1、
- 数学式子:
,其中
是输入向量,
是输出向量,
是偏移向量,
是权重矩阵,
是激活函数。每一层仅仅是把输入
经过如此简单的操作得到
。
- 数学理解:通过如下5种对输入空间(输入向量的集合)的操作,完成 输入空间 —> 输出空间的变换 (矩阵的行空间到列空间)。
注:用“空间”二字的原因是被分类的并不是单个事物,而是一类事物。空间是指这类事物所有个体的集合。 - 1. 升维/降维
- 2. 放大/缩小
- 3. 旋转
- 4. 平移
- 5. “弯曲”
这5种操作中,1,2,3的操作由完成,4的操作是由
完成,5的操作则是由
2、
知道了神经网络的学习过程就是学习控制着空间变换方式(物质组成方式)的权重矩阵后,接下来的问题就是如何学习每一层的权重矩阵 。
如何训练:
既然我们希望网络的输出尽可能的接近真正想要预测的值。那么就可以通过比较当前网络的预测值和我们真正想要的目标值,再根据两者的差异情况来更新每一层的权重矩阵(比如,如果网络的预测值高了,就调整权重让它预测低一些,不断调整,直到能够预测出目标值)。因此就需要先定义“如何比较预测值和目标值的差异”,这便是损失函数或目标函数(loss function or objective function),用于衡量预测值和目标值的差异的方程。loss function的输出值(loss)越高表示差异性越大。那神经网络的训练就变成了尽可能的缩小loss的过程。
所用的方法是梯度下降(Gradient descent):通过使loss值向当前点对应梯度的反方向不断移动,来降低loss。一次移动多少是由学习速率(learning rate)来控制的。
梯度下降的问题:
然而使用梯度下降训练神经网络拥有两个主要难题。
1、局部极小值
梯度下降寻找的是loss function的局部极小值,而我们想要全局最小值。如下图所示,我们希望loss值可以降低到右侧深蓝色的最低点,但loss有可能“卡”在左侧的局部极小值中。
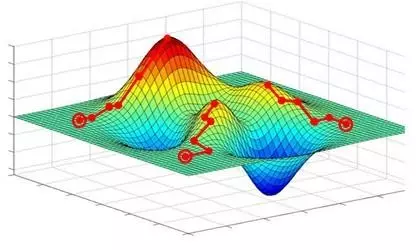
试图解决“卡在局部极小值”问题的方法分两大类:
- 调节步伐:调节学习速率,使每一次的更新“步伐”不同。常用方法有:
- 随机梯度下降(Stochastic Gradient Descent (SGD):每次只更新一个样本所计算的梯度
- 小批量梯度下降(Mini-batch gradient descent):每次更新若干样本所计算的梯度的平均值
- 动量(Momentum):不仅仅考虑当前样本所计算的梯度;Nesterov动量(Nesterov Momentum):Momentum的改进
- Adagrad、RMSProp、Adadelta、Adam:这些方法都是训练过程中依照规则降低学习速率,部分也综合动量
- 优化起点:合理初始化权重(weights initialization)、预训练网络(pre-train),使网络获得一个较好的“起始点”,如最右侧的起始点就比最左侧的起始点要好。常用方法有:高斯分布初始权重(Gaussian distribution)、均匀分布初始权重(Uniform distribution)、Glorot 初始权重、He初始权、稀疏矩阵初始权重(sparse matrix)
2、梯度的计算
机器学习所处理的数据都是高维数据,该如何快速计算梯度、而不是以年来计算。
其次如何更新隐藏层的权重?
解决方法是:计算图:反向传播算法
这里的解释留给非常棒的Computational Graphs: Backpropagation
需要知道的是,反向传播算法是求梯度的一种方法。如同快速傅里叶变换(FFT)的贡献。
而计算图的概念又使梯度的计算更加合理方便。
基本流程图:
下面就结合图简单浏览一下训练和识别过程,并描述各个部分的作用。要结合图解阅读以下内容。但手机显示的图过小,最好用电脑打开。
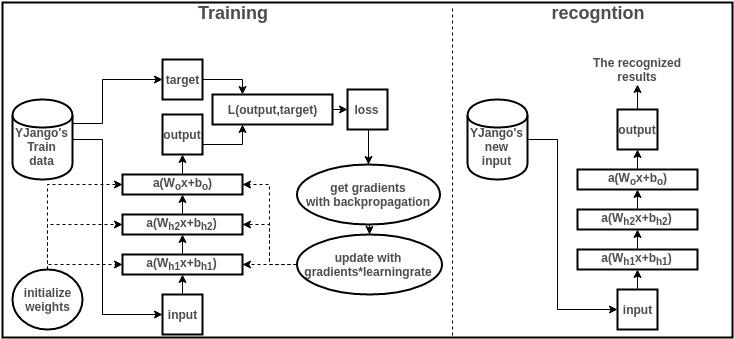
- 收集训练集(train data):也就是同时有input以及对应label的数据。每个数据叫做训练样本(sample)。label也叫target,也是机器学习中最贵的部分。上图表示的是我的数据库。假设input本别是x的维度是39,label的维度是48。
- 设计网络结构(architecture):确定层数、每一隐藏层的节点数和激活函数,以及输出层的激活函数和损失函数。上图用的是两层隐藏层(最后一层是输出层)。隐藏层所用激活函数a( )是ReLu,输出层的激活函数是线性linear(也可看成是没有激活函数)。隐藏层都是1000节点。损失函数L( )是用于比较距离MSE:mean((output - target)^2)。MSE越小表示预测效果越好。训练过程就是不断减小MSE的过程。到此所有数据的维度都已确定:
- 训练数据:
- 权重矩阵:
- 偏移向量:
- 网络输出:
- 数据预处理(preprocessing):将所有样本的input和label处理成能够使用神经网络的数据,label的值域符合激活函数的值域。并简单优化数据以便让训练易于收敛。比如中心化(mean subtraction)、归一化(normalization)、主成分分析(PCA)、白化(whitening)。假设上图的input和output全都经过了中心化和归一化。
- 权重初始化(weights initialization):
在训练前不能为空,要初始化才能够计算loss从而来降低。
- 训练网络(training):训练过程就是用训练数据的input经过网络计算出output,再和label计算出loss,再计算出gradients来更新weights的过程。
- 正向传递:,算当前网络的预测值
- 计算loss:
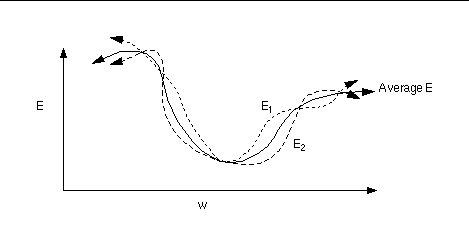
- 计算梯度:从loss开始反向传播计算每个参数(parameters)对应的梯度(gradients)。这里用Stochastic Gradient Descent (SGD) 来计算梯度,即每次更新所计算的梯度都是从一个样本计算出来的。传统的方法Gradient Descent是正向传递所有样本来计算梯度。SGD的方法来计算梯度的话,loss function的形状如下图所示会有变化,这样在更新中就有可能“跳出”局部最小值。
- 更新权重:这里用最简单的方法来更新,即所有参数都
- 预测新值:训练过所有样本后,打乱样本顺序再次训练若干次。训练完毕后,当再来新的数据input,就可以利用训练的网络来预测了。这时的output就是效果很好的预测值了。
3、