通过将单词转化到向量空间可以分析句子的语义,最常见的一个应用就是评价分析(如淘宝的商品评价,电影的评价等),那么如何将这些评价的句子进行分析呢?举个例子:
现在有一句评语“I hate this boring movie”,我们将其送入预先写好的某一系统最终得到一个评价的二分类(好评/差评),这个预先写好的系统可以是我们的神经网络,经过一个“黑盒子”处理得到输出。结合序列信号,就是先将句子按单词分割开,然后将每个单词转化成神经网络可以处理的数值型数据。现假定对于第一个单词 I ,将其输入第一个全连层x@w1+b1,将第二个单词hate输入第二个全连层x@w2+b2,以此类推,最终将各个全连层的输出综合起来得到二分类输出。这种方法是比较直观也是好理解的,但是这种方法存在一些问题。
比如,现在有一段话包含100个单词,那么该模型就要产生100个全连层用来处理数据,这样的话会造成一个很大的参数量。其次是这样的模型没有一个语义相关性,因为对于这样一个模型即使打乱单词的顺序也并不影响其输出(它总是将所有的处理结果综合起来),导致其没办法对一个句子有很好的理解,只能起到管中窥豹的效果。那么如何解决这些问题呢?
对于参数量过大的问题,我们不难想到卷积神经网络相对于全连神经网络的改进,在CNN中采用了一种权值共享的方法,也就是共用卷积核来解决参数量的问题,那么能不能采用这样的思想来处理一个序列信号呢?或者说怎样才能实现序列信号处理过程中的权值共享呢?其实很简单,我们可以使用同样一个线性层来处理所有的单词(类似于使用同一个卷积核的原理),通过这个方法可以很好的解决参数量过大的问题。
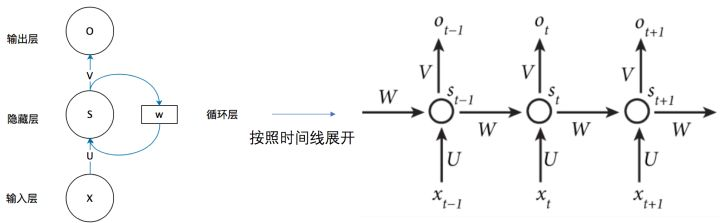
而对于没有综合的抽取语义部分的问题,我们可以这样考虑,上面的模型是把一句话的各个单词分割开放入不同的“容器”进行分析,而这样做的结果就相当于把一桶水分装到若干个杯子里给人去观察,那么,单看一杯一杯的水是无论如何也没办法形成一个“桶”的概念在我们的脑海中的。那么,如果放一个桶在观察者的旁边又会有什么样的效果呢?让桶作为一个新的观察者来总览所有的杯水,是不是就能提取到总体的信息?对于这个模型也是一样的处理逻辑,我们需要一个容器来存储从第一个单词开始到这句话结束的每个单词的语义信息,在上述模型的基础上额外的增加一个memory,负责吸收各单词的权值信息,具体的用法就是,我们给定memory的一个初始状态h0,在处理第一个单词时,我们将线性层变为x@w1+h0@wh,这样的话就在原来单一单词的处理基础上添加上了语义信息,我们把处理后的结果h1直接送入下一个线性层x@w2+h1@wh,这里的x是第二个单词,h1是第一个单词处理后的结果(保留语义),以此类推,这样做在达到单个处理单词的基础上还保留了单词之间的语义相关性。
这样的一种结构就是循环神经网络层,数学表达方法如下:
ht = fw(ht-1,xt)
ht = tanh(Whhht-1 + Wxhxt)
yt = Whyht + b
假定Loss 为MSE的话,可以得到梯度 ∂Et/∂WR=Σ(∂Et/∂yt)(∂yt/∂ht)(∂ht/∂hi)(∂hi/∂WR)
得到梯度之后就可以进行参数的更新啦!