HTTPwiki介绍:
超文本传输协议
HyperText Transfer Protocol
设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法。通过HTTP或者HTTPS协议请求的资源由统一资源标识符(Uniform Resource Identifiers,URI)来标识。
HTTP的发展是万维网协会(World Wide Web Consortium,W3C)和互联网工程任务组(Internet Engineering Task Force,IETF)合作的结果,(他们)最终发布了一系列的RFC[1], 其中最著名的是1999年6月公佈的 RFC 2616,定義了HTTP協議中現今廣泛使用的一個版本——HTTP 1.1。
2014年12月互联网工程任务组(IETF)的Hypertext Transfer Protocol Bis(httpbis)工作小组将HTTP/2标准提议递交至IESG进行讨论[1],于2015年2月17日被批准。[2] HTTP/2标准于2015年5月以RFC 7540正式发表,取代HTTP 1.1成为HTTP的实现标准。
协议概述:
HTTP是一个客户端终端(用户)和服务器端(网站)请求和应答的标准(TCP)。通过使用Web浏览器、网络爬虫或者其它的工具,客户端发起一个HTTP请求到服务器上指定端口(默认端口为80)。我们称这个客户端为用户代理(user agent)。应答的服务器上存储着一些资源,比如HTML文件和图像。我们称这个应答服务器为源服务器(origin server)。在用户代理和源服务器中间可能存在多个「中间层」,比如代理伺服器、网关或者隧道(tunnel)。
尽管TCP/IP协议是互联网上最流行的应用,HTTP协议中,并没有规定必须使用它或它支持的层。事实上,HTTP可以在任何互联网协议上,或其他网络上实现。HTTP假定其下层协议提供可靠的传输。因此,任何能够提供这种保证的协议都可以被其使用。因此也就是其在TCP/IP协议族使用TCP作为其传输层。
通常,由HTTP客户端发起一个请求,建立一个到服务器指定端口(默认是80端口)的TCP连接。HTTP服务器则在那个端口监听客户端的请求。一旦收到请求,服务器会向客户端返回一个状态,比如"HTTP/1.1 200 OK",以及返回的内容,如请求的文件、错误消息、或者其它信息。
请求消息(Request Message):
发出的请求信息包括以下几个
1,请求行
例如GET /images/logo.gif HTTP/1.1,表示从/images目录下请求logo.gif这个文件。
2,(请求)头,
例如Accept-Language: en
3,空行
4,其他消息体
请求行和标题必须以<CR><LF>作为结尾。空行内必须-{只}-有<CR><LF>而无其他空格。在HTTP/1.1协议中,所有的请求头,除Host外,都是可选的。
请求方法:
HTTP/1.1协议中共定义了八种方法(也叫“动作”)来以不同方式操作指定的资源:
OPTIONS:这个方法可使服务器传回该资源所支持的所有HTTP请求方法。用 * 来代替资源名称,向Web服务器发送OPTIONS请求,可以测试服务器功能是否正常运作。
HEAD:与GET方法一样,都是向服务器发出指定资源的请求。只不过服务器将不传回资源的本文部份。它的好处在于,使用这个方法可以在不必传输全部内容的情况下,就可以获取其中「关于该资源的信息」(元信息或称元资料)。
GET:向指定的资源发出「显示」请求。使用GET方法应该只用在读取资料,而不应当被用于产生「副作用」的操作中,例如在Web Application中。其中一个原因是GET可能会被网络爬虫等随意访问。参见安全方法
POST:向指定资源提交数据,请求服务器进行处理(例如提交表单或者上传文件)。数据被包含在请求本文中。这个请求可能会建立新的资源或修改现有资源,或二者皆有。
PUT:向指定资源位置上传其最新内容。
DELETE:请求服务器删除Request-URI所标识的资源。
TRACE:回显服务器收到的请求,主要用于测试或诊断。
CONNECT:HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。通常用于SSL加密伺服器的连结(经由非加密的HTTP代理伺服器)。
方法名称是区分大小写的。当某个请求所针对的资源不支持对应的请求方法的时候,服务器应当返回状态码405(Method Not Allowed),当服务器不认识或者不支持对应的请求方法的时候,应当返回状态码501(Not Implemented)。
HTTP服务器至少应该实现GET和HEAD方法,其他方法都是可选的。当然,所有的方法支持的实现都应当符合下述的方法各自的语义定义。此外,除了上述方法,特定的HTTP服务器还能够扩展自定义的方法。例如:
PATCH(由 RFC 5789 指定的方法):用于将局部修改应用到资源。
HTTPS:
目前有两种方法来建立安全超文本协议连接:HTTPS URI方案和HTTP 1.1请求头(由 RFC 2817 引入)。由于浏览器对后者几乎没有任何支持,因此HTTPS URI方案仍是建立安全超文本协议连接的主要手段。安全超文本连接协议使用https://代替http:// 。
版本:
超文本传输协议已经演化出了很多版本,它们中的大部分都是向下兼容的。在 RFC 2145 中描述了HTTP版本号的用法。客户端在请求的开始告诉服务器它采用的协议版本号,而后者则在响应中采用相同或者更早的协议版本。
0.9
已过时。只接受GET一种请求方法,没有在通讯中指定版本号,且不支持请求头。由于该版本不支持POST方法,因此客户端无法向服务器传递太多信息。
HTTP/1.0
这是第一个在通讯中指定版本号的HTTP协议版本,至今仍被广泛采用,特别是在代理服务器中。
HTTP/1.1
持久连接被默认采用,并能很好地配合代理服务器工作。还支持以管道方式在同时发送多个请求,以便降低线路负载,提高传输速度。
HTTP/1.1相较于HTTP/1.0协议的区别主要体现在:
缓存处理
带宽优化及网络连接的使用
错误通知的管理
消息在网络中的发送
互联网地址的维护
安全性及完整性
HTTP/2
当前版本,于2015年5月作为互联网标准正式发布。
状态码:
所有HTTP响应的第一行都是状态行,依次是当前HTTP版本号,3位数字组成的状态代码,以及描述状态的短语,彼此由空格分隔。
状态代码的第一个数字代表当前响应的类型:
1xx消息——请求已被服务器接收,继续处理
2xx成功——请求已成功被服务器接收、理解、并接受
3xx重定向——需要后续操作才能完成这一请求
4xx请求错误——请求含有词法错误或者无法被执行
5xx服务器错误——服务器在处理某个正确请求时发生错误
虽然 RFC 2616 中已经推荐了描述状态的短语,例如"200 OK","404 Not Found",但是WEB开发者仍然能够自行决定采用何种短语,用以显示本地化的状态描述或者自定义信息。
持续连接:
在HTTP 0.9和1.0使用非持续连接,在非持续连接下,每个tcp只连接一个web对象,连接在每个请求-回应对后都会关闭,一个连接可被多个请求重复利用的保持连接机制被引入。这种连接持续化显著地减少了请求延迟,因为客户不用在首次请求后再次进行TCP交互确认建立连接。现在在HTTP 1.1使用持续连接,不必为每个web对象创建一个新的连接,一个连接可以传送多个对象。 HTTP1.1还进行了带宽优化,例如1.1引入了分块传输编码来允许流化传输持续连接上发送的内容,取代原先的buffer式传输。HTTP管道允许客户在上一个回应被收到前发送多重请求从而进一步减少了延迟时间。
另一项协议的改进是byte serving(字节服务),允许服务器根据客户的请求仅仅传输资源的一部分。
协议例子:
下面是一个HTTP客户端与服务器之间会话的例子,运行于www.google.com,端口80
客户端请求:
GET / HTTP/1.1
Host: www.google.com
(末尾有一个空行。第一行指定方法、资源路径、协议版本;第二行是在1.1版里必带的一个header作用指定主机)
服务器应答:
HTTP/1.1 200 OK
Content-Length: 3059
Server: GWS/2.0
Date: Sat, 11 Jan 2003 02:44:04 GMT
Content-Type: text/html
Cache-control: private
Set-Cookie: PREF=ID=73d4aef52e57bae9:TM=1042253044:LM=1042253044:S=SMCc_HRPCQiqy
X9j; expires=Sun, 17-Jan-2038 19:14:07 GMT; path=/; domain=.google.com
Connection: keep-alive
(紧跟着一个空行,并且由HTML格式的文本组成了Google的主页)
在HTTP1.0,单一TCP连接内仅执行一个“客户端发送请求—服务器发送应答”周期,之后释放TCP连接。在HTTP1.1优化支持持续活跃连接:客户端连续多次发送请求、接收应答;批次多请求时,同一TCP连接在活跃(Keep-Live)间期内复用,避免重复TCP初始握手活动,减少网络负荷和响应周期。此外支持应答到达前继续发送请求(通常是两个),称为「流线化」(stream)。
注:
[1],关于RFC:
请求修正意见书(英语:-{Request For Comments}-,缩写为RFC),是由互联网工程任务组(IETF)发布的一系列备忘录。文件收集了有关网际网路相关资讯,以及UNIX和网际网路社群的软体文件,以编号排定。目前RFC文件是由网际网路协会(ISOC)赞助发行。
RFC始于1969年,由斯蒂芬·克罗克用来记录有关ARPANET开发的非正式文档,最终演变为用来记录互联网规范、协议、过程等的标准文件。基本的网际网路通讯协定都有在RFC文件内详细说明。RFC文件还额外加入许多的论题在标准内,例如对于网际网路新开发的协定及发展中所有的记录。
http:
http的请求方法:
1,GET请求
优点:比较便捷。
缺点:
不安全,是明文,就显示在地址栏的后面。
参数的长度有限制。
2,POST请求
优点:
比较安全
参数 长度没有没有限制
可以上传文件
3,PUT请求
4,DELETE请求 (删除一些信息)
5,HEAD请求(它返回请求头的信息)
......
大部分用前两种请求方法。
发送网络请求的过程:
我们在发送网络请求的时候,有时需要带一定的数据,(也可以不带)。就是将一些参数发送给服务器,它才返回给我们资源。这些需要发送的数据就是放在请求头(Request Headers)里,正常情况,服务器也会返回,服务器返回的数据在 响应头(Response Headers)中。
例子:我们在www.sougou.com中搜索 “你好”.
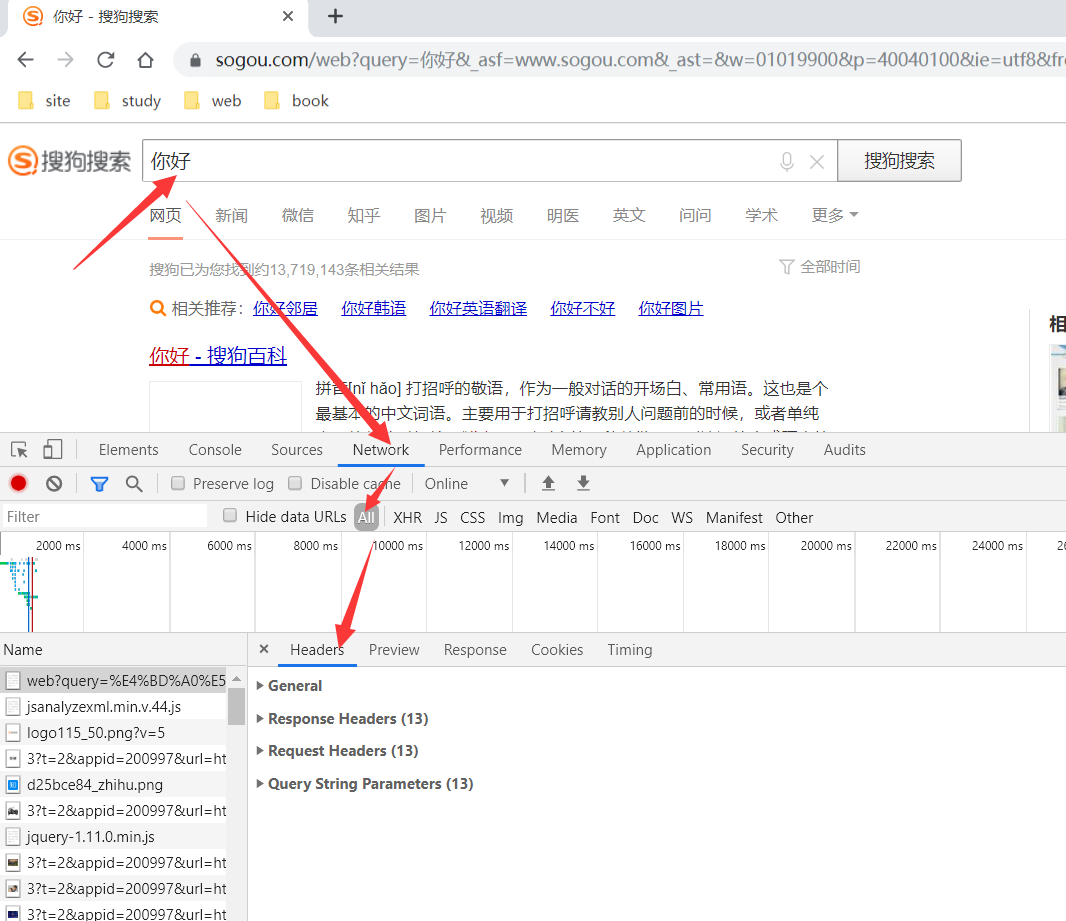
这里面最重要的是Request Headers,
Request Headers:

第一个Accept: 它是指定了 待会儿服务器返回回来的数据格式。这里是text/html ,是返回回来文本或网页等格式。
第二个Accept-Encoding:它是指如果数据太大,可以压缩之后返回。格式gzip
第三个Accept-Language:返回给我中文
第五个Connection:长链接(持续连接)还是 短链接 ,这里是长链接。
第六个Cookie(重要): 常用与登录网站信息的缓冲,再次登录可以直接在Cookie 中获取登录信息。
第七个Host:域名,我们的目标服务器的域名。它对应着ip地址。
第八个Referer: 标记着从哪个网页跳转过来的。
User-Agent:用户和浏览器的信息,在计算机科学中,用户代理(英语:-{User Agent}-)指的是代表使用者行为的软件(软件代理程序)所提供的对自己的一个标识符。
Response Headers:

第一个Cache-Control:是缓存的大小,
第二个Connection :也是长连接,和Request Headers 中的是对应的。
第三个Content-Encoding:返回的是个gzip 文件
第四个Content-Type :返回的是text/html ; 编码格式是utf-8.
第五个Date: 发送网络请求的时间,(和我们时间差8个小时)
第六个Expires:发送请求结束时间
第七个Server: 服务器的信息
第八个Set-Cookie:怎么设置Cookie
我们基本不用Reponse Headers 的!
Query String Parameters:
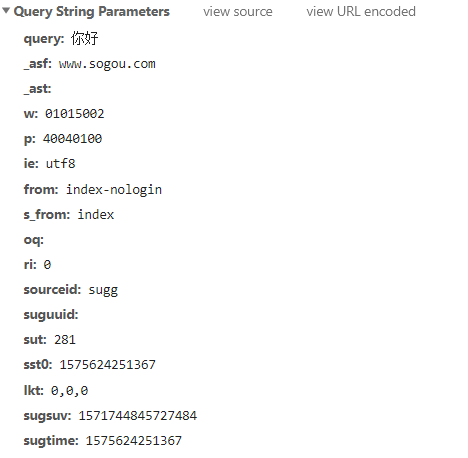
它里面放的是一些参数,比较重要的是 query :它是携带的参数。
如果我们不带参数(例如:在地址栏单纯输入 www.sougou.com),此时就没有这一项(Query String Parameters)的。
扩展:
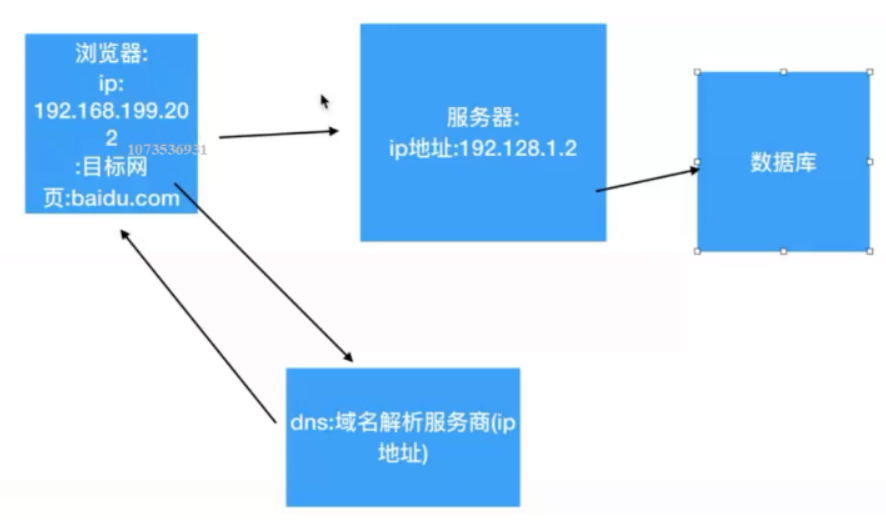
我们平时输入的www.baidu.com ,其实它是个包装了 ip地址的东西,具体过程如下:
我们首先在我们的浏览器中输入www.baidu.com (这只是个域名,不是真正的ip地址) ,
浏览器会先去 DNS(域名解析服务商)[1]解析获取ip地址,DNS将解析好的百度的ip地址返回给浏览器,
然后,浏览器通过百度服务器的ip地址 访问百度。
[1]:域名系统(服务)协议(DNS)是一种分布式网络目录服务,主要用于域名与 IP 地址的相互转换,以及控制因特网的电子邮件的发送。
爬虫入门:
使用代码模拟用户 去批量地发送网络请求,去批量的获取数据。
爬虫相关:


因为爬虫是模拟用户去爬取数据,如果爬取用户也不能访问的就是黑客(Hacker)了。

爬虫的分类:
1,通用爬虫(搜索引擎)
就是直接使用搜索引擎搜索,
它的优势:开放性,速度快;
劣势:目标不明确,还有返回给我们的大部分(90%)都是我们不需要的。
其实它的核心就是 搜索引擎不是很清楚 用户的需求。
2,聚焦爬虫(我们学习的)
优点:目标明确,(我们需要1张图片,就返回1张,需要100张就返回100张);返回的内容基本都是用户所需要的。
这里又有两种爬虫:
增量式爬虫:它有翻页的功能(我们使用聚焦爬虫时,如果不指定增量式的话,它默认是只爬取第一页的内容!),增量式可以从头爬到尾。
Deep 深度爬虫:
主要爬取两类数据:静态数据(Html Css); 动态数据(JS 、加密的JS)
robots协议:
robots.txt(统一小写)是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络搜索引擎的漫游器(又称网络爬虫),此网站中的哪些内容是不应被搜索引擎的漫游器获取的,哪些是可以被漫游器获取的。因为一些系统中的URL是大小写敏感的,所以robots.txt的文件名应统一为小写。robots.txt应放置于网站的根目录下。如果想单独定义搜索引擎的漫游器访问子目录时的行为,那么可以将自定的设置合并到根目录下的robots.txt,或者使用robots元数据(Metadata,又称元数据)。
robots.txt协议并不是一个规范,而只是约定俗成的,所以并不能保证网站的隐私。注意robots.txt是用字符串比较来确定是否获取URL,所以目录末尾有与没有斜杠“/”表示的是不同的URL。robots.txt允许使用类似"Disallow: *.gif"这样的通配符[1][2]。
例子
允许所有的机器人:
User-agent: *
Disallow:
另一写法
User-agent: *
Allow:/
仅允许特定的机器人:(name_spider用真实名字代替)
User-agent: name_spider
Allow:
拦截所有的机器人:
User-agent: *
Disallow: /
禁止所有机器人访问特定目录:
User-agent: *
Disallow: /cgi-bin/
Disallow: /images/
Disallow: /tmp/
Disallow: /private/
仅禁止坏爬虫访问特定目录(BadBot用真实的名字代替):
User-agent: BadBot
Disallow: /private/
禁止所有机器人访问特定文件类型[2]:
User-agent: *
Disallow: /*.php$
Disallow: /*.js$
Disallow: /*.inc$
Disallow: /*.css$
网站是否允许爬虫进行爬取数据。(一般是大型通用爬虫(搜索引擎)遵守,聚焦爬虫一般也都不遵守)。
查看robots协议(例如淘宝的robots协议):
https://www.taobao.com/robots.txt
反网络爬虫:

爬虫的工作原理:
1,首先确定抓去目标(确定url)(核心在找,有的容易找到,有的就不容易找到了)。
2,使用Python代码发送请求获取数据(用其他语言也可以 Java Go).
3,解析获取到的数据(有时也很难)。
如果有新的目标,找到新的目标(url),回到第一步(自动化,抓取所有的数据)。
最后一步:
4,数据持久化(例如,保存到本地,存到数据库)。
下面将的知识点:
Python原生提供的模块:urllib.request.
第三方模块:request
数据解析:xpath , bs4
案例:
小案例 (没带参数):


1 import urllib.request 2 3 def load_data(): 4 url = "http://www.baidu.com/" # 后面多的一个斜杠 是自动加的。没事儿... 5 6 # 1 使用request.urlopen()打开url 链接。 7 ret = urllib.request.urlopen(url) 8 # 返回的ret 是 http 响应的对象 9 # print(ret) 10 11 # 2 读取内容 是bytes类型 12 data = ret.read() 13 # print(data) 14 # 将对应的bytes转为字符串 使用 .decode() 方法,可以将字节 转为 string 15 data_str = data.decode("utf8") 16 # print(data_str) 可以将data_str 写入到 文件中 17 18 19 with open("d:\test.html", "w",encoding="utf8") as f: 20 f.write(data_str) 21 pass 22 23 24 if __name__ == '__main__': 25 load_data() 26 pass