Hadoop的两大核心是HDFS和MapReduce。今天简单谈一下自己对HDFS的认识,由于刚刚入门,如果有不正确的地方,欢迎批评指正。
1.块
HDFS中最核心的一个概念叫块。同普通操作系统中的磁盘块一样(关于普通文件系统的磁盘块,请参考:https://blog.csdn.net/SweeNeil/article/details/88743164),它的作用是为了分摊磁盘的读写开销,因为在大量数据之间通过磁盘寻址开销是非常大的。HDFS的一个块要比普通文件系统大得多,其默认大小为64MB(如果块设置过小会导致寻址开销非常大),当然也可以自定义大小(128MB等等),而普通的文件系统中的块只有几kb。对比之下,有人可能会说,既然HDFS将块设计的较大是为了处理大规模的数据,那么,为什么不尽可能的使块的大小达到最大呢?
需要注意的是,块并不是越大越好。MapReduce是以块为单位来处理数据的,如果块过大就会导致MapReduce就一两个任务执行,完全牺牲了MapReduce的并行度,发挥不了分布式并行处理的效果。
块的设计原因:为了支持面向大规模数据的存储,降低分布式节点的寻址开销。(注意分布式文件系统访问数据要经过三级寻址,首先要去找元数据目录,再找数据节点,最后从数据节点取数据)
HDFS采用这种抽象的块的概念设计,可以支持大规模的文件存储,可以简化系统的设计,并且适合数据备份。
2.HDFS两大组件——数据节点和名称节点
在了解数据节点和名称节点之前,首先需要知道这样一个概念——元数据。元数据和数据是不一样的,在HDFS中,元数据指定了如下内容:(1)文件是什么(2)文件被分成多少块(3)每个块和文件是怎么映射的(4)每个块被存储在哪个服务器上面。有了这样一个模糊的概念,再来看名称节点和数据节点。
名称节点(NameNode):整个HDFS集群的管家,负责整个文件系统元数据的存储,相当于一个数据目录。
数据节点(DataNode):存储实际数据(如一个文本文件、一张图片等)
如果对这个概念仍然模糊,请看下面这张图:
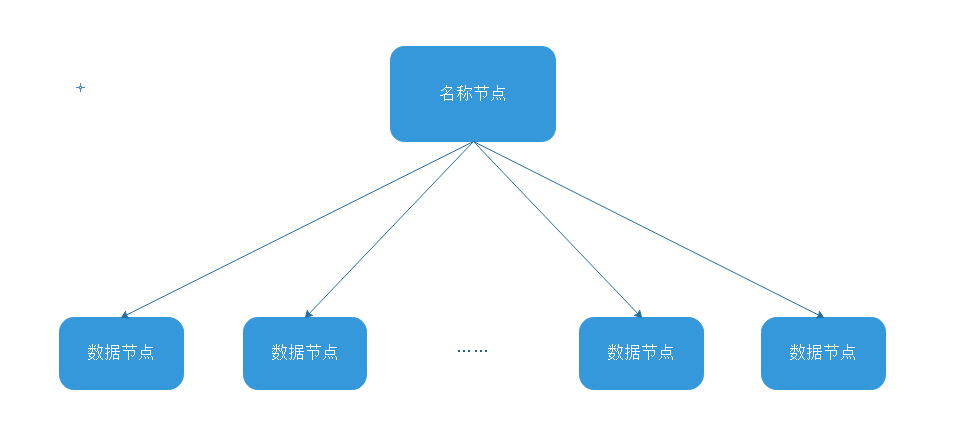
如果把HDFS比作一本书,那么名称节点就是书的目录,数据节点就是书中的具体单元,也就是说,我们在访问一本书的具体单元之前,首先要通过目录去获取各单元对应的页码,我们通过页码找到对应单元,才能读到其中的内容。这也就是上面提到的HDFS三级寻址。
3.名称节点的数据结构
名称节点由两部分组成——FsImage和EditLog
(1)FsImage:保存系统文件树以及文件树中所有的文件文件夹的元数据
设计目的:存储文件的复制等级、修改和访问时间、访问权限、块大小以及组成的文件块,但是FsImage没有存储数据保存在哪个数据节点下,这些信息别单独放在一个内存区域进行维护
任务流程:当数据节点加到一个集群中去的时候,数据节点向名称节点汇报自己的节点中保存了哪些数据块,作为管家的名称节点就可以自己去构建一个清单。所以名称节点是通过运行过程中不断的实时的和数据节点进行沟通来维护这些信息(保存在内存中,而不是存储在FsImage中)
(2)EditLog:记录对数据进行的诸如创建删除重命名等操作
4.名称节点启动时如何处理两大数据结构
(1)shell命令启动名称节点
(2)把FsImage文件从底层磁盘加载到内存中(名称节点的所有元数据都是保存在内存中的),和EditLog里的各项操作进行合并
(3)得到最新的元数据
(4)名称节点会将新的FsImage保留下来,把旧版的进行删除
(5)创建一个空的EditLog
在进行这样一套流程以后,问题又来了,为什么我们不能直接操作FsImage中的数据,而却要利用EditLog走这样一个弯路呢?
5.为什么要设置EditLog
FsImage对于一个大型的分布式文件系统来说,它的规模也是非常大的,如果设置一个FsImage,每次在整个HDFS的运行过程中,每次发生数据的更新修改时还要不断的去修改FsImage,这样就会导致系统运行的非常慢。如果把更新的部分单独放到EditLog中,不去修改FsImage,把增量后续发送的更新全部记录到EditLog中,就可以解决只有FsImage产生的问题。但是这样不断的写入EditLog,又会出现EditLog不断增大的问题。
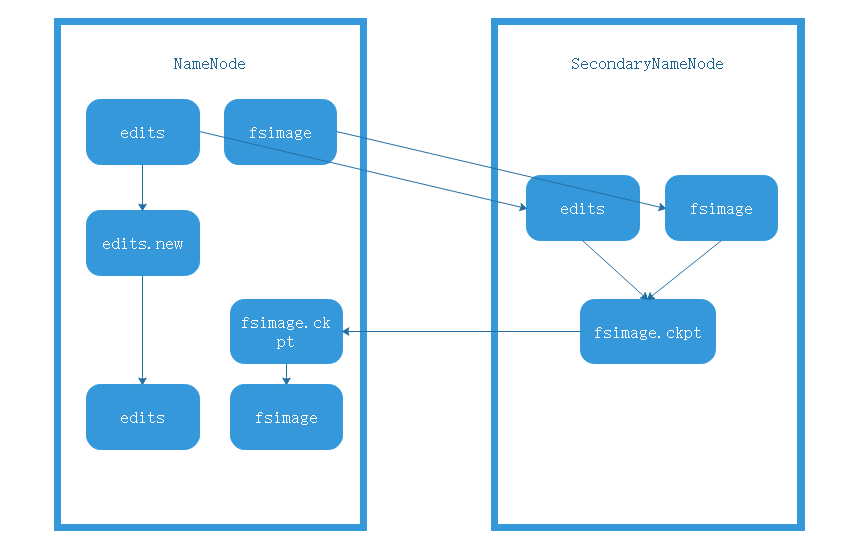
第二名称节点(SecondaryNameNode)就是为了解决这一问题出现的(第二名称节点也可以当做名称节点的冷备份),它会定期的和名称节点进行通信,在某个阶段会请求名称节点停止使用EditLog文件,然后名称节点就会停止使用EditLog,然后产生一个edits.new文件,同时新建一个EditLog,把旧的EditLog信息存到edits.new文件中,然后让第二名称节点取走,第二名称节点会通过Http Get的方式从名称节点把FsImage和EditLog都下载到本地,然后在第二名称节点做合并操作,将得到的新FsImage再发送给名称节点。过程如下图: