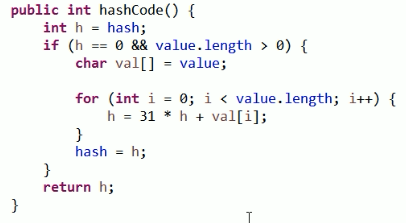
以上就是String重写之后的源码。
下面分析它:
注:
hash 默认是0
value 指的就是我们的对象 即调用这个方法的对象。 而且value 是个字符数组,我们知道String对象底层是个char [] 数组,这里的value 就是char [] 数组。

所以,String类对象的hash 值是自己算的。没有使用其父类Object 中的方法.hashCode()。
hash表的存储过程:

此时哈希表中只存了两个。
第一步:

第二步:

如果没有的话,就存入。
如果有相同的哈希值, 然后后面这个 要再调用.equals() 。
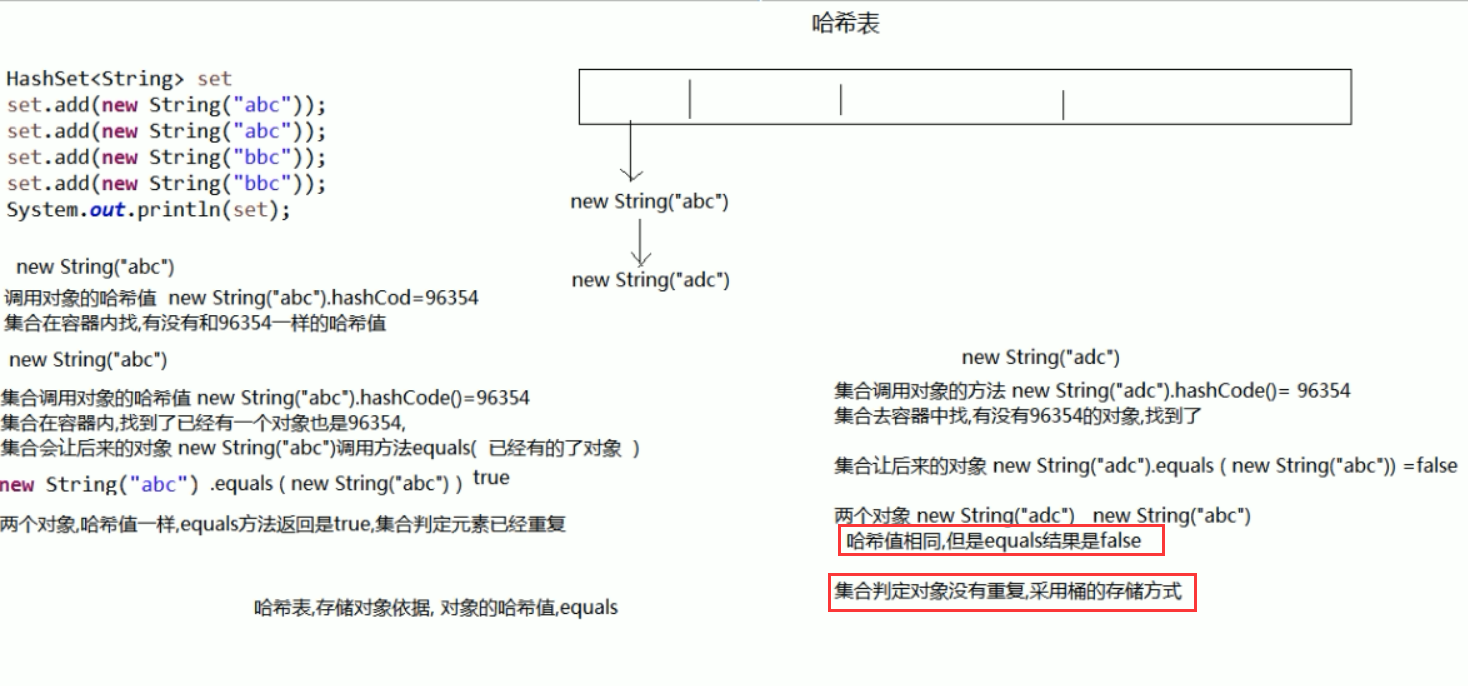
总结:
对象在存入哈希表的时候,
首先会看是否存在哈希值。
如果没有存在,直接存入。
如果已经有了哈希值。进入第二步程序---equals() 判断。
如果判断equals()相同的话,说明对象重复,最终结果不存入。
如果判断equals()不相同的话,说明对象不重复,将后来这个对象挂到已有对象的下面(桶的存储方式)。
注:不同的对象的hash值可能会相同的。
hash表存储自定义的对象:
1 package cn.zcb.demo01; 2 3 import java.util.HashSet; 4 5 public class Test { 6 public static void main(String[] args) { 7 HashSet<Person> hashSet = new HashSet<>(); 8 Person p1 = new Person("tom",18); 9 Person p2 = new Person("egon",20); 10 Person p3 = new Person("alex",32); 11 Person p4 = new Person("jane",38); 12 Person p5 = new Person("alex",32); 13 hashSet.add(p1); 14 hashSet.add(p2); 15 hashSet.add(p3); 16 hashSet.add(p4); 17 System.out.println(hashSet); 18 //此时如果 再次存入 tom 18 19 hashSet.add(p5); 20 System.out.println(hashSet); 21 22 } 23 }
1 package cn.zcb.demo01; 2 3 import java.util.HashSet; 4 5 public class Test { 6 public static void main(String[] args) { 7 HashSet<Person> hashSet = new HashSet<>(); 8 Person p1 = new Person("tom",18); 9 Person p2 = new Person("egon",20); 10 Person p3 = new Person("alex",32); 11 Person p4 = new Person("jane",38); 12 Person p5 = new Person("alex",32); 13 hashSet.add(p1); 14 hashSet.add(p2); 15 hashSet.add(p3); 16 hashSet.add(p4); 17 System.out.println(hashSet); 18 //此时如果 再次存入 tom 18 19 hashSet.add(p5); 20 System.out.println(hashSet); 21 22 /*分析上述结果*/ 23 System.out.println(p1.hashCode()); 24 System.out.println(p2.hashCode()); 25 System.out.println(p3.hashCode()); 26 System.out.println(p4.hashCode()); 27 System.out.println(p5.hashCode()); 28 /*发现它们的hashCode 都是不同的,所以都可以存入哈希表了*/ 29 30 31 32 } 33 }
现在的需求是解决这个事情,使得 相同名字和年龄的对象 不能存入。
1 package cn.zcb.demo01; 2 3 public class Person { 4 public String name; 5 public int age; 6 7 public Person(String name,int age){ 8 this.name = name; 9 this.age= age; 10 } 11 Person(){} 12 13 @Override 14 public String toString(){ 15 return this.name +" " +this.age+" "; 16 } 17 18 @Override 19 public int hashCode(){ 20 return 1; //所有的对象的hashCode 都相同, 21 } 22 // Object 23 //重写 Object 中的 equals方法 24 @Override 25 public boolean equals(Object obj){ 26 if(obj == null) 27 return false; 28 if(obj instanceof Person) { 29 Person p = (Person) obj; 30 return this.name.equals(p.name) && this.age == p.age; 31 } 32 return false; 33 } 34 35 }
1 package cn.zcb.demo01; 2 3 import java.util.HashSet; 4 5 public class Test { 6 public static void main(String[] args) { 7 HashSet<Person> hashSet = new HashSet<>(); 8 9 hashSet.add(new Person("a",10)); 10 hashSet.add(new Person("b",10)); 11 hashSet.add(new Person("c",10)); 12 hashSet.add(new Person("d",10)); 13 hashSet.add(new Person("a",10)); 14 15 System.out.println(hashSet); 16 17 18 } 19 }
但是,上面的代码是不行的,因为它每次返回的hash 值都是相同的,因此程序每次都会调用equals() ,这样效率是不高的。我们应该降低hash值相同的概率。这样效率才会上去。
1 package cn.zcb.demo01; 2 3 public class Person { 4 public String name; 5 public int age; 6 7 public Person(String name,int age){ 8 this.name = name; 9 this.age= age; 10 } 11 Person(){} 12 13 @Override 14 public String toString(){ 15 return this.name +" " +this.age+" "; 16 } 17 18 @Override 19 public int hashCode(){ 20 return this.name.hashCode() +this.age; //此时,hash值 相同的概率就会降低了 21 } 22 // Object 23 //重写 Object 中的 equals方法 24 @Override 25 public boolean equals(Object obj){ 26 if(obj == null) 27 return false; 28 if(obj instanceof Person) { 29 Person p = (Person) obj; 30 return this.name.equals(p.name) && this.age == p.age; 31 } 32 return false; 33 } 34 35 }
但是,它还是会有相等的情况。例如: name="a" age =10 和 name="b" age =9
我们可以再次降低hash值相同的概率:给age 乘上一个不是0 不是1 的任何数都可以降低概率。
1 package cn.zcb.demo01; 2 3 public class Person { 4 public String name; 5 public int age; 6 7 public Person(String name,int age){ 8 this.name = name; 9 this.age= age; 10 } 11 Person(){} 12 13 @Override 14 public String toString(){ 15 return this.name +" " +this.age+" "; 16 } 17 18 @Override 19 public int hashCode(){ 20 return this.name.hashCode() +this.age*55; //此时,hash值 相同的概率会 再次降低的。 21 } 22 // Object 23 //重写 Object 中的 equals方法 24 @Override 25 public boolean equals(Object obj){ 26 if(obj == null) 27 return false; 28 if(obj instanceof Person) { 29 Person p = (Person) obj; 30 return this.name.equals(p.name) && this.age == p.age; 31 } 32 return false; 33 } 34 35 }
注:此时,即便两个不同的对象hash值相等了,它们也仅仅是突破了第一道关卡,后面还有终极boss ,equals()等着呢!!!
Set接口的实现类--LinkedHashSet类:
它是继承自 HashSet 类.。 肯定也是Set接口的实现类。

它的特点是:无索引,有序,不可重复。
它的父类 HashSet 的特点是:无索引,无需,不可重复,
ArrayList 的特点是:索引,有序,可重复。
1 package cn.zcb.demo01; 2 3 import java.util.LinkedHashSet; 4 5 public class Test { 6 public static void main(String[] args) { 7 8 LinkedHashSet<String> linkedHashSet = new LinkedHashSet<>(); 9 linkedHashSet.add("tom"); 10 linkedHashSet.add("egon"); 11 linkedHashSet.add("alex"); 12 linkedHashSet.add("jane"); 13 linkedHashSet.add("egon"); 14 15 System.out.println(linkedHashSet); 16 17 } 18 }
判断集合元素唯一的原理:


add是 有返回值的。在HashSet 中add也可以用于判断是否有元素的重复。
补:
Java 中的八种基本类型的包装类 基本都实现了 hashCode() 和 equals() 方法,为的就是放入Set中的时候,不放入重复的元素。
所以,对于我们的自定义类型,如果想要去掉重复的元素放入Set中,就要重写.hashCode()和 equals() 方法。
面试题:
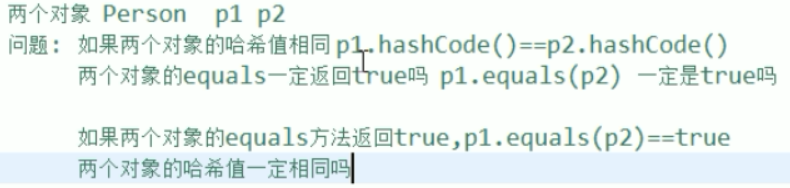
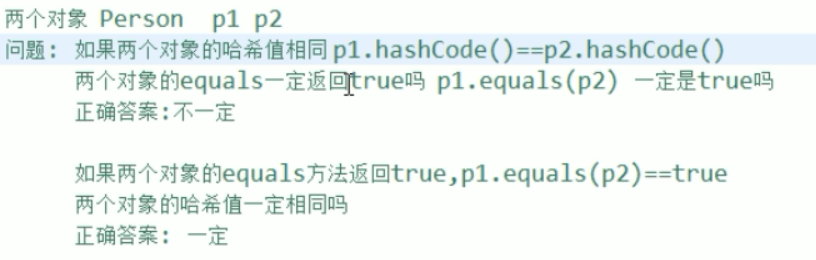
第二个之所以是一定,因为规定了如果equals() 相等的话,那么.hashCode()要相等。
但是,但equals()不相等,则不作要求。
总结:equals()是终极boss ,我tm equals()都相等了,你一个小小的hashCode ()还想搞什么卵蛋。