本笔记Python版本是3.8.2
str常用的方法
capitalize
将字符串中的第一个字母变成大写,其余变成小写
官方说明:
str.capitalize()
Return a copy of the string with its first character capitalized and the rest lowercased.
例1:
string = 'my name is TOM'
ret = string.capitalize()
print(ret)
结果是:
My name is tom
casefold
这个方法是Python3.3之后引入的,其效果和 lower() 方法非常相似,都可以将字符串中所有大写字符转换为小写。
两者的区别是:lower() 方法只对ASCII编码,也就是‘A-Z’有效,对于其他语言(非汉语或英文)中把大写转换为小写的情况只能用 casefold() 方法。
官方说明:
str.casefold()
Return a casefolded copy of the string. Casefolded strings may be used for caseless matching.
例1:
string = 'my name is TOM'
ret = string.casefold()
print(ret)
运行结果是:
my name is tom
center
返回一个以字符串为中心的width 为长度的字符串,如果字符串的长度大于等于width,直接返回字符串,如果字符串长度小于width,则通过填充补齐width长度然后再返回,补齐的字符串默认是空格,可自己指定
官方说明:
str.center(width [, fillchar])
Return centered in a string of length width. Padding is done using the specified fillchar
(default is an ASCII space). The original string is returned if width is less than or equal to len(s).
例1:
字符串长度小于width
string = '分割线'
ret = string.center(30) # 默认使用空格作为补充
ret2 = string.center(30, '*') # 指定星号为补充字符
print(ret)
print(ret2)
运行结果:
分割线
*************分割线**************
例2:
字符串长度大于等于width
string = 'I have a dream that my four little'
ret = string.center(34, '*')
print(ret)
运行结果是:
I have a dream that my four little
count
统计字符串中指定字符串的数量,如果不指定开始和结束位置,默认是查找整个字符串
官方说明:
str.count(sub[, start[, end]])
Return the number of non-overlapping occurrences of substring sub in the range [start, end].
Optional arguments start and end are interpreted as in slice notation.
例1:
不指定开始和结束位置
string = 'I have a dream that my four little'
ret = string.count('a')
print(ret)
运行结果是:
4
例2:
指定开始和结束位置
string = 'I have a dream that my four little'
ret = string.count('a', 0, 7) # 从第一个位置开始到第七个位置结束,
print(ret)
运行结果:
1
encode
encode是对字符串进行编码,默认编码方式是utf8
官方说明:
str.encode(encoding="utf-8", errors="strict")
Return an encoded version of the string as a bytes object. Default encoding is 'utf-8'
例1:
string = '我是一只小小鸟'
ret = string.encode()
print(ret)
运行结果:
b'xe6x88x91xe6x98xafxe4xb8x80xe5x8fxaaxe5xb0x8fxe5xb0x8fxe9xb8x9f'
endswith
endswith判断是否以指定的内容结尾,如果是,返回True,否则返回False
官方说明:
str.endswith(suffix[, start[, end]])
Return True if the string ends with the specified suffix, otherwise return False.
suffix can also be a tuple of suffixes to look for. With optional start, test beginning at that position.
With optional end, stop comparing at that position.
例1:
string = '我是一只小小鸟'
ret = string.endswith('小鸟')
print(ret)
运行结果:
True
expandtabs
将字符串中的制表符( )替换成空格,具体空格多少由指定的个数来确定,默认是8个,该方法从字符串的第一个字符开始,按给定的空格数开始替换,
例1:
string = '张三丰 张无忌 张翠山'
ret = string.expandtabs(3) # 每个制表符替换成3个空格
print(ret)
运行结果:
每个人名之间是三个空格
张三丰 张无忌 张翠山
例2:
string = '张三丰 张无忌 张翠山'
ret = string.expandtabs(5)
print(ret)
运行结果:
每个人名之间是两个空格
张三丰 张无忌 张翠山
find
在字符串中查找指定子字符串,如果存在返回下标位置(下标从0开始),如果有多个只查找第一个,如果要查找其他的需要用循环,不存在返回 -1,如果不指定开始和结束位置,默认是查找整个。如果仅仅只需要验证子字符串是不是在要查找的字符串中,推荐使用 in
官方说明:
str.find(sub[, start[, end]])
Return the lowest index in the string where substring sub is found within the slice s[start:end].
Optional arguments start and end are interpreted as in slice notation. Return -1 if sub is not found.
例1:
默认只会查询第一个,查询到了就返回下标
string = '张三丰是太极的创始人,他创立了太极拳'
ret = string.find('太极') # 只查询了第一个太极返回 4, 第二个太极下标为 15 并没有返回
print(ret)
运行结果:
4
例2:
查询不到内容,返回 -1
string = '张三丰是太极的创始人,他创立了太极拳'
ret = string.find('张无忌')
print(ret)
运行结果:
-1
例3:
查询全部需要用循环
index = 0 # 开始查找位置
flag = True
string = '张三丰是太极的创始人,他创立了太极拳'
while flag:
index = string.find('太极', index)
# 判断是否查找到,如果没查找到返回 -1 退出循环
if index == -1:
flag = False
print(index)
index += 1 # 查找到后需要从下一个位置继续查找
运行结果:
4
15
-1
format
format格式化字符串,可以使用如下方式:
方式一:用大括号和变量名占位
即 {Variable_name},该变量名指示一个占位符,并不需要给出特定的值,可以用a,b,c代替。该种方式最大的优点是不一定要按照顺序,只要赋值正确即可
例1:
num1 = 100
num2 = 50
ret = num1 * num2
info = "{n1} x {n2} = {result}".format(n2=num2, result=ret, n1=num1)
print(info)
运行结果:
100 x 50 = 5000
方式二:用大括号和下标占位
该种方式,传入的参数必须跟下标位置一 一对应,否则会达不到想要的结果
例2:
num1 = 100
num2 = 50
ret = num1 * num2
info = "{0} x {1} = {2}".format(num2, ret, num1) # 必须按顺序传入,否则结果意想不到
print(info)
运行结果:
50 x 5000 = 100 # 很显然这个结果不是我们想要的,因为传入的顺序不对
index
index返回查找到的内容的下标,如果有多个,只查找第一个,如果没有查找到,会报ValueError错误
官方说明:
str.index(sub[, start[, end]])
Like find(), but raise ValueError when the substring is not found.
例1:
默认只返回匹配到的第一个下标
string = '张三丰是太极的创始人,他创立了太极拳'
index = string.index('太极')
print(index)
运行结果:
4
例2:
index在没有查找到的时候,会报ValueError错误,所以需要捕获异常(捕获异常的笔记在后续文章中)
string = '张三丰是太极的创始人,他创立了太极拳'
index = string.index('张无忌')
print(index)
运行结果:
Traceback (most recent call last):
File "/projects/oldboy/o-company/day03/type_int.py", line 5, in <module>
index = string.index('张无忌')
ValueError: substring not found
以下是修改后捕获异常的代码:
string = '张三丰是太极的创始人,他创立了太极拳'
try:
index = string.index('张无忌')
print(index)
except ValueError:
print('没有查找到')
运行结果:
没有查找到
isalnum
isalnum是判断所给的字符串是不是全部是字母(a-z,A-Z)和数字(0-9),如果是返回True,有一个不是就返回False
特别注意:
(1) 小数点的点也会返回False
(2) 英文字母a-z, A-Z返回的是True`
例1:
全部是数字的情况,返回True
string1 = '123456'
print('string1的结果是:', string1.isalnum())
string2 = 'abcABC'
print('string2的结果是:', string2.isalnum())
运行结果:
string1的结果是: True
string2的结果是: True
isalpha
如果字符串里的内容全部是字母(26个英文字母组成的,包括大写),返回True,否则返回、False
例1:
有其他字符,返回False
string1 = '123456'
print('string1的结果是:', string1.isalpha())
string2 = 'abcABC'
print('string2的结果是:', string2.isalpha())
运行结果:
string1的结果是: False
string2的结果是: True
isascii
如果字符串里的内容都是ASCII表里的内容,返回True,否则返回False,这个是Python3.7新增的内容
例1:
string1 = '123456'
print('string1的结果是:', string1.isascii())
string2 = 'abcABC'
print('string2的结果是:', string2.isalpha())
运行结果:
string1的结果是: True
string2的结果是: True
低于Python 3.7的版本不支持:
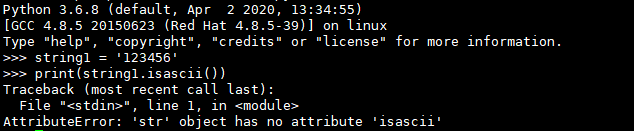
Python 3.8正常执行:

isdecimal
判断字符串中是否只包含十进制的字符
例1:
string1 = '1312'
print('string1的结果是:', string1.isdecimal())
运行结果:
True
isdigit
判断字符串是不是全身数字,这个数字也包括上面的decimal中的十进制的字符
例1:
string1 = '1312'
print('string1的结果是:', string1.isdigit())
运行结果:
string1的结果是: True
isidentifier
判断字符串是不是一个有效的标识符,如果是返回True,否则返回False
例1:
from keyword import iskeyword
string1 = 'class'
print('string1的结果是:', string1.isidentifier())
print('string1是关键字:', iskeyword(string1)) # iskeyword判断字符串是不是关键字
运行结果:
string1的结果是: True
string1是关键字: True
islower
判断字符串是不是所有的字符都是小写,如果是返回True,否则返回False
例1:
string1 = 'Class'
string2 = 'test file'
print('string1的结果是:', string1.islower())
print('string2的结果是:', string2.islower())
运行结果:
string1的结果是: False
string2的结果是: True
isprintable
判断所有字符是不是都能够打印出来
例1:
string1 = ' '
string2 = ''
print('string1的结果是:', string1.isprintable())
print('string2的结果是:', string2.isprintable())
运行结果:
string1的结果是: False
string2的结果是: Tru
isspace
判断字符串是不是全是空格
例1:
string1 = ' '
string2 = ' '
print('string1的结果是:', string1.isprintable()) # tab键等特殊字符不可打印
print('string2的结果是:', string2.isspace())
运行结果:
string1的结果是: False
string2的结果是: True
istitle
判断字符串是不是标题样式(即首字母大写,其他字母小写)
例1:
string1 = 'I Love China'
string2 = 'I love China' # love的L是小写
print('string1的结果是:', string1.istitle())
print('string2的结果是:', string2.istitle())
运行结果:
string1的结果是: True
string2的结果是: False
isupper
判断字符串中所有字母是不是大写,
例1:
string1 = 'I LOVE CHINA'
print('string1的结果是:', string1.isupper())
运行结果:
string1的结果是: True
join
字符串的拼接,返回拼接后的字符串,被拼接的对象必须是可迭代的对象
官方说明:
str.join(iterable)
Return a string which is the concatenation of the strings in iterable. A TypeError will be raised if there are
any non-string values in iterable, including bytes objects. The separator between elements is the string
providing this method.
例1:
string1 = 'spelling'
string2 = '*'
print('拼接后的结果是:', string2.join(string1)) # 用string2来拼接string1
运行结果:
拼接后的结果是: s*p*e*l*l*i*n*g
ljust
返回一个字符串,以给定字符串为开头拼接给定的内容,如果给定的长度小于等于给定字符串的长度,则返回字符串本身。填充的字符默认是空格,长度必须是一个字符
官方说明:
str.ljust(width[, fillchar])
Return the string left justified in a string of length width. Padding is done using the specified fillchar
(default is an ASCII space). The original string is returned if width is less than or equal to len(s).
例1:
string1 = 'I Love China'
print('string1的结果是:', string1.ljust(30, '-'))
运行结果:
string1的结果是: I Love China------------------
lower
将字符串中所有的字母变成小写
例1:
string1 = 'I Love China'
print('string1的结果是:', string1.lower())
运行结果:
string1的结果是: i love china
lstrip
从左侧开始去除字符串中指定的字符,默认是去除空格
例1:
string1 = ' I Love China '
print('string1的结果是:%s' % string1.lstrip()) # 用%格式化,是为了避免用逗号分割的方式产生的空格产生歧义
运行结果:
string1的结果是:I Love China
例2:
string1 = '----------I Love China----------'
print('string1的结果是:%s' % string1.lstrip('-')) # 指定移除的字符
运行结果:
string1的结果是:I Love China----------
partition
返回一个包含三个元素的元组,以给定的分隔符第一次出现时拆分,第一个元素是分隔符之前的内容,第二个元素是分隔符本身,第三个元素是分隔符之后的元素,如果分隔符在字符串中找不到,则第一个元素是这个字符串,第二和第三个元素是空字符串
例1:
string1 = '----------I Love China----------'
print('string1的结果是:', string1.partition('love'.title()))
运行结果:
string1的结果是: ('----------I ', 'Love', ' China----------')
replace
将新字符串替换旧字符串 ,返回一个替换后的字符串,如果无计数,默认替换全部
官方说明:
str.replace(old, new[, count])
Return a copy of the string with all occurrences of substring old replaced by new. If the optional argument
count is given, only the first count occurrences are replaced.
例1:
string1 = '----------I Love China----------'
print('string1的结果是:', string1.replace('-', '*')) # 默认替换全部
print('string1的结果是:', string1.replace('-', '*', 5)) # 只替换5次
运行结果:
string1的结果是: **********I Love China**********
string1的结果是: *****-----I Love China----------
rjust
返回一个字符串,以给定字符串为结尾拼接给定的内容,如果给定的长度小于等于给定字符串的长度,则返回字符串本身。填充的字符默认是空格,长度必须是一个字符,该方法与ljust类似
例1:
string1 = 'I Love China'
print('string1的结果是:', string1.rjust(30, '-'))
运行结果:
string1的结果是: ------------------I Love China
rpartition
该方法与 partition的用法和功能一样,区别在于,如果找不到,第一和第二个为空,第三个为这个字符串
例1:
string1 = '----------I Love China----------'
print('string1的结果是:', string1.rpartition('love')) # 字符串的Love是大写,找不到返回字符串本身
运行结果:
string1的结果是: ('', '', '----------I Love China----------') # 第一和第二个元素是空
rsplit
split是从右侧开始字符串的分割,默认是以空格进行分割,最大切割次数默认是-1 ,表示全部分割
例1:
指定了切割次数,所以结果只有两个元素
string1 = 'I Love China'
print('string1的结果是:', string1.rsplit(maxsplit=1)) # 以空格分隔,只分隔一次
运行结果:
string1的结果是: ['I Love', 'China']
例2:
不指定切割次数,默认全部切割,结果有三个元素
string1 = 'I Love China'
print('string1的结果是:', string1.split()) # 以空格分隔,全部分割
运行结果:
string1的结果是: ['I', 'Love', 'China']
rstrip
从右侧开始去除给定的字符,默认是去除空格
注意:
当要移除的字符前面还有其他字符的时候,移除会失效
例1:
去除空格在lstrip演示过,这里演示去除指定的字符
string1 = '---------- I Love China ----------'
print('string1的结果是:', string1.rstrip('-'))
运行结果:
string1的结果是: ---------- I Love China
例2:
移除的字符前面还有其他字符
string1 = '---------- I Love China ----------*'
print('string1的结果是:', string1.rstrip('-')) # 要移除的字符前面有一个 *
运行结果:
string1的结果是: ---------- I Love China ----------*
split
split是从左侧开始字符串的分割,默认是以空格进行分割,最大切割次数默认是-1 ,表示全部分割
例1:
string1 = 'I Love China'
print('string1的结果是:', string1.split(maxsplit=1))
运行结果:
string1的结果是: ['I', 'Love China']
例2:
string1 = 'I Love China'
print('string1的结果是:', string1.split())
运行结果:
string1的结果是: ['I', 'Love', 'China']
splitlines
将字符串按行边界符进行分割,如果需要在结果列表中保留边界符,需要设置keepends=True
常见的边界符:
| 边界符 | 说明 |
|---|---|
| 换行 | |
| 回车 | |
| 回车换行 | |
| v or x0b | 行列表 |
| f or x0c | 换页 |
| x1c | 文件分隔符 |
| x1d | 组分割符 |
| x1e | 记录分隔符 |
| x85 | 下一行(C1控制代码) |
| u2028 | 行分隔 |
| u2029 | 段落分隔符 |
例1:
string1 = 'I
LoveChina'
print(string1)
print('string1的结果是:', string1.splitlines())
运行结果:
I
LoveChina
string1的结果是: ['I', 'LoveChina']
startswith
判断是否以特定的字符串开头,可以指定开始和结束位置
例1:
string1 = 'ILoveChina'
print('string1的结果是:', string1.startswith('Lo', 1)) # 指定开始位置匹配特定字符开头
运行结果:
string1的结果是: True
strip
清除字符串两边特定的字符,默认是空格
例1:
string1 = '----------I Love China----------'
print('string1的结果是:%s' % string1.strip('-')) # 清除两边的横线
运行结果:
string1的结果是:I Love China
swapcase
大小写翻转,如果做两次翻转则回到了未翻转前状态
例1:
string1 = 'I Love China'
print('string1的结果是:%s' % string1.swapcase())
运行结果:
string1的结果是:i lOVE cHINA
title
给字符串中每个单词的的首字母变成大写,其他字母变成小写
例1:
string1 = 'I LoVe chinA'
print('string1的结果是:%s' % string1.title())
运行结果:
string1的结果是:I Love China
upper
将所有小写字母转换成大写
例1:
string1 = 'I LoVe chinA'
print('string1的结果是:%s' % string1.upper())
运行结果:
string1的结果是:I LOVE CHINA
zfill
填充ASCII中的字符 0 ,如果字符串长度大于等于给定的长度,返回字符串本身,不足时才补0
例1:
string1 = '123'
print('string1的结果是:%s' % string1.zfill(10))
运行结果:
string1的结果是:0000000123
maketrans 和 translate
这两个方法需要组合使用,maketrans生成一个对应字典,translate通过这个字典,将字符串中的内容替换成对应的字符,可以算做一种加密方式
例1:
将数字转换成对应的字符,然后加密邮箱
p = str.maketrans('0123456789@.com', 'ab^defg!@#!=740')
print(p)
info = '929162742@qq.com'
print(info.translate(p))
运行结果:
{48: 97, 49: 98, 50: 94, 51: 100, 52: 101, 53: 102, 54: 103, 55: 33, 56: 64, 57: 35, 64: 33,
46: 61, 99: 55, 111: 52, 109: 48}
#^#bg^!e^!qq=740 # 这是邮箱经过替换得到的字符