分类问题
在机器学习中,主要有两大类问题,分别是分类和回归。下面我们先主讲分类问题。
MINST
这里我们会用MINST数据集,也就是众所周知的手写数字集,机器学习中的 Hello World。sk-learn 提供了用于直接下载此数据集的方法:
from sklearn.datasets import fetch_openml minst = fetch_openml('mnist_784', version=1) minst.keys() >dict_keys(['data', 'target', 'feature_names', 'DESCR', 'details', 'categories', 'url'])
像这种sk-learn 下载的数据集,一般都有相似的字典结构,包括:
- DESCR:描述数据集
- data:包含一个数组,每行是一条数据,每列是一个特征
- target:包含一个数组,为label值
我们看一下这些数组:
X,y = minst['data'],minst['target'] X.shape, y.shape >((70000, 784), (70000,))
可以看到一共有 70000 张图片,每张图片包含784个特征。这是因为每张图包含28×28像素点,每个特征代表的是此像素点强度,取值范围从0(白)到255(黑)。我们先看一下其中一条数据。首先获取一条数据的特征向量,然后reshape到一个28×28 的数组,最后用matplotlib 的imshow() 方法显示即可:
import matplotlib as mpl import matplotlib.pyplot as plt some_digit = X[0] some_digit_image = some_digit.reshape(28, 28) plt.imshow(some_digit_image, cmap = mpl.cm.binary, interpolation="nearest") plt.axis("off") plt.show()
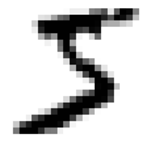
从图片来看,这个应该是数字5,我们可以通过label 进行验证:
y[0] >'5'
可以看到这个label的数值是 string,我们需要将它们转换成int:
import numpy as np y = y.astype(np.uint8) >array([5, 0, 4, ..., 4, 5, 6], dtype=uint8)
现在,我们初步了解了数据集。在训练之前,必须要将数据集分为训练集与测试集。这个MINST数据集已经做好了划分,前60000 为训练接,后10000为测试集,直接取用即可:
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
这个训练集已经做过了shuffle,基本可以确保k-折交叉验证的各个集合基本相似(例如不会出现某个折中缺失一些数字)。另一方面,有些学习算法对于训练数据的顺序比较敏感,所以对数据集进行shuffle的好处是避免数据的顺序对训练造成的影响。
训练二元分类器
我们先简化此问题,仅让我们的模型判断一个数字,例如5。这样的分类器称为二元分类器,仅能将数据分为两个类别:数字5和非数字5。下面我们为这类分类器创建label:
y_train_5 = (y_train == 5)
y_test_5 = (y_test == 5)
现在我们选择一个分类器并进行训练,可以先从一个随机梯度下降(Stochastic Gradient Descent,SGD) 分类器开始,使用sk-learn的SGDClassifer 类。这个分类器的优点是:能够高效地处理非常大的数据集。因为它每次均仅处理一条数据(也正因如此,SGD非常适合online learning 场景)。下面创建一个SGDClassifer 并在整个训练集上进行训练:
from sklearn.linear_model import SGDClassifier sgd_clf = SGDClassifier(random_state=42) sgd_clf.fit(X_train, y_train_5)
SGDClassifier在训练时会随机选择数据,如果要复现结果的话,则需要手动设置random_state 参数。现在我们可以使用已训练好的模型进行预测一个手写数字是否是5:
sgd_clf.predict([X_test[0], X_test[1], X_test[2]])
>array([False, False, False])
看起来结果还不错,我们稍后评估一下这个模型的性能。