1 什么是分桶
上一篇说到了分区,分区中的数据可以被进一步拆分成桶,bucket。不同于分区对列直接进行拆分,桶往往使用列的哈希值进行数据采样。在分区数量过于庞大以至于可能导致文件系统崩溃时,建议使用桶。
hive使用对分桶所用的值进行hash,并用hash结果除以桶的个数做取余运算的方式来分桶,保证了每个桶中都有数据,但每个桶中的数据条数不一定相等。
2 如何分桶
首先,在建立桶之前,需要设置hive.enforce.bucketing属性为true,使得hive能识别桶。
然后,创建带有桶的表:
CREATE TABLE bucketed_user(
id INT,
name String
)
CLUSTERED BY (id) INTO 5 BUCKETS;
向桶中插入数据,这里按照用户id分成了5个桶
此时查看文件系统中的目录结构如下:
/usr/hive/warehouse/bucketed_user/000000_0
/usr/hive/warehouse/bucketed_user/000001_0
/usr/hive/warehouse/bucketed_user/000002_0
/usr/hive/warehouse/bucketed_user/000003_0
/usr/hive/warehouse/bucketed_user/000004_0
5个桶就是将数据表存储分为5个文件存储
注:cluster by不会影响数据的导入,这意味着,用户必须自己负责数据如何导入,包括数据的分桶和排序。
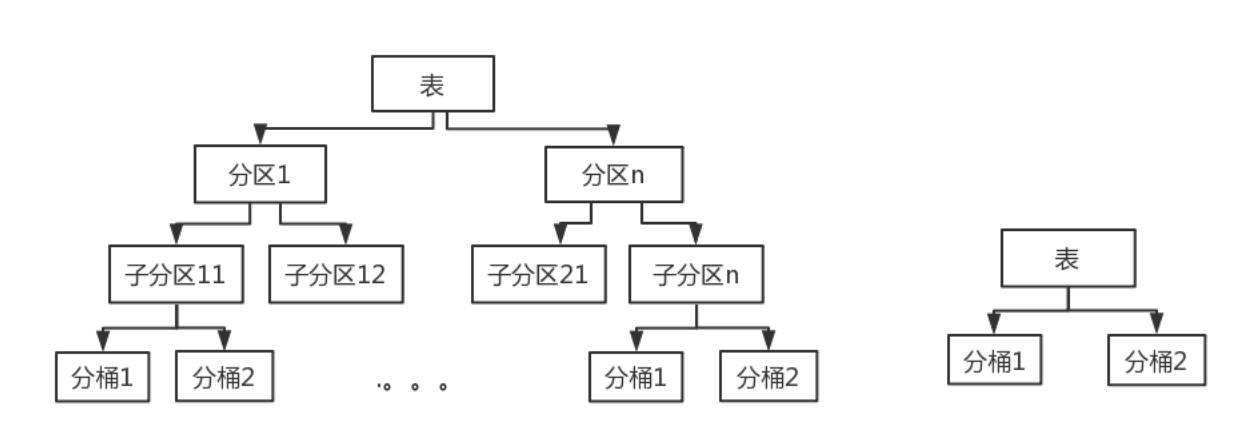
3 分区与分桶比较
- 桶的数量是固定的;
- 分区可以再分子区,桶不行;
- 分区或表组织成桶,Hive在处理有些查询时能利用桶的结构,获得更高的查询处理效率
- 分桶使取样(sampling)更高效
- 物理存储方式不同
如下图,分区又分桶和只分桶的图:
注:
抽样语法:TABLESAMPLE(BUCKET x OUT OF y)
y必须是table总bucket数的倍数或者因子。hive根据y的大小,决定抽样的比例。例如,table总共分了64份,当y=32时,抽取(64/32=)2个bucket的数据,当y=128时,抽取(64/128=)1/2个bucket的数据。x表示从哪个bucket开始抽取。例如,table总bucket数为32,tablesample(bucket 3 out of 16),表示总共抽取(32/16=)2个bucket的数据,分别为第3个bucket和第(3+16=)19个bucket的数据。