很多时候,我们都需要清除结果集中的重复内容。为了解决这个问题,一个办法是在选择语句中加入关键 字distinct。该关键字的作用是让查询引擎清楚重复内容,以便得到一个无重复记录的结果集。也许您还不知道,实际上group by子句也可用来删除重复的内容, 本文将为读者介绍两者之间的不同之处,以及它们是如何生成理想的结果集的。
一、关键字Distinct和Distinctrow
关键字distinct一般直接跟在查询语句中SELECT的后面,替换可选的关键字all,而关键字all是默认的。Distinctrow是distinct的别名,它产生的效果与distinct是完成一样的:
select_expr
[FROM table_references
[WHERE where_condition]
为了说明这些关键字的用法,我们以下表中的数据为例来进行说明。其中,该表含有一些水果名称及其对应的颜色:
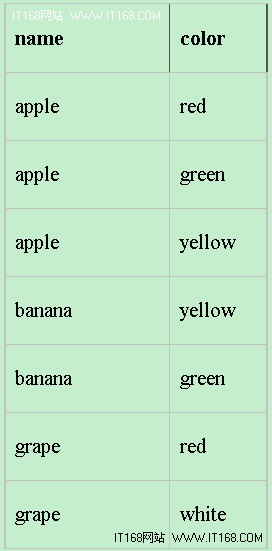
以下查询将从上表中检索所有水果的名称,并按字母顺序将其列出:
FROM fruits;
由于没有附带颜色信息,所以每种水果品种的是重复的:

现在,让我们使用关键字distinct再查询一次,看看结果如何:
FROM fruits;
不出所料,由于附带了水果的颜色信息,所以每种水果的名称只出现了一次:

二、重复数据的取舍
有时候,是不能使用关键字distinct的,因为删除复制的数据会导致错误的结果。请考虑下列情形:
客户想要生成一张职工表,以便进行某些资料统计。 为此,我们可以使用下列命令:
gender,
salary
FROM employees
ORDER BY name;
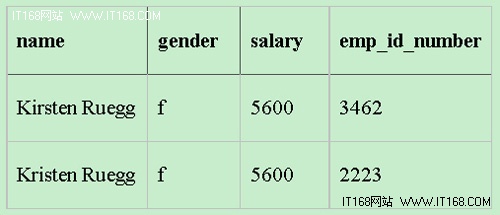
奇怪的是,结果中出现了重复的“Kristen Ruegg”:

客户说,他们不希望出现重复,所以开发人员在SELECT语句中加入了关键字distinct。 好了,这会能够满足客户的要求了,但是问题也随之而来了,因为公司确实有两个重名的员工。所以,添加关键字distinct删除了一个有效的记录,因此得 到的结果实际上错误的。我们可以通过emp_id_number来确认一下,的确有两名员工都叫Kristen Rueggs:
gender,
salary,
emp_id_number
FROM employees
ORDER BY name;
下面是出现问题的数据,它们的emp_id_numbers都是唯一的:
上面的情形告诉我们:使用关键字distinct的时候,要确保不会无意中删除有效数据!
三、关键字Distinct与Group By的区别
使用distinct与不使用聚合功能情况下对全选所有栏数据进行分组的逻辑效果是一样的。对于这样的查询,group by命令只是生产了一列分组后的值。在显示某栏并对齐分组的时候,该查询会给出该栏中不同的值。然而,在显示多栏并对它们进行分组的时候,该查询会给出每 栏中的值的不同的组和。例如,以下查询生成的结果与第一个SELECT distinct命令的结果完全一样:
FROM fruits
GROUP BY name;
同样地,以下语句生成的结果,与我们的SELECT distinct语句在员工表上生成的结果也完全一样:
gender,
salary
FROM employees
GROUP BY name;
关键字distinct和group by的区别在于,group by子句会对数据记录进行排序。因此:
gender,
salary
FROM employees
GROUP BY name;
或者:
gender,
salary
FROM employees
ORDER BY name;
四、统计重复的数据
关键字Distinct可以用于COUNT()函数,来统计一栏中包含多少不同的值。COUNT ( distinct expression)将统计给定表达式在不同的非零值的数量。该表达式可以是要统计其中不同的非零值的数量的栏名。
下面是表employee中的所有数据:

对name字段应用Count distinct函数会得到六个不同的名称:
FROM employees;

当然,也可以给出一列用逗号分隔的表达式。假若这样,COUNT()将返回非空值的不同组合数目。以下查询将统计哪些姓名和工资都非NULL的不同记录的数目。
FROM employees;

我们还可以使用group by子句计算每组中重复数据的数量。下面的查询将用来统计不同部门中重名的情况:
COUNT(*) - COUNT(DISTINCT name) AS 'duplicate names'
FROM employees
GROUP BY dept_id;

这些查询可以帮助我们了解重复程度,但是,却无法告诉我们重复的是哪些值。为了弄清楚表employees中哪些名称是复制的,我们可以使用下列查询来显示非唯一值,以及重复次数:
name,
count(name) as name_count
FROM employees
GROUP BY name,
dept_id;

我们这里仅对重复数据感兴趣,所以使用HAVING子句将其他数据全部过滤掉:
name,
count(name) as name_count
FROM employees
GROUP BY name,
dept_id
HAVING name_count > 1;
现在,我们可以知道哪些名称是重复的,以及它们的重复次数:
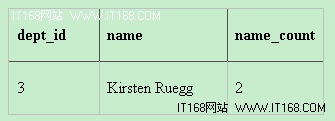
五、显示重复数据中每组最小或者最大值
就像在上面的例子中看到的那样,group by子句会致使对字段列表中的每个唯一值应用聚合函数。应该注意,没有放进group by字段清单中的栏与被聚合的值不必放在同一行。这里给出一个例子,以下查询显示每个部门中的最高工资:
name,
gender,
max(salary) as max_salary
FROM employees
GROUP BY dept_id;
我们还想要显示拿最高工资的那些人的有关信息。然而,返回的结果确是:
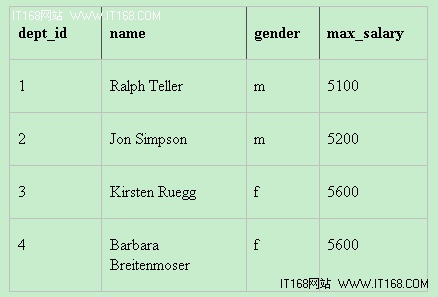
问题在于,工资是唯一被聚合的栏,因为Max()聚合函数只被用于它。因此,显示的是各个group by字段中遇到的第一个name和gender值。 通过查看这个表您会发现,虽然Ralph Teller是1号部门的唯一员工,但是只有Jon Simpson拿到了$4500。我们知道,应该显示Peter Jonson,但是查询引擎选择了遇到的dept_id为2的第一个名称和性别。
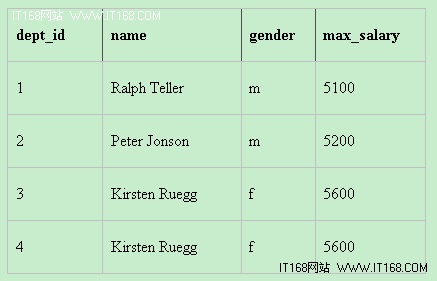
解决方案是,将GROUP_BY结果与原始表进行合并。在这里,我们只有一个字段,即salary:
emp1.name,
emp1.gender,
emp2.max_salary
FROM (
SELECT dept_id,
Max(salary) as max_salary
FROM employees
GROUP BY dept_id
) as emp2 JOIN employees as emp1 ON emp1.salary = emp2.max_salary
GROUP BY dept_id;
现在,name和gender字段属于最高工资者:
六、小结
很多时候,我们都需要清除结果集中的重复内容。为了解决这个问题,一个办法是在选择语句中加入关键字distinct。该关键字的作用是让查询引擎清楚 重复内容,以便得到一个无重复记录的结果集。也许您还不知道,实际上group by子句也可用来删除重复的内容, 本文为读者介绍了两者之间的不同之处,以及它们是如何生成理想的结果集的。当然,我们还可以使用工作单元表和动态SQL删除结果集中的重复数据。有机会我 们将在后文中专门加以讲解。