互斥(acquire后 必须release )锁 和 递归锁:
为什么线程中还需要有锁:
我们知道cpython解释器 有一个GIL 锁,同一时刻,只会有一个线程可以被cpu调度。
主要还是因为取到数据 到 处理完之后 存回去 是花费的时间太长了。
线程中的数据不安全现象:


1 from threading import Thread,Lock 2 3 def test(*args): 4 global num 5 num -= 1 6 7 if __name__ == '__main__': 8 num = 100 9 lock = Lock() 10 print("原始 num :",num) 11 thread_lists = [] 12 for i in range(100): 13 thread = Thread(target=test,args=(lock,)) 14 thread_lists.append(thread) 15 thread.start() 16 17 for thread in thread_lists: 18 thread.join() 19 print("线程执行完之后的 num",num )
1 from threading import Thread,Lock 2 import time 3 4 def test(*args): 5 global num 6 ret = num - 1 7 time.sleep(0.1) 8 num = ret 9 10 if __name__ == '__main__': 11 num = 100 12 lock = Lock() 13 print("原始 num :",num) 14 thread_lists = [] 15 for i in range(100): 16 thread = Thread(target=test,args=(lock,)) 17 thread_lists.append(thread) 18 thread.start() 19 20 for thread in thread_lists: 21 thread.join() 22 print("线程执行完之后的 num",num )
1 from threading import Thread, Lock 2 import time 3 4 5 def test(*args): 6 global num 7 args[0].acquire() 8 ret = num - 1 9 time.sleep(0.1) 10 num = ret 11 args[0].release() 12 13 14 if __name__ == '__main__': 15 num = 100 16 lock = Lock() 17 print("原始 num :", num) 18 thread_lists = [] 19 for i in range(100): 20 thread = Thread(target=test, args=(lock,)) 21 thread_lists.append(thread) 22 thread.start() 23 24 for thread in thread_lists: 25 thread.join() 26 print("线程执行完之后的 num", num)
死锁现象:
使用互斥锁 构建死锁现象:
1 from threading import Thread, Lock 2 import time 3 4 def test1(*args): 5 args[0].acquire() 6 print("锁1已经上锁...") 7 8 time.sleep(5) 9 args[1].acquire() 10 11 12 def test2(*args): 13 args[1].acquire() 14 print("锁2已经上锁...") 15 time.sleep(2) 16 print("下面对 锁1 上锁") 17 args[1].acquire() 18 19 if __name__ == '__main__': 20 lock1 = Lock() 21 lock2 = Lock() 22 thread1 = Thread(target=test1, args=(lock1,lock2)) 23 thread2 = Thread(target=test2, args=(lock1,lock2)) 24 25 thread1.start() 26 time.sleep(1) 27 thread2.start()
死锁常出现的 条件:
1,有多把锁
2,当一个线程抢到一个锁之后,还想要抢其他的锁。
递归锁:
一旦使用了两把锁,此时就有可能出现死锁现象,
所以,使用多把锁,可以考虑使用递归锁。

递归锁可以 多次 acquire 上锁,
互斥锁可以解决 多个锁产生了死锁问题。

队列:
进程中的队列是 from multiprocessing import Queue
我们这里的线程 导入的是:
import queue
然后,queue里有 Queue这个类。

线程池:
我们知道 multiprocessing 中有个 ,但是在threading 中没有!
我们要使用线程池,现在可以借助另一个模块: concurrent.futures 模块。(这个模块里既有线程池的,其实也有进程池。)

1 from concurrent.futures import ThreadPoolExecutor 2 import time 3 4 def test(*args,**kwargs): 5 print(str(args[0]),"我是线程...") 6 # print(args[1]) 7 # print(kwargs) 8 time.sleep(1) 9 10 if __name__ == '__main__': 11 threadPool = ThreadPoolExecutor(5) #线程池中 最多有5个线程 12 13 for i in range(20): 14 threadPool.submit(test,i,1,name="tom") 15 16 threadPool.shutdown() #相当于 进程池 中的pool.close() 和 pool.join() 两步 17 18 print("我是主线程")
回调函数:
与进程池不同,进程池的回调函数是在主进程中执行的,
线程池的回调函数是在子线程中执行的。
1 from concurrent.futures import ThreadPoolExecutor 2 import time 3 4 def test(*args,**kwargs): 5 print(str(args[0]),"我是线程...") 6 # print(args[1]) 7 # print(kwargs) 8 time.sleep(1) 9 10 return "tom" 11 12 def call_bk(*args): 13 # print(args) #(<Future at 0x2e3c399ad68 state=finished returned NoneType>,) 可以用.result() 获取 14 print(args[0].result()) 15 16 17 18 if __name__ == '__main__': 19 threadPool = ThreadPoolExecutor(5) #线程池中 最多有5个线程 20 21 for i in range(20): 22 threadPool.submit(test,i,1,name="tom").add_done_callback(call_bk) 23 24 threadPool.shutdown() #相当于 进程池 中的pool.close() 和 pool.join() 两步 25 print("我是主线程")

总结:
线程启动也是有上限的,我们知道在进程池的时候,我们一般使用:cpu 数 +1
这里的线程池,我们可以5*cpu数 +1
以后使用 进程池 和 线程池的时候,推荐使用的是这个模块 concurrent.futures 。它的进程池 和 线程池 的接口都是一致的。

开4个进程 ,每个进程开5个线程,那就是80个并发。
1,使用concurrent.futures 开多进程
1 from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor 2 import time 3 4 def test(*args,**kwargs): 5 print(str(args[0]),"我是子进程...") 6 time.sleep(1) 7 return "tom" 8 9 def call_bk(*args): 10 print(args[0].result() ) 11 12 13 14 if __name__ == '__main__': 15 processPool = ProcessPoolExecutor(5) #进程池 5个! 16 for i in range(20): 17 processPool.submit(test,i,1,name="tom").add_done_callback(call_bk) 18 19 processPool.shutdown() 20 print("我是主进程")
2,使用concurrent.futures 开多线程:
1 from concurrent.futures import ThreadPoolExecutor,ThreadPoolExecutor 2 import time 3 4 def test(*args,**kwargs): 5 print(str(args[0]),"我是子线程...") 6 time.sleep(1) 7 return "tom" 8 9 def call_bk(*args): 10 print(args[0].result() ) 11 12 if __name__ == '__main__': 13 threadPool = ThreadPoolExecutor(5) #进程池 5个! 14 for i in range(20): 15 threadPool.submit(test,i,1,name="tom").add_done_callback(call_bk) 16 17 threadPool.shutdown() 18 print("我是主线程")
协程:
我们知道:
1,进程是计算机最小的资源分配单位,
2,线程是cpu 调度的最小单位,
协程的本质:一个线程 在多个任务间来回切换。 而且,操作系统和 cpu 是感受不到协程的存在的。
但是,不停地切换任务也是 很浪费时间的,所以单纯的协程 也是不能提高效率的。
1 import time 2 def producer(): 3 for i in range(100): 4 time.sleep(0.1) 5 yield i 6 7 def test(): 8 for j in producer(): 9 print(j) 10 if __name__ == '__main__': 11 test()
我们可以更好的利用协程:
首先:明确协程最大的优势:是可以将一个线程的执行 明确的区分开!!!
假如一个线程中有一个任务,如果其中一个任务阻塞了,那么这个线程也就不能工作了。
但是,我们可以让这个线程取执行两个任务,如果两个任务都不阻塞,确实,这会消耗更多时间。但是,网络编程中大多数都是会阻塞的。所以,如果线程中开两个任务,如果其中一个阻塞了,那么这个线程就会去执行另一个任务了。
cpu 是看不到协程的,所以,只有协程中有任务没有阻塞,cpu 角度看过来都是线程在工作,此时,就更充分的利用了cpu !
因此,协程是很有用的,特别是针对爬虫请求。
使用协程 的三个好处:

总结: 给操作系统造成一种假象,我这个线程一直在忙碌!!!
协程 模块:
1,greenlet (更底层)
2,gevent (我们以后用的,其实gevent 是在greenlet 的基础上封装来的~)
1 from greenlet import greenlet 2 3 def eat(): 4 print("eating 1") 5 g2.switch() 6 print("eating 2") 7 8 def play(): 9 print("palying 1") 10 print("palying 2") 11 g1.switch() 12 13 if __name__ == '__main__': 14 g1 = greenlet(eat) 15 g2 = greenlet(play) 16 17 g1.switch()
1 from greenlet import greenlet 2 import time 3 4 def eat(): 5 print("eating 1") 6 g2.switch() 7 time.sleep(1) #模拟阻塞, 上面切换到g2之后,切换回来之后,还是继续睡1s, 这也是greenlet 的缺陷,我们想要的是 切换到g2后,然后,就开始睡1s,切换回来之后,就不用再睡了 8 print("eating 2") 9 10 def play(): 11 print("palying 1") 12 print("palying 2") 13 g1.switch() 14 15 if __name__ == '__main__': 16 g1 = greenlet(eat) 17 g2 = greenlet(play) 18 19 g1.switch()
因为 greenlet 只是个底层的模块,它只能帮我们做一些切换,切换回来之后,还是要继续阻塞!!!
gevent 的使用:
1 import gevent 2 import time 3 4 def eat(): 5 print("eating 1") 6 time.sleep(1) 7 print("eating 2") 8 9 def play(): 10 print("palying 1") 11 print("palying 2") 12 13 if __name__ == '__main__': # gevent 做的事情是,可以自动检测是否阻塞,一阻塞就切换 14 g1 = gevent.spawn(eat) #开启一个协程,当阻塞时,会切换 15 g2 = gevent.spawn(play) #再开个协程,当阻塞时,会切换。 16
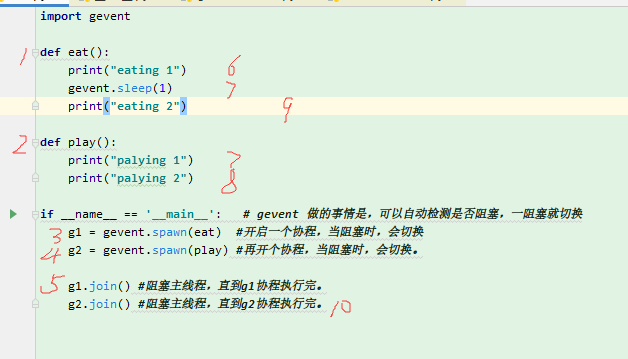
1 import gevent 2 import time 3 4 def eat(): 5 print("eating 1") 6 time.sleep(1) 7 print("eating 2") 8 9 def play(): 10 print("palying 1") 11 print("palying 2") 12 13 if __name__ == '__main__': # gevent 做的事情是,可以自动检测是否阻塞,一阻塞就切换 14 g1 = gevent.spawn(eat) #开启一个协程,当阻塞时,会切换 15 g2 = gevent.spawn(play) #再开个协程,当阻塞时,会切换。 16 17 g1.join() #阻塞主线程,直到g1协程执行完。 18 g2.join() #阻塞主线程,直到g2协程执行完。
可以用gevent 中自带的sleep()
程序执行的大概步骤:
但是,我们还是想要是用time.sleep() ,这时可以打个补丁:
1 from gevent import monkey 2 3 monkey.patch_all() #把 time 写在它下面,然后gevent 就能认识time.sleep() 了。 4 import gevent 5 import time 6 7 8 def eat(): 9 print("eating 1") 10 time.sleep(1) 11 print("eating 2") 12 13 def play(): 14 print("palying 1") 15 print("palying 2") 16 17 if __name__ == '__main__': # gevent 做的事情是,可以自动检测是否阻塞,一阻塞就切换 18 g1 = gevent.spawn(eat) #开启一个协程,当阻塞时,会切换 19 g2 = gevent.spawn(play) #再开个协程,当阻塞时,会切换。 20 21 g1.join() #阻塞主线程,直到g1协程执行完。 22 g2.join() #阻塞主线程,直到g2协程执行完。
补充 可以批量进行阻塞 主线程:
1 from gevent import monkey 2 3 monkey.patch_all() #把 time 写在它下面,然后gevent 就能认识time.sleep() 了。 4 import gevent 5 import time 6 7 8 def eat(): 9 print("eating 1") 10 time.sleep(1) 11 print("eating 2") 12 13 def play(): 14 print("palying 1") 15 print("palying 2") 16 17 if __name__ == '__main__': # gevent 做的事情是,可以自动检测是否阻塞,一阻塞就切换 18 g1 = gevent.spawn(eat) #开启一个协程,当阻塞时,会切换 19 g2 = gevent.spawn(play) #再开个协程,当阻塞时,会切换。 20 21 gevent.joinall([g1,g2])
获取协程的返回值:
通过属性.value()
如下:
1 from gevent import monkey 2 3 monkey.patch_all() 4 import gevent 5 import time 6 7 8 def eat(): 9 print("eating 1") 10 time.sleep(1) 11 print("eating 2") 12 return "tom" 13 14 def play(): 15 print("palying 1") 16 print("palying 2") 17 return "egon" 18 19 if __name__ == '__main__': # gevent 做的事情是,可以自动检测是否阻塞,一阻塞就切换 20 g1 = gevent.spawn(eat) #开启一个协程,当阻塞时,会切换 21 g2 = gevent.spawn(play) #再开个协程,当阻塞时,会切换。 22 23 gevent.joinall([g1,g2]) 24 25 print(g1.value) 26 print(g2.value)
协程 实例 --爬虫:
1 import time 2 import requests 3 4 url_lists = [ 5 "http://www.baidu.com", 6 "http://www.baidu.com", 7 "http://www.baidu.com", 8 "http://www.baidu.com", 9 "http://www.baidu.com", 10 "http://www.sina.com", 11 "http://www.4399.com", 12 "http://www.4399.com", 13 "http://www.4399.com", 14 "http://www.4399.com", 15 "http://www.4399.com", 16 "http://www.4399.com", 17 ] 18 19 def send_url(url): 20 response = requests.get(url) 21 22 if response.status_code == 200: 23 print(len(response.text)) 24 25 if __name__ == '__main__': 26 t1 = time.time() 27 for url in url_lists: 28 send_url(url) 29 print("总耗时: ",time.time() - t1) #总耗时: 1.0108890533447266
1 import requests 2 from gevent import monkey 3 monkey.patch_all() 4 import gevent 5 import time 6 7 8 url_lists = [ 9 "http://www.baidu.com", 10 "http://www.baidu.com", 11 "http://www.baidu.com", 12 "http://www.baidu.com", 13 "http://www.baidu.com", 14 "http://www.sina.com", 15 "http://www.4399.com", 16 "http://www.4399.com", 17 "http://www.4399.com", 18 "http://www.4399.com", 19 "http://www.4399.com", 20 "http://www.4399.com", 21 ] 22 23 def send_url(url): 24 response = requests.get(url) 25 26 if response.status_code == 200: 27 print(len(response.text)) 28 29 if __name__ == '__main__': 30 t1 = time.time() 31 32 g_lists = [] #协程列表 33 for url in url_lists: 34 g = gevent.spawn(send_url,url) #给 协程传参。 35 g_lists.append(g) 36 37 #批量阻塞 主线程 38 gevent.joinall(g_lists) 39 print("总耗时: ",time.time() - t1) #总耗时: 0.8591735363006592
1 import requests 2 from gevent import monkey 3 monkey.patch_all() 4 import gevent 5 import time 6 7 # base_url = http://college.gaokao.com/school/tinfo/1/result/1/1/ 8 url_lists = [] 9 for i in range(1,32): #总共31 个网页 10 url_lists.append("http://college.gaokao.com/school/tinfo/{}/result/1/1/".format(i)) 11 12 13 def send_url(url): 14 myHeaders = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"} 15 response = requests.get(url,headers = myHeaders) 16 17 if response.status_code == 200: 18 print(len(response.text)) 19 20 if __name__ == '__main__': 21 t1 = time.time() 22 23 g_lists = [] #协程列表 24 for url in url_lists: 25 g = gevent.spawn(send_url,url) #给 协程传参。 26 g_lists.append(g) 27 28 #批量阻塞 主线程 29 gevent.joinall(g_lists) 30 print("总耗时: ",time.time() - t1) #总耗时: 0.2811870574951172
总之 协程就是快的很!
爬虫,主要还是要用 gevent啊,厉害!

这时就可以同时2w 个任务了。
有关于并发的内容:

协程:
在Python 中协程的地位 是不可撼动的,
在爬虫的时候,协程 是访问网页的常用工具。