转自https://www.cnblogs.com/dogecheng/p/12659605.html
简介
特征工程在机器学习中具有重要意义,但是通过手动创造特征是一个缓慢且艰巨的过程。Python的特征工程库featuretools可以帮助我们简化这一过程。Featuretools是执行自动化特征工程的框架,有两类特征构造的操作:聚合(aggregation)和 转换(transform)。
示例
版本说明
python 3.7.6
featuretools==0.13.4
scikit-learn==0.22.2.post1
首先,我们得先了解一下featuretools的3个基本组成
- 实体集(EntitySet):把一个二维表看作一个实体,实体集是一个或多个二维表的集合
- 特征基元(Feature Primitives):分为聚合和转换两类,相当于构造新特征的方法
- 深度特征合成(DFS, Deep Feature Synthesis):根据实体集里的实体和特征基元创造新特征
单个数据表
max_depth=1
加载数据

from sklearn.datasets import load_iris import pandas as pd import numpy as np import featuretools as ft dataset = load_iris() X = dataset.data y = dataset.target iris_feature_names = dataset.feature_names df = pd.DataFrame(X, columns=iris_feature_names)
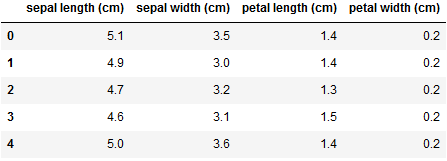
用实体集表示数据集
import featuretools as ft
es = ft.EntitySet(id='single_dataframe') # 用id标识实体集
# 增加一个数据框,命名为iris
es.entity_from_dataframe(entity_id='iris',
dataframe=df,
index='index',
make_index=True)
选择特征基元并自动进行特征工程,我们这里采用加减乘除4个基元,max_depth控制“套娃”的深度,如果是1的话只在原特征上进行,大于1的话不仅会在原来的特征上,还会在其他基元生成的新特征上创造特征,数值越大,允许越深的“套娃”。
trans_primitives=['add_numeric', 'subtract_numeric', 'multiply_numeric', 'divide_numeric'] # 2列相加减乘除来生成新特征
# ft.list_primitives() # 查看可使用的特征集元
feature_matrix, feature_names = ft.dfs(entityset=es,
target_entity='iris',
max_depth=1, # max_depth=1,只在原特征上进行运算产生新特征
verbose=1,
trans_primitives=trans_primitives
)
我们知道加法和乘法满足交换律,而减法和除法不满足,以特征A和B为例,A+B的结果一定等于B+A,但是A-B不一定等于B-A。
按理说,不同基元操作后的总特征数:
加和乘的新特征数+原始特征数,feature_num*(feature_num-1)/2+feature_num,所以这里是4*3/2+4=10
减和除的新特征数+原始特征数,feature_num*(feature_num-1)+feature_num,所以这里是4*3+4=16
10*2+16*2-4*3=40,4*3减去重复的3原始特征3次
在0.13.4版本的featuretools中,默认减法满足交换律,因此实际生成的特征会少一些,只有34个特征。

下面是0.13.4版本的featuretools中的代码,subtract_numeric默认开启了交换律,我想因为 A-B = -(B-A) ,可以认为是一个特征,只不过一个是正相关一个是负相关。但是如果max_depth很深,差别会越来越大,如 A+B×(A-B) 和 A+B×(B-A) 。
class SubtractNumeric(TransformPrimitive):
name = "subtract_numeric"
input_types = [Numeric, Numeric]
return_type = Numeric
def __init__(self, commutative=True):
self.commutative = commutative
...
如果想要全部特征,可以创建一个subtract_numeric的实例,让commutative参数为False,这时就会有40个特征了,这是预期的结果。
trans_primitives=['add_numeric', ft.primitives.SubtractNumeric(commutative=False), 'multiply_numeric', 'divide_numeric']
feature_matrix, feature_names = ft.dfs(entityset=es,
target_entity='iris',
max_depth=1,
verbose=1,
trans_primitives=trans_primitives
)
自动特征工程后,可能会出现 np.inf 和 np.nan 这样的异常值,我们需要处理这些异常数据。其中 np.inf 可能是由 n/0 导致的,np.nan 可能是由 0/0 导致的。
feature_matrix.replace([np.inf, -np.inf], np.nan) # np.inf都用np.nan代替 feature_matrix.isnull().sum()
max_depth不为1
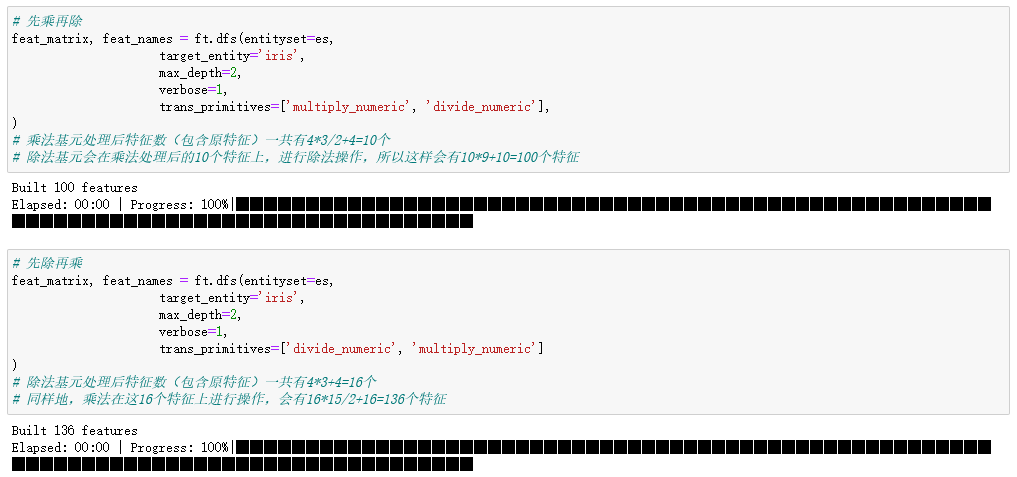
如果我们的max_depth不为1,要知道特征基元的顺序是会带来影响的。另外就是如果max_depth数值大,特征基元多的话特征工程后的维度会迅速膨胀。下面的两个例子中,原来的特征只有4个,让max_depth为2且只用2个特征基元后特征就有100+了。
先乘再除
feat_matrix, feat_names = ft.dfs(entityset=es,
target_entity='iris',
max_depth=2,
verbose=1,
trans_primitives=['multiply_numeric', 'divide_numeric'],
)
# 乘法基元处理后特征数(包含原特征)一共有4*3/2+4=10个
# 除法基元会在乘法处理后的10个特征上,进行除法操作,所以这样会有10*9+10=100个特征
先除再乘
feat_matrix, feat_names = ft.dfs(entityset=es,
target_entity='iris',
max_depth=2,
verbose=1,
trans_primitives=['divide_numeric', 'multiply_numeric']
)
# 除法基元处理后特征数(包含原特征)一共有4*3+4=16个
# 同样地,乘法在这16个特征上进行操作,会有16*15/2+16=136个特征
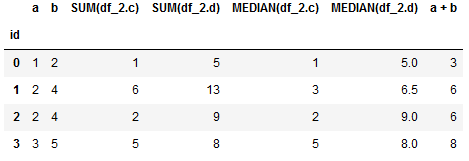
多个数据表
我们这里自定义2个数据表来表示。其中df_2中id就是df_1中的id
df_1 = pd.DataFrame({'id':[0,1,2,3], 'a':[1,2,2,3], 'b':[2,4,4,5]})
df_2 = pd.DataFrame({'id':[0,1,1,2,3], 'c':[1,3,3,2,5], 'd':[5,6,7,9,8]})
es = ft.EntitySet(id='double_dataframe')
es.entity_from_dataframe(entity_id='df_1', # 增加一个数据框
dataframe=df_1,
index='id')
es.entity_from_dataframe(entity_id='df_2', # 增加一个数据框
dataframe=df_2,
index='index',
make_index=True)
# 通过 id 关联 df_1 和 df_2 实体
relation = ft.Relationship(es['df_1']['id'], es['df_2']['id'])
es = es.add_relationship(relation)
聚合基元 sum 和 median 会将df_2中相同“id”的数据进行相加和取中位数的操作
trans_primitives=['add_numeric']
agg_primitives=['sum', 'median']
feature_matrix, feature_names = ft.dfs(entityset=es,
target_entity='df_1',
max_depth=1,
verbose=1,
agg_primitives=agg_primitives,
trans_primitives=trans_primitives)