随机森林与随机子空间
BaggingClassifier类也支持对特征采样,这种采样由两个超参数控制:max_features 与 bootstrap_features,他们的工作方式与max_samples 与 bootstrap一样,只是他们采样的是特征。这样,每个模型将会在一个随机的输入特征子集中进行训练。
这个技巧在处理高维输入(例如图片)时非常有用。同时采样训练数据以及特征的方法,称为Random Patches method。而保持所有训练数据(设置bootstrap=False,max_samples=1.0),但对特征采样(设置bootstrap_features=True,并且/或 max_features 设置为小于1.0的值)的方法称为随机子空间方法(Random Subspaces method)。
对特征采样可以产生更多的模型多样性,通过交易一些bias以获取一些variance的降低。
随机森林
之前介绍过随机森林,它是决策树的集成,一般使用bagging 方法(有时候也用pasting)进行训练,一般 max_samples 设置为训练集的大小。在构建随机森林时,除了使用BaggingClassifer类并传入DecisionTreeClassifier,我们也可以使用RandomForestClassifier类,它是一个更方便的形式,并对决策树进行了优化(类似,使用RandomForestRegressor类做回归任务)。下面的代码使用所有可用的CPU核训练一个随机森林分类器,包含500棵决策树(每棵限制到最多16个节点):
from sklearn.ensemble import RandomForestClassifier rnd_clf = RandomForestClassifier(n_estimators=500, max_leaf_nodes=16, n_jobs=-1) rnd_clf.fit(X_train, y_train) y_pred_rf = rnd_clf.predict(X_test)
RandomForestClassifer 包含DecisionTreeClassifier的所有超参数(用于控制这些树如何生成),同时也包含所有的BaggingClassifier的超参数(用于控制集成本身)。
随机森林算法在构造树时引入了额外的随机数;相比之前分割节点时搜索最佳特征,它现在会在特征的一组随机子集中搜索最佳特征。这个算法会产生更好的树多样性,也就能(再次)牺牲bias以获取更低的variance,最终会产生一个整个更好的模型。下面的BaggingClassifier与之前的RandomForestClassifier大致相同:
bag_clf = BaggingClassifier( DecisionTreeClassifier(splitter='random', max_leaf_nodes=16), n_estimators=500, max_samples=1.0, bootstrap=True, n_jobs=-1 )
Extra-Trees
在随机森林中构造一颗树时,在每个节点仅会考虑特征的一组随机子集用于分割节点(之前提到过)。我们也有其他办法让这些树更随机:对每个特征也使用随机的阈值,而不是搜索最佳可能的阈值。
这种非常随机的树构成的森林称为极随机树(Extremely Randomized Trees,或者简称Extra-Trees)。同样,这种技术也是增加了bias来获取更低的variance。它也让Extra-Tree 比常规的随机森林训练更快,因为在构造树的过程中,在每个节点为每个特征计算最优分割阈值的操作是决策树中最耗时的操作之一。
我们可以使用ExtraTreesClassifier类创建一个Extra-Trees分类器。它的API与RandomForestClassifier类类似。同样,ExtraTreeRegressor类与RandomForestRegressor类有同样的API。
其实我们很难提前了RandomForestClassifier的表现是否会优于(或差于)ExtraTreesClassifier。一般来说,唯一判断的办法就是两个都尝试,然后使用交叉验证(还要使用网格搜索调整超参数)进行对比。
特征重要性
随机森里另外一个非常好的特点是:它使得评估每个特征的相对重要性变得容易。Sk-learn在衡量一个特征的重要性时,会根据决策树中使用此特征减少不纯度的节点的数目,取(森林中所有树的)平均值。更准确的说,这是一个带权平均,每个节点的权重等于这个与它关联的样本数目。
Sk-learn在训练结束后会为每个特征自动计算这个分数,然后将结果缩放,以让所有的重要程度的和等于1。我们可以使用feature_importances_ 变量直接获取结果。例如,下面的代码训练一个RandomForestClassifier,使用iris数据集,并输出每个特征的重要性。看起来最重要的特征是petal length(44%) 和 width(43%),而sepal length 与 width (分别为3% 和10%)相对更不重要:
from sklearn.datasets import load_iris iris = load_iris() rnd_clf = RandomForestClassifier(n_estimators=500, n_jobs=-1) rnd_clf.fit(iris['data'], iris['target']) for name, score in zip(iris['feature_names'], rnd_clf.feature_importances_): print(name, score)
sepal length (cm) 0.102018800240492 sepal width (cm) 0.02641990617224544 petal length (cm) 0.4387715410940775 petal width (cm) 0.432789752493185
类似,如果我们在MNIST数据集上训练一个随机森林分类器,并画出每个像素点的重要性,则可以得到下图:
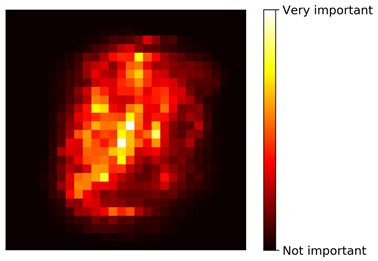
使用随机森林可以非常方便的快速了解到什么特征是真正有意义的,特别是我们需要做特征选择的时候。