一、Elasticsearch内置分词器
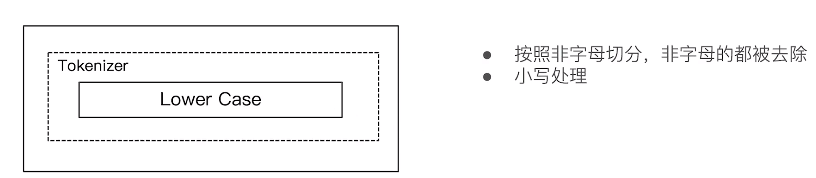
#Simple Analyzer – 按照非字母切分(符号被过滤),小写处理
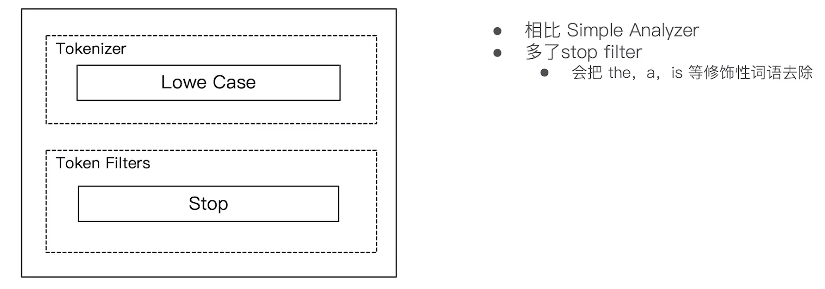
#Stop Analyzer – 小写处理,停用词过滤(the,a,is)
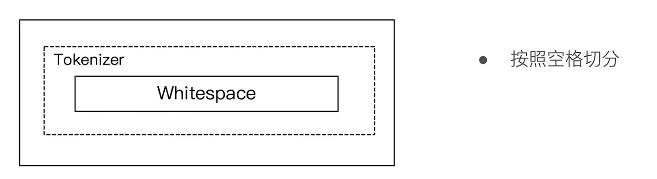
#Whitespace Analyzer – 按照空格切分,不转小写
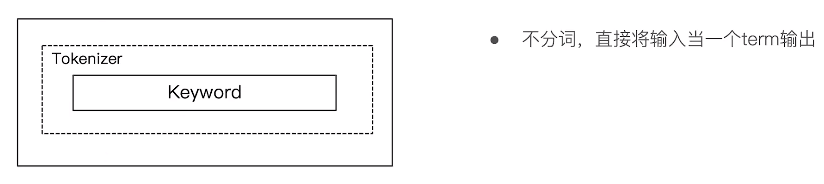
#Keyword Analyzer – 不分词,直接将输入当作输出
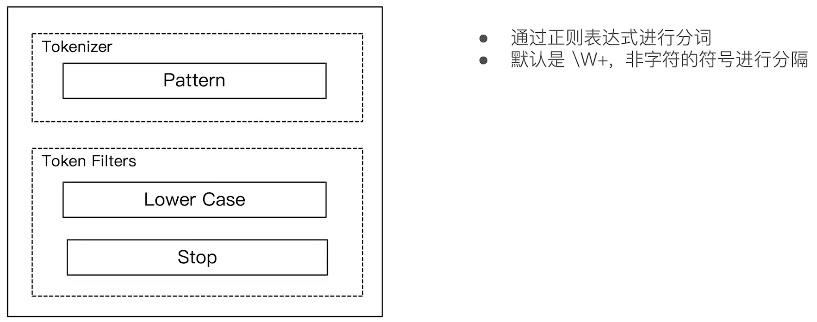
#Patter Analyzer – 正则表达式,默认 W+ (非字符分隔)
#Language – 提供了30多种常见语言的分词器1,Standard Analyzer

2, Simple Analyzer
3,Whitespace Analyzer
4,Stop Analyzer
5,Keywork Analyzer
6,Pattern Analyzer


#Simple Analyzer – 按照非字母切分(符号被过滤),小写处理 #Stop Analyzer – 小写处理,停用词过滤(the,a,is) #Whitespace Analyzer – 按照空格切分,不转小写 #Keyword Analyzer – 不分词,直接将输入当作输出 #Patter Analyzer – 正则表达式,默认 W+ (非字符分隔) #Language – 提供了30多种常见语言的分词器 #2 running Quick brown-foxes leap over lazy dogs in the summer evening #查看不同的analyzer的效果 #standard GET _analyze { "analyzer": "standard", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." } #simpe GET _analyze { "analyzer": "simple", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." } GET _analyze { "analyzer": "stop", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." } #stop GET _analyze { "analyzer": "whitespace", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." } #keyword GET _analyze { "analyzer": "keyword", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." } GET _analyze { "analyzer": "pattern", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." } #english GET _analyze { "analyzer": "english", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." } POST _analyze { "analyzer": "icu_analyzer", "text": "他说的确实在理”" } POST _analyze { "analyzer": "standard", "text": "他说的确实在理”" } POST _analyze { "analyzer": "icu_analyzer", "text": "这个苹果不大好吃" }
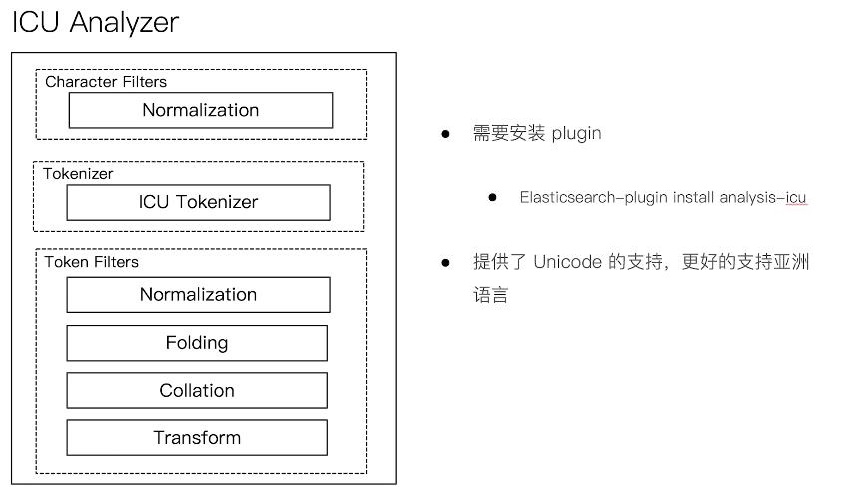
二、中文分词 ICU Analyzer
//直接指定analyze进行测试 GET _analyze { "analyzer":"icu_analyzer", "text":"你好中国" }
2,其他中文分词插件

三、自定义Analyzer



//自定义分词器 PUT /my_index { "settings": { "analysis": { "char_filter": { "&_to_and": { "type": "mapping", "mappings": [ "&=> and "] }}, "filter": { "my_stopwords": { "type": "stop", "stopwords": [ "the", "a" ] }}, "analyzer": { "my_analyzer": { "type": "custom", "char_filter": [ "html_strip", "&_to_and" ], "tokenizer": "standard", "filter": [ "lowercase", "my_stopwords" ] }} }}} //设置mapping PUT /my_index/_mapping { "properties":{ "username":{ "type":"text", "analyzer" : "my_analyzer" }, "password" : { "type" : "text" } } } //插入数据 PUT /my_index/_doc/1 { "username":"The quick & brown fox ", "password":"The quick & brown fox " } //验证 GET my_index/_analyze { "field":"username", "text":"The quick & brown fox" } GET my_index/_analyze { "field":"password", "text":"The quick & brown fox" }
四、ik分词插件
1,下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
需要下载与el版本一致的分词器版本
2,plugins文件夹下面创建一个analysis-ik目录
3,将下载的zip文件copy到analysis-ik目录下,执行unzip
4,运行es
//ik_max_word //ik_smart POST _analyze { "analyzer": "ik_max_word", "text": ["剑桥分析公司多位高管对卧底记者说,他们确保了唐纳德·特朗普在总统大选中获胜"] }
hanlp分词插件
1,下载地址:https://github.com/KennFalcon/elasticsearch-analysis-hanlp