Redis的高可用:哨兵和集群
我们在讨论分布式系统的时候,曾经谈过分布式系统要解决的是高并发、大数量和快速响应的问题。事实上,在互联网中,大部分的业务还是以查询数据为主,而非更改数据为主。在互联网出现高并发的时刻,查询关系数据库,会造成关系数据库的压力增大,容易导致系统宕机的严重后果。为了解决这个问题,一些开发者提出了数据缓存技术,数据缓存和关系数据库最大的不同在于,缓存的数据是保存在计算机内存上的,而关系数据库的数据主要保存在磁盘上。计算机检索内存的速度是远超过检索磁盘的,所以缓存技术可以在很大程度上提高整个系统的性能,降低数据库的压力。现今最流行的缓存技术当属NoSQL技术,其中又以现今的主流技术Redis最为成功,所以本章会从Redis的角度来讨论分布式缓存技术的应用,如果你使用的是其他缓存技术,也可参考其中的思想。
使用缓存技术最大的问题是数据的一致性问题,缓存中存储的数据是关系数据库中数据的副本,因为缓存机制与数据库机制不同,所以它们的数据未必是同步的。虽然我们可以使用弱一致性去同步数据,但是现实很少会那么做,因为在互联网系统中,往往查询是可以允许部分数据不实时的,甚至是失真的,例如,一件商品的真实库存是100件,而现在显示是99件,这并不会妨碍用户继续购买。如果使用弱一致性,一方面会造成性能损失,另外一方面也会造成开发者工作量的大量增加。
缓存技术可以极大提升读写数据的速度,但是也有弊端,这就如同人类发明的水库一样。在平时,对水库进行蓄水,当干旱时,就可以把水库的水放出来,维持正常的工作和生活。如果水库设计得太大,那么显然会造成资源的浪费。水库还有另外一个功能,就是当水量过大,在下游有被淹没的危险的时候,关闭闸门,不让水流淹没下游。不过水库也会造成威胁,当水量实在太大,超过有限的水库容量的时候,就会溢出,这时会以更强的冲击力冲毁下游。缓存技术也是一样的,因为它是基于内存的,内存的大小要比磁盘小得多,同时成本也比磁盘高得多。因此缓存太大会浪费资源,过小,则在面临高并发的时候,可能会被快速填满,从而导致内存溢出、缓存服务失败,进而引发一系列的严重问题。
在一般情况下,单服务器缓存已经很难满足分布式系统大数量的要求,因为单服务器的内存空间是有限的,所以当前也会使用分布式缓存来应对。分布式缓存的分片算法和分布式数据库系统的算法大同小异,这里就不再讨论分片算法了。一般情况下,缓存技术使用起来比关系数据库简单,因为分布式数据库还会有事务和协议,而缓存数据一般不要求一致性,数据类型也远不如关系数据库丰富。缓存数据的用途大多是查询,查询和更新不同,对实时性没有那么高的要求,允许有一定的失真,这就给性能的优化带来了更大的空间。
当然相对关系数据库来说,缓存技术速度更快,正常来说,使用Redis的速度会是使用MySQL的几倍到十几倍。可见缓存能极大地优化分布式系统的性能,但是并不是说缓存可以代替关系数据库。首先,缓存主要基于内存的形式存储数据,而关系数据库主要是基于磁盘;内存空间相对有限,价格相对较高,而磁盘空间相对较大,价格相对较低。其次,内存一旦失去电源,数据就会丢失。虽然Redis提供了快照(RDB)和记录追加写命令(AOF)这两种形式进行持久化,但是机制相对简单,难以保证数据不丢失。关系数据库则有其完整的理论和实现,能够有效使用事务和其他机制保证数据的完整性和一致性。因此,当前用缓存技术代替关系数据库技术是不太现实的,但是可以使用缓存技术来实现网站常见的数据查询,这能大幅度地提升性能。一般来说,适合使用缓存的场景包含以下几种。
- 大部分是读业务数据的系统(一般互联网系统都满足该条件)。
- 需要快速响应的系统。
- 需要预备数据(在系统或者某项业务前准备那些经常访问的数据到缓存中,以便于系统开始就能够快速响应,也称为预热数据)的系统。
- 对数据安全和一致性要求不太严格的系统。
有适合使用缓存的场景,当然也会有不适合使用缓存的场景。
- 读业务数据少且写入频繁的系统。
- 对数据安全和一致性有严格要求的系统。
在使用缓存前,我会从3个方面进行考虑。
- 业务数据常用吗?后续命中率如何?命中率很低的数据,没有必要写入缓存。
- 该业务数据是读的多还是写的多,如果是写的多,需要频繁写入关系数据库,也没有必要使用缓存。
- 业务数据大小如何?如果要存储很庞大的内容,就会给缓存系统带来很大的压力,有没有必要?能截取最有价值的部分进行缓存而不全部缓存吗?
经过以上考虑,觉得有必要使用缓存,就可以启动缓存了。在当前互联网中,缓存系统一般由Redis来完成,所以后续我们会集中讨论Redis,就不再讨论其他缓存系统了。本书采用的是Redis的5.0.5版本,如果采用别的版本,在配置项上会有少量不同,不过也大同小异,不会有太大的问题。
16.1 Redis的高可用
在Redis中,缓存的高可用分两种,一种是哨兵,另外一种是集群,下面我们会用两节分别讨论它们。不过在讨论它们之前,需要引入对Redis的依赖,如代码清单16-1所示。
代码清单16-1 引入spring-boot-redis依赖(chapter16模块)
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<exclusions>
<!--不依赖Redis的异步客户端lettuce-->
<exclusion>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<!--引入Redis的客户端驱动jedis-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>这里引入了Redis的依赖,并且选用Jedis作为客户端,没有使用Lettuce。这里解释一下不使用Lettuce的原因。Lettuce是一个可伸缩的线程安全的Redis客户端,多个线程可以共享同一个Redis连接,因为线程安全,所以会牺牲一部分的性能。但是一般来说,使用缓存并不需要很高的线程安全,更注重的是性能。Jedis是一种多线程非安全的客户端,具备更高的性能,所以企业选择的时候往往还是以使用它为主。
16.1.1 哨兵模式
在Redis的服务中,可以有多台服务器,还可以配置主从服务器,通过配置使得从机能够从主机同步数据。在这种配置下,当主Redis服务器出现故障时,只需要执行故障切换(failover)即可,也就是作废当前出故障的主Redis服务器,将从Redis服务器切换为主Redis服务器即可。这个过程可以由人工完成,也可以由程序完成,如果由人工完成,则需要增加人力成本,且容易产生人工错误,还会造成一段时间的程序不可用,所以一般来说,我们会选择使用程序完成。这个程序就是我们所说的哨兵(sentinel),哨兵是一个程序进程,它运行于系统中,通过发送命令去检测各个Redis服务器(包括主从Redis服务器),如图16-1所示。
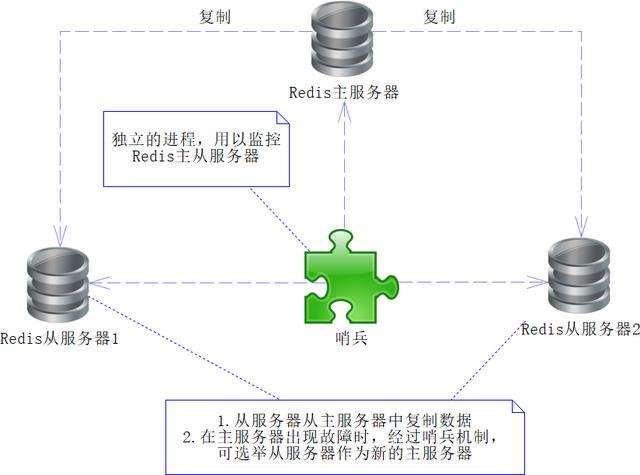
图16-1 单个哨兵模式
图16-1中有2个Redis从服务器,它们会通过复制Redis主服务器的数据来完成同步。此外还有一个哨兵进程,它会通过发送命令来监测各个Redis主从服务器是否可用。当主服务器出现故障不可用时,哨兵监测到这个故障后,就会启动故障切换机制,作废当前故障的主Redis服务器,将其中的一台Redis从服务器修改为主服务器,然后将这个消息发给各个从服务器,使得它们也能做出对应的修改,这样就可以保证系统继续正常工作了。通过这段论述大家可以看出,哨兵进程实际就是代替人工,保证Redis的高可用,使得系统更加健壮。
然而有时候单个哨兵也可能不太可靠,因为哨兵本身也可能出现故障,所以Redis还提供了多哨兵模式。多哨兵模式可以有效地防止单哨兵不可用的情况,如图16-2所示。
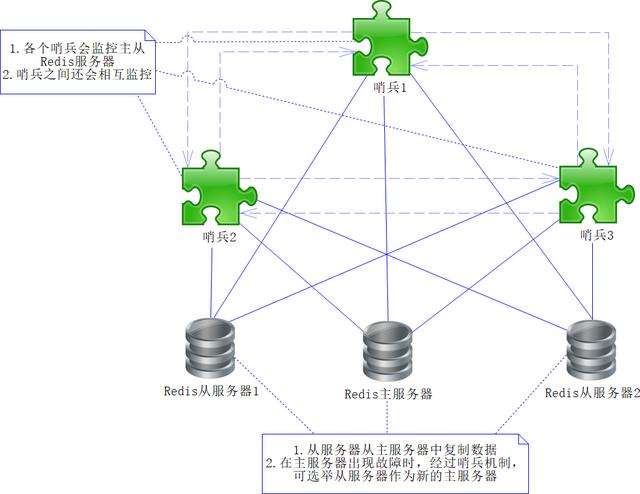
图16-2 多哨兵模式
在图16-2中,多个哨兵会相互监控,使得哨兵模式更为健壮,在这个机制中,即使某个哨兵出现故障不可用,其他哨兵也会监测整个Redis主从服务器,使得服务依旧可用。不过,故障切换方式和单哨兵模式的完全不同,这里我们通过假设举例进行说明。假设Redis主服务器不可用,哨兵1首先监测到了这个情况,这个时候哨兵1不会立即进行故障切换,而是仅仅自己认为主服务器不可用而已,这个过程被称为主观下线。因为Redis主服务器不可用,跟着后续的哨兵(如哨兵2和3)也会监测到这个情况,所以它们也会做主观下线的操作。如果哨兵的主观下线达到了一定的数量,各个哨兵就会发起一次投票,选举出新的Redis主服务器,然后将原来故障的主服务器作废,将新的主服务器的信息发送给各个从Redis服务器做调整,这个时候就能顺利地切换到可用的Redis服务器,保证系统持续可用了,这个过程被称为客观下线。
为了演示这个过程,我先给出自己的哨兵和Redis服务器的情况,如表16-1所示。
表16-1 服务分配情况(略)
这样设计的架构,就如同图16-2一样,下面我们需要对各个服务进行配置。首先修改Redis主服务器配置(192.168.224.131)的内容,在Redis安装目录中找到redis.config文件,打开它,可以发现有很多配置项和注释。只需要对某些配置项进行修改即可,需要修改的配置项代码如下:
# 禁用保护模式
protected-mode no
# 修改可以访问的IP,0.0.0.0代表可以跨域访问
bind 0.0.0.0
# 设置Redis服务密码
requirepass 123456然后再修改两台从服务器的配置,请注意,它们俩的配置是相同的。在Redis安装目录中找到redis.config文件,然后也是对相关的配置项进行修改,代码如下:
# 禁用保护模式
protected-mode no
# 修改可以访问的IP,0.0.0.0代表可以跨域访问
bind 0.0.0.0
# 设置Redis服务密码
requirepass 123456
# 配置从哪里复制数据(也就是配置主Redis服务器)
replicaof 192.168.224.131 6379
# 配置主Redis服务器密码
masterauth 123456以上的配置都有清晰的注释,请自行参考。从服务器的配置只是比主服务器多了replicaof和masterauth两个配置项。
上述的两个配置只是在配置Redis的服务器,此外我们还需要配置哨兵。同样,在Redis安装目录下,找到sentinel.conf文件,然后把3个哨兵服务的配置都改成以下配置。
# 禁止保护模式
protected-mode no
# 配置监听的主服务器,这里sentinel monitor 代表监控,
# mymaster 代表服务器名称,可以自定义
# 192.168.224.131 代表监控的主服务器
# 6379代表端口
# 2 代表只有在2个或者2个以上的哨兵认为主服务器不可用的时候,才进行客观下线
sentinel monitor mymaster 192.168.224.131 6379 2
# sentinel auth-pass定义服务的密码
# mymaster 服务名称
# 123456 Redis服务器密码
sentinel auth-pass mymaster 123456上述的配置只是在原有的其他配置项上按需进行修改。代码中已经给出了清晰的注释,请读者自行参考。
有了这些配置,我们就可以进入Redis的安装目录,使用下面的命令启动服务了。
# 启动Redis服务
./src/redis-server ./redis.conf
# 启动哨兵进程服务
./src/redis-sentinel ./sentinel.conf需要注意的是启动的顺序,首先是主Redis服务器,然后是从Redis服务器,最后才是3个哨兵。启动之后,观察最后一个启动的哨兵,可以看到图16-3所示的信息。
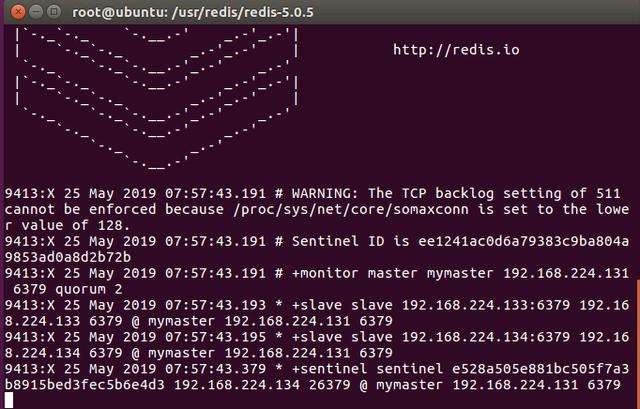
图16-3 哨兵进程输出信息
从图16-3中可以看到主从服务器和哨兵的相关信息,说明我们的多哨兵模式已经搭建好了。
上述的哨兵模式配置好后,就可以在Spring Boot环境中使用了。首先需要配置YAML文件,如代码清单16-2所示。
代码清单16-2 在Spring Boot中配置哨兵(chapter16模块)
spring:
redis:
# 配置哨兵
sentinel:
# 主服务器名称
master: mymaster
# 哨兵节点
nodes: 192.168.224.131:26379,192.168.224.133:26379,192.168.224.134:26379
# 登录密码
password: 123456
# Jedis配置
jedis:
# 连接池配置
pool:
# 最大等待1秒
max-wait: 1s
# 最大空闲连接数
max-idle: 10
# 最大活动连接数
max-active: 20
# 最小空闲连接数
min-idle: 5这样就配置好了哨兵模式下的Redis,为了测试它,可以修改Spring Boot的启动类,如代码清单16-3所示。
代码清单16-3 测试哨兵(chapter16模块)
package com.spring.cloud.chapter16.main;
/**** imports ****/
@SpringBootApplication
@RestController
@RequestMapping("/redis")
public class Chapter16Application {
public static void main(String[] args) {
SpringApplication.run(Chapter16Application.class, args);
}
// 注入StringRedisTemplate对象,该对象操作字符串,由Spring Boot机制自动装配
@Autowired
private StringRedisTemplate stringRedisTemplate = null;
// 测试Redis写入
@GetMapping("/write")
public Map<String, String> testWrite() {
Map<String, String> result = new HashMap<>();
result.put("key1", "value1");
stringRedisTemplate.opsForValue().multiSet(result);
return result;
}
// 测试Redis读出
@GetMapping("/read")
public Map<String, String> testRead() {
Map<String, String> result = new HashMap<>();
result.put("key1", stringRedisTemplate.opsForValue().get("key1"));
return result;
}
}这里的testWrite方法是写入一个键值对,testRead方法是读出键值对。我们先在浏览器请求http://localhost:8080/redis/write,然后到各个Redis主从服务器中查看,都可以看到键值对(key1->value1)。当某个哨兵、Redis服务器或者主Redis服务器出现故障时,哨兵都会进行监测,并且通过主观下线或者客观下线进行修复,使得Redis服务能够具备高可用的特性。只是,在进行客观下线的时候,也需要一个时间间隔进行修复,这是我们需要注意的。默认是30秒,可以通过Redis的sentinel.conf文件的sentinel down-after-milliseconds进行修改,例如修改为60秒:
sentinel down-after-milliseconds mymaster 6000016.1.2 Redis集群
除了可以使用哨兵模式外,还可以使用Redis集群(cluster)技术来实现高可用,不过Redis集群是3.0版本之后才提供的,所以在使用集群前,请注意你的Redis版本。不过在学习Redis集群前,我们需要了解哈希槽(slot)的概念,为此先看一下图16-4。
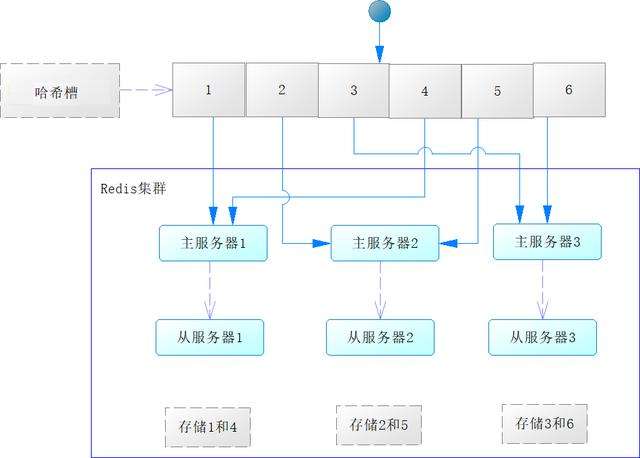
图16-4 哈希槽概念
图16-4中有整数1~6的图形为一个哈希槽,哈希槽中的数字决定了数据将发送到哪台主Redis服务器进行存储。每台主服务器会配置1台到多台从Redis服务器,从服务器会同步主服务器的数据。那么它的工作机制是什么样的呢?下面我们来进行解释。
我们知道Redis是一个key-value缓存,假如计算key的哈希值,得到一个整数,记为hashcode。如果此时执行:
n = hashcode % 6 + 1得到的n就是一个1到6之间的整数,然后通过哈希槽就能找到对应的服务器。例如,n=4时就会找到主服务器1的Redis服务器,而从服务器1就是其从服务器,会对数据进行同步。
在Redis集群中,大体也是通过相同的机制定位服务器的,只是Redis集群的哈希槽大小为(214=16 384),也就是取值范围为区间[0, 16383],最多能够支持16 384个节点,Redis设计师认为这个节点数已经足够了。对于key,Redis集群会采用CRC16算法计算key的哈希值,关于CRC16算法,本书就不论述了,感兴趣的读者可以自行查阅其他资料进行了解。当计算出key的哈希值(记为hashcode)后,通过对16 384求余就可以得到结果(记为n),根据它来寻找哈希槽,就可以找到对应的Redis服务器进行存储了。它们的计算公式为:
# key为Redis的键,通过CRC16算法求哈希值
hashcode = CRC16(key);
# 求余得到哈希槽中的数字,从而找到对应的Redis服务器
n = hashcode % 16384这样n就会落入Redis集群哈希槽的区间[0, 16383]内,从而进一步找到数据。下面举例进行说明,如图16-5所示。
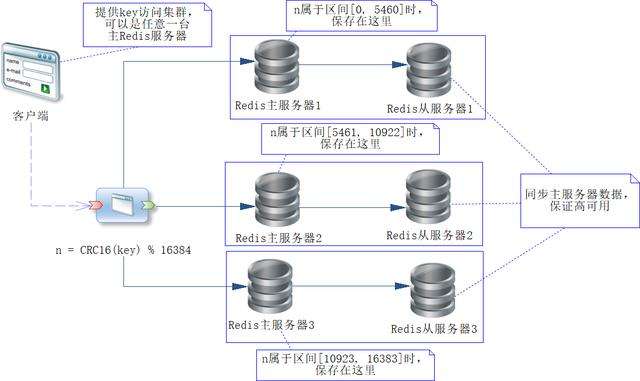
图16-5 Redis集群工作原理
这里假设有3个Redis主服务器(或者称为节点),用来存储缓存的数据,每一个主服务器都有一个从服务器,用来复制主服务器的数据,保证高可用。其中哈希槽分配如下。
- Redis主服务器1:分配哈希槽区间为[0, 5460]。
- Redis主服务器2:分配哈希槽区间为[5461, 10922]。
- Redis主服务器3:分配哈希槽区间为[10923, 16383]。
这样通过CRC16算法求出key的哈希值,再对16 384求余数,就知道n会落入哪个哈希槽里,进而决定数据存储在哪个Redis主服务器上。
注意,集群中各个Redis服务器不是隔绝的,而是相互连通的,采用的是PING-PONG机制,内部使用了二进制协议优化传输速度和带宽,如图16-6所示。
从图16-6中可以看出,客户端与Redis节点是直连的,不需要中间代理层,并且不需要连接集群所有节点,只需连接集群中任何一个可用节点即可。在Redis集群中,要判定某个主节点不可用,需要各个主节点进行投票,如果半数以上主节点认为该节点不可用,该节点就会从集群中被剔除,然后由其从节点代替,这样就可以容错了。因为这个投票机制需要半数以上,所以一般来说,要求节点数大于3,且为单数。因为如果是双数,如4,投票结果可能会为2:2,就会陷入僵局,不利于这个机制的执行。
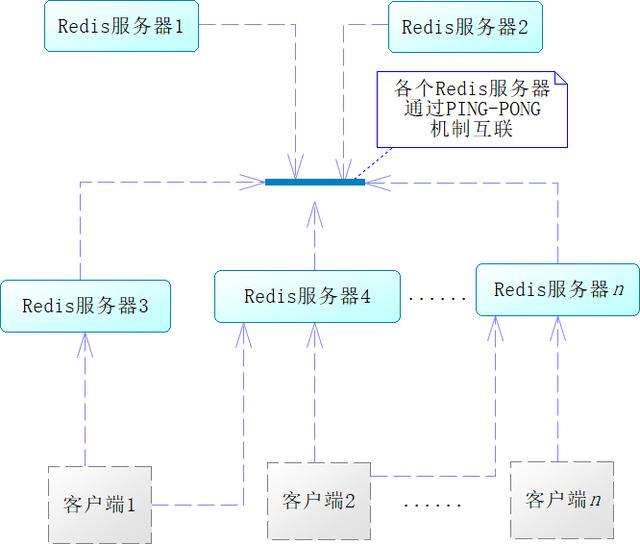
图16-6 Redis集群中各个节点是联通的
在某些情况下,Redis集群会不可用,当集群不可用时,所有对集群的操作做都不可用。那么什么时候集群不可用呢?一般来说,分为两种情况。
- 如果某个主节点被认为不可用,并且没有从节点可以代替它,那么就构建不成哈希槽区间[0, 16383],此时集群将不可用。
- 如果原有半数以上的主节点发生故障,那么无论是否存在可代替的从节点,都认为该集群不可用。
Redis集群是不保证数据一致性的,这也就意味着,它可能存在一定概率的数据丢失现象,所以更多地使用它作为缓存,会更加合理。
有了上述的理论知识,下面让我们来搭建Redis集群环境。我使用的是Ubuntu来搭建Redis环境,首先进入root用户,然后执行以下命令:
cd /usr
# 创建Redis目录,并进入目录
mkdir redis
cd ./redis
# 下载Redis
wget http://download.redis.io/releases/redis-5.0.5.tar.gz
# 解压缩安装包
tar xzf redis-5.0.5.tar.gz
# 进入安装目录
cd redis-5.0.5
# 编译安装Redis
make执行上述命令就安装好了Redis,然后在/usr/redis/redis-5.0.5下创建文件夹cluster,并在其下面创建目录7001、7002、7003、7004、7005和7006,接着将/usr/redis/redis-5.0.5/redis.conf文件复制到目录7001、7002、7003、7004、7005下,最后执行如下命令。
# 进入安装目录
cd /usr/redis/redis-5.0.5
# 创建文件夹cluster和其子目录
mkdir cluster
cd ./cluster
mkdir 7001 7002 7003 7004 7005 7006
# 复制文件
cp ../redis.conf ./7001
cp ../redis.conf ./7002
cp ../redis.conf ./7003
cp ../redis.conf ./7004
cp ../redis.conf ./7005
cp ../redis.conf ./7006
# 赋予目录下所有文件全部权限
chmod -R 777 ./这样从7001到7006的目录下就都有一份Redis的启动配置文件了,之所以让目录起名为这些数字,是因为我将会使用这些数字作为端口来分别启动Redis服务。下面,我们首先来修改7001下的redis.conf文件,只修改文件的部分配置,修改的内容如下:
# 关闭保护模式
protected-mode no
# 允许跨域访问
bind 0.0.0.0
# 主机密码
masterauth 123456
# 登录密码
requirepass 123456
# 端口7001
port 7001
# 启用集群模式
cluster-enabled yes
# 集群配置文件
cluster-config-file nodes-7001.conf
# 和集群节点通信的超时时间
cluster-node-timeout 5000
# 采用添加写命令的模式备份
appendonly yes
# 备份文件名称
appendfilename "appendonly-7001.aof"
# 采用后台运行Redis服务
daemonize yes
# PID命令文件
pidfile /var/run/redis_7001.pid然后再修改7002到7006目录下的redis.conf文件,修改时将所有配置项中的“7001”替换为对应的数字即可,这样我们就可以得到6个启动Redis服务的配置文件了。
接下来就是配置和创建集群了,这里Redis 5也为此提供了工具,并且放在Redis安装目录的子文件夹/utils/create-cluster(我使用的系统全路径为/usr/redis/redis-5.0.5/utils/create-cluster)中。打开这个目录,就可以发现一个create-cluster文件,我们修改它的权限(命令chmod 777 eate-cluster),然后打开它,修改它的内容,代码如下:
#!/bin/bash
# Settings
# 端口,从7000开始,SHELL会自动加1后,找到7001到7006的Redis服务实例
PORT=7000
# 创建超时时间
TIMEOUT=2000
# Redis节点数
NODES=6
# 每台主机的从机数
REPLICAS=1 # ①
# 密码,和我们配置的一致
PASSWORD=123456
......
#### 以下给redis-cli 命令添加配置的密码 ####
if [ "$1" == "create" ]
then
HOSTS=""
while [ $((PORT < ENDPORT)) != "0" ]; do
PORT=$((PORT+1))
HOSTS="$HOSTS 192.168.224.135:$PORT"
done
../../src/redis-cli --cluster create $HOSTS -a $PASSWORD --cluster-replicas $REPLICAS
exit 0
fi
if [ "$1" == "stop" ]
then
while [ $((PORT < ENDPORT)) != "0" ]; do
PORT=$((PORT+1))
echo "Stopping $PORT"
../../src/redis-cli -p $PORT -a $PASSWORD shutdown nosave
done
exit 0
fi
if [ "$1" == "watch" ]
then
PORT=$((PORT+1))
while [ 1 ]; do
clear
date
../../src/redis-cli -p $PORT -a $PASSWORD cluster nodes | head -30
sleep 1
done
exit 0
fi
......
if [ "$1" == "call" ]
then
while [ $((PORT < ENDPORT)) != "0" ]; do
PORT=$((PORT+1))
../../src/redis-cli -p $PORT -a $PASSWORD $2 $3 $4 $5 $6 $7 $8 $9
done
exit 0
fi
...... 这段配置看起来挺复杂,实际是很简单的,我修改的是代码中加粗的部分,其余的并未改动。首先修改了端口,例如,端口从7000开始遍历,这样循环加1,就可以找到7001到7006的服务实例。其次给redis-cli命令,加入配置的密码,修改IP。这里尽量不要使用localhost和127.0.01指向本机IP,应该使用该服务器在网络中的IP,否则不在本机客户端登录时,就会出现一些没有必要的错误。至此,所有的配置就都完成了。
跟着我们需要编写脚本,使得我们能够创建、停止和启动集群。为此,在Linux中以root用户登录,然后执行以下命令:
# 进入集群目录
cd /usr/redis/redis-5.0.5/cluster
# 创建3个脚本文件
touch create.sh start.sh shutdown.sh
# 赋予脚本文件全部权限
chmod 777 *.sh从命令中可以看出,我们创建了3个Shell脚本文件。
- create.sh:用来启动Redis服务,然后创建集群。
- start.sh:用来在集群关闭后,启动集群的各个节点。
- shutdown.sh:关闭运行中的集群的各个节点。
跟着来编写start.sh,代码如下:
# 进入集群工具目录
cd /usr/redis/redis-5.0.5/utils/create-cluster
# 启动集群各个Redis实例,参数为start
./create-cluster start这个脚本是运行集群的各个节点,只是此时集群还没有被创建,所以还不能运行这个脚本。跟着是shutdown.sh的编写,代码如下:
# 进入集群工具目录
cd /usr/redis/redis-5.0.5/utils/create-cluster
# 停止集群各个Redis实例,参数为stop
./create-cluster stop这个脚本是停止集群中的各个实例,当然集群现在没有创建和运行,所以它暂时也不能运行。
为了让start.sh和shutdown.sh能够运行,我们需要创建Redis集群,下面编写create.sh,内容如下:
# 在不同端口启动各个Redis服务 ①
/usr/redis/redis-5.0.5/src/redis-server /usr/redis/redis-5.0.5/cluster/7001/redis.conf
/usr/redis/redis-5.0.5/src/redis-server /usr/redis/redis-5.0.5/cluster/7002/redis.conf
/usr/redis/redis-5.0.5/src/redis-server /usr/redis/redis-5.0.5/cluster/7003/redis.conf
/usr/redis/redis-5.0.5/src/redis-server /usr/redis/redis-5.0.5/cluster/7004/redis.conf
/usr/redis/redis-5.0.5/src/redis-server /usr/redis/redis-5.0.5/cluster/7005/redis.conf
/usr/redis/redis-5.0.5/src/redis-server /usr/redis/redis-5.0.5/cluster/7006/redis.conf
# 创建集群,使用参数create ②
cd /usr/redis/redis-5.0.5/utils/create-cluster
./create-cluster create 这里分为两段,其中第①段是让Redis在各个端口下启动实例,第②段是创建集群。然后我们运行create.sh脚本,就可以看到图16-7所示的提示。
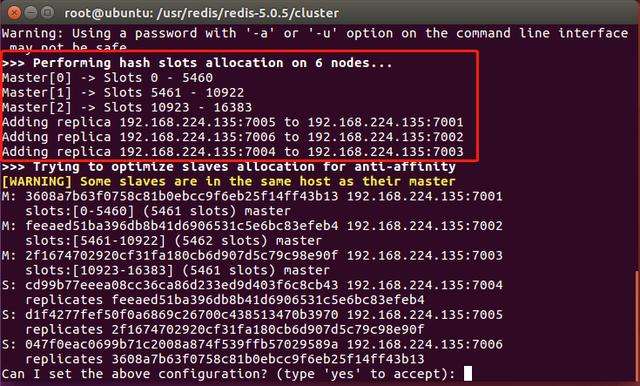
图16-7 创建Redis集群的提示信息
注意图16-7中框中的信息,信息类型大致分为两种。第一种是哈希槽的分配情况,这里提示了分为3个主节点,然后第一个的哈希槽区间为[0, 5460],第二个的为[5461, 10922],第三个的为[10923, 16383]。第二种是从节点的情况,7005端口为7001端口的从节点,7006端口为7002端口的从节点,7004端口为7003端口的从节点。然后它询问我们是否接受该配置,只要输入“yes”回车后,稍等一会儿,它就会创建Redis集群了。
创建好了Redis集群,可以通过命令来验证它,我们先通过redis-cli登录集群,在Linux中执行如下命令。
# 进入目录
cd /usr/redis/redis-5.0.5
# 登录Redis集群:
# -c代表以集群方式登录
# -p 选定登录的端口
# -a 登录集群的密码
./src/redis-cli -c -p 7001 -a 123456这样就能够登录Redis集群了,然后我们可以执行几个Redis的命令来观察执行的情况,执行的命令如下:
set key1 value1
Set key2 value2
set key3 value3
Set key4 value4
set key5 value5我执行的结果如图16-8所示。
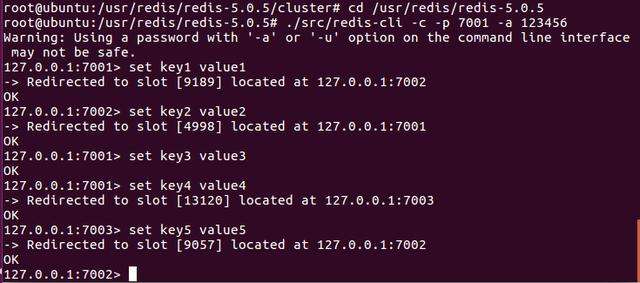
图16-8 验证集群
在图16-8中可以看到,在执行命令的时候,Redis会打印出一个哈希槽的数字,然后重新定位到具体的Redis服务器。这些都是Redis集群机制完成的,对于客户端来说,一切都是透明的。
至此,Redis集群我们就搭建成功了。当我们想停止集群的时候,可以执行之前创建好的shutdown.sh。当我们需要启动已经停止的集群的时候,只需要执行start.sh即可。
上述我们搭建了Redis的集群,跟着就要在Spring Boot中使用它了。在Spring Boot中使用它并不麻烦,只需要先注释掉代码清单16-3中的配置,然后在application.yml文件中加入代码清单16-4所示的代码即可。
代码清单16-4 Spring Boot配置Redis集群(chapter16模块)
spring:
redis:
# 登录密码
# Jedis配置
jedis:
# 连接池配置
pool:
# 最大等待1秒
max-wait: 1s
# 最大空闲连接数
max-idle: 10
# 最大活动连接数
max-active: 20
# 最小空闲连接数
min-idle: 5
# 配置Redis集群信息
cluster:
# 集群节点信息
nodes: 192.168.224.135:7001,192.168.224.135:7002,192.168.224.135:7003,192.168.224.135:7004,192.168.224.135:7005,192.168.224.135:7006
# 最大重定向数,一般设置为5,
# 不建议设置过大,过大容易引发重定向过多的异常
max-redirects: 5
password: 123456这样就在Spring Boot中配置好了,可以像往常一样通过RedisTemplate或者StringRedisTemplate来操作Redis集群了。
16.2 使用一致性哈希(ShardedJedis)
在我们讨论了Redis集群后,大家可以知道,集群实际包含了高可用,也包含了缓存分片两个功能。但是对于集群来说,分片算法是固定且不透明的,可能会因为某种原因使得多数的数据,落入同一个Redis服务中,使负荷不同。有时候,我们还希望使用一致性哈希算法,关于该算法,我们在分布式数据库分片算法中也进行了详尽的介绍,所以这里就不再重复了。在Jedis中还提供了类ShardedJedis,有了这个类,我们可以很容易地在Jedis客户端中使用一致性哈希算法。
ShardedJedis内部已经采用了一致性哈希算法,并且为每个Redis服务器提供了虚拟节点(虚拟节点个数为权重×160)。下面让我们通过代码来学习如何使用ShardedJedis。首先,我们需要创建一个ShardedJedis连接池,于是在Spring Boot的启动类(Chapter16Application.java)中加入代码清单16-5所示的代码。
代码清单16-5 使用ShardedJedis(chapter16模块)
// ShardedJedis 连接池
private ShardedJedisPool pool = null;
@Bean
public ShardedJedisPool initJedisPool() {
// 端口数组
int[] ports = {7001, 7002, 7003};
// 权重数组
int[] weights = {1, 2, 1};
// 服务器
String host = "192.168.224.136";
// 密码
String password = "123456";
// 连接超时时间
int connectionTimeout = 2000;
// 读超时时间
int soTimeout = 2000;
List<JedisShardInfo> shardList = new ArrayList<>();
for (int i=0; i < ports.length; i++) {
// 创建JedisShard信息
JedisShardInfo shard = new JedisShardInfo(
host, ports[i], connectionTimeout, soTimeout,weights[i]); //①
// 设置密码
shard.setPassword(password);
// 加入到列表中
shardList.add(shard);
}
// 连接池配置
JedisPoolConfig poolCfg = new JedisPoolConfig();
poolCfg.setMaxIdle(10);
poolCfg.setMinIdle(5);
poolCfg.setMaxIdle(10);
poolCfg.setMaxTotal(30);
poolCfg.setMaxWaitMillis(2000);
// 创建ShardedJedis连接池
pool = new ShardedJedisPool(poolCfg, shardList); // ②
return pool;
}这里我在一台机器上模拟了3个Redis服务,它们的端口分别为7001、7002和7003。现实中每台服务器的性能都可能是不同的,这里假设7002端口的服务性能要好很多,所以在权重数组中将它的权重设置为2,这样数据缓存到7002服务中的概率就更高了。在代码①处,创建了单个JedisShardInfo对象,然后将它放到一个列表中。代码②处创建了一个JedisShard连接池对象。
上面的代码创建了JedisShard连接池,这样就可以从中取出ShardedJedis对象去操作Redis了。下面让我们在启动类(Chapter16Application.java)中加入代码清单16-6所示的代码来进行演示。
代码清单16-6 使用ShardedJedis(chapter16模块)
// 测试Redis写入
@GetMapping("/test2")
public Map<String, String> test2() {
Map<String, String> result = new HashMap<>();
ShardedJedis jedis = null;
try {
// 获得ShardedJedis对象 ①
jedis = pool.getResource();
// 写入Redis
jedis.set("key1", "value1");
// 从Redis读出
result.put("key1", jedis.get("key1"));
return result;
} finally {
// 最后释放连接
jedis.close(); // ②
}
}代码也比较简单,其中①处是获取ShardedJedis对象,然后设置一个键值对,再从中读出来放到Map中。②处是关闭连接,以避免过多的空闲连接得不到释放。
ShardedJedis使用起来也比较方便,但是无法与Spring提供RedisTemplate和StringRedisTemplate结合。同时,也没有类似哨兵模式和集群模式下主从机主动修复的机制,所以在高可用方面较差。因为它的缺点,所以选择它时需要慎重。
ShardedJedis的原理其实也不难,我们知道Redis是键值对(key-value)缓存,要操作数据就必须要有键(key),所以在做Redis命令操作时,会先根据key求出其哈希值(hashcode),然后再根据哈希值和一致性哈希算法,选择具体的Redis节点。在ShardedJedis的一致性哈希算法中,会给每一个真实的Redis节点制造出“160×权重”个虚拟节点,使数据尽可能平均地分布到每一个节点中。
16.3 分布式缓存实践
在分布式缓存中,还会遇到许多的问题。例如,保存的对象过大,网络传输较慢,又如缓存雪崩等,所以要用好分布式缓存也需要考虑一些常见的问题。
16.3.1 大对象的缓存
在Java中,有些对象可能很大,尤其是那些读取文件的对象。对于大的对象,一次性读出来需要使用很多的网络传输资源,这样会引发性能瓶颈。在Redis官网中,建议我们使用Redis的哈希(Hash)结构去缓存大对象的内容,把它的属性保存到哈希结构的字段(field)中。在读取很大的对象时,往往只需要先读取部分内容,后续再根据需要读取对应的字段即可,如图16-9所示。
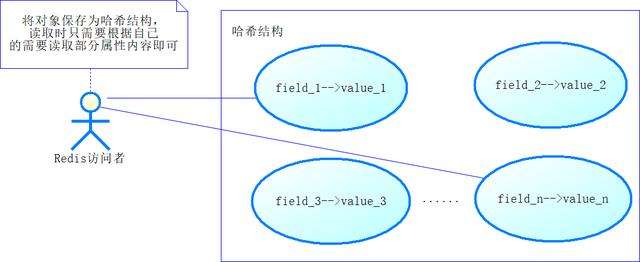
图16-9 将大对象以哈希结构缓存到Redis中
也许还有一种可能,就是哈希结构中的某个字段的值也是大对象,例如一本书有几十万字。一般来说,这个时候会做两方面的考虑。一方面是有必要全部保存吗?是否保存部分最常用的即可?另一方面,可以拆分字符串,将原有的字段拆分为多个字段,拿图16-3来说,假如field3需要存储的是很大的字符串,我们可以将其拆分为field3_1, field3_2, …, field3_n,分段保存字符串,然后读取的时候,也分段读取即可。
16.3.2 缓存穿透、并发和雪崩
当客户端通过一个键去访问缓存时,缓存没有数据,跟着又去访问数据库,数据库也没有数据,这时因为数据库返回也为空,所以不会将该数据放到缓存中,我们把这样的情况称为缓存穿透,如图16-10所示。
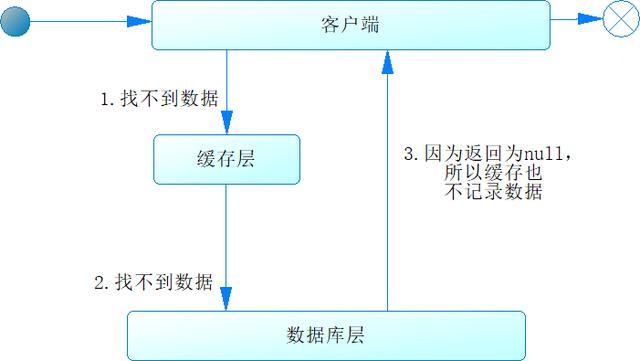
图16-10 缓存穿透
如果我们再次请求这个的键,还是会按照此流程再走一遍。如果出现高并发访问这个键的情况,数据就会频繁访问数据库,给数据库带来很大的压力,甚至可能导致数据库出现故障,这便是缓存穿透带来的危害。
为了解决这个问题,相信大家很快想到,如果在访问数据库后也得到控制,可以在缓存中记录一个字符串(如“null”,代表是空值),即可解决这个问题。但是这样会引发一个问题,就是在很多时候我们访问数据库也得不到数据,这样就会在缓存中存储大量的空值,这显然也会给缓存带来一定的浪费。为此可以增加一个判断,就是判断该键是否是一个常用的数据,如果是常用的,就将它也写入缓存中,这样就不会出现缓存穿透导致数据库被频繁访问的情况了,如图16-11所示。
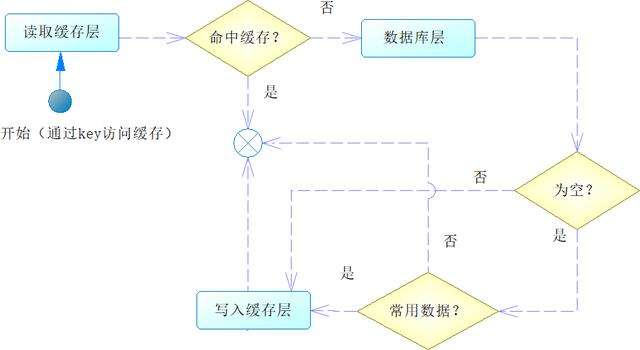
图16-11 解决缓存穿透问题
在使用缓存的过程中,我们往往还会设置超时时间,当数据超时的时候,就不能从缓存中读取数据了,而是到数据库中读取。有些数据是热点数据,例如我们最畅销的产品,假如在高并发期间,这个产品和它的关联信息在缓存中超时失效了,就会导致大量的请求访问数据库,给数据库带来很大的压力,甚至可能导致数据库宕机,类似这样的情况,我们称为缓存并发,如图16-12所示。
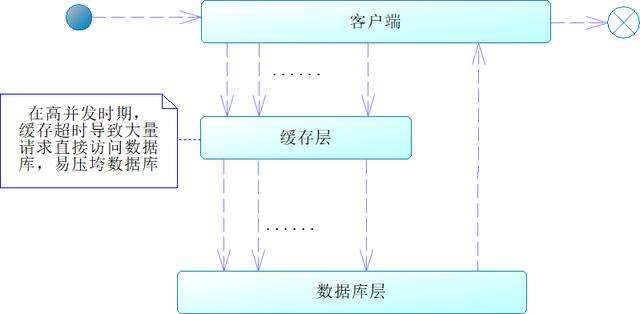
图16-12 缓存并发
为了防止出现缓存并发的情况,一般来说,我们可以采用以下几种方式避免缓存并发。
- 限流:也就是防止过多的请求来访问缓存系统,从而导致压垮数据库,例如使用Resilience4j进行限流,但是这会影响并发线程数量。
- 加锁:对缓存数据加锁,使得线程只能一条条地通过去访问,而不能并发访问,这样就能避免缓存并发的现象,但是分布式锁比较难以实现,所以一般来说我们不会考虑这个办法。
- 错峰失效:网站一般是在上网高峰期或者热门商品抢购时,才会出现高并发现象,而这是有规律的,所以可以自己设置那些需要经常访问的缓存,错过这段时间失效,一般就不会出现缓存并发的现象了,这个做法的成本相对低,也容易实现,所以我比较推荐它。
上述我们谈了缓存穿透和缓存并发,事实上,还有一种缓存雪崩,那什么是缓存雪崩呢?典型的情况是,我们在启动系统的时候,一般会把最常用的数据放入缓存中,并且设置一个固定的超时时间,这便是我们常说的预热数据,它有助于系统性能的提高。但是,因为设置了一个固定的超时时间,所以会导致在某个时间点有大量缓存的键值对数据超时,如果在这个时间点出现高并发,就会导致请求大量访问数据库,造成数据库压力过大,甚至宕机,这便是缓存雪崩,如图16-13所示。
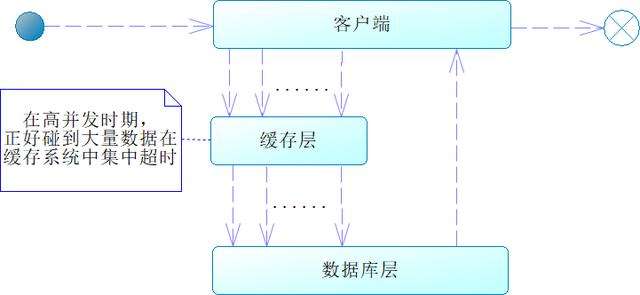
图16-13 缓存雪崩
这里容易混淆的是缓存并发和缓存雪崩的概念,缓存并发是针对一个键值对来说的,而缓存雪崩是针对多个键值对在某个时间点同时超时来说的。一般来说,为了避免缓存雪崩,我们需要在预热数据的时候,防止所有数据都在一个时间点上超时。为此,可以设置不同的超时时间,来避免多个键值对同时失效。例如,key1失效是1小时,key2是1.5小时、key3是30分钟……这样就能够避免数据同时失效了。
16.3.3 缓存实践的一些建议
对于缓存的使用,我们需要遵循一定的规则,避免一些没有必要的麻烦。下面是我的一些建议。
- 对于采用了微服务架构的系统,建议缓存服务器只存储某项业务的数据,不掺杂其他业务的数据,这样可以避免业务数据的耦合。
- 对于存入缓存的预热数据,尽量设置不同的超时时间,以避免同时超时引发缓存雪崩。
- 在使用缓存前,要判断应不应该使用缓存。
- 对于大数据对象的缓存,应该考虑分而治之的办法,化简为零。
- 缓存会造成数据的不一致,也可能存在一定的失真,但是性能好,能够支持高并发的访问,所以多用于读取数据,而对于更新数据,一定要以数据库为基准,不要轻信缓存。
- 对于热门数据,应该考虑错峰失效,错峰更新,避免出现缓存并发现象。
- 在需要大量操作Redis的时候,可以考虑采用流水线(pipeline)的方式,这样可以在很大程度上提高传输的效率。
- 在读数据的时候,先读缓存再读数据库。在写数据的时候,先写数据库再写缓存。
有了这些良好的习惯,相信在使用分布式缓存的时候,会减少许多不必要的麻烦。
本文摘自《Spring Cloud微服务和分布式系统实践》

国内流行的早期的微服务解决方案是阿里巴巴的Dubbo,但这是一个不完整的方案,当前Spring Cloud已成为业界流行的微服务搭建方案。因此,本书以讲解Spring Cloud为主。
Pivotal团队收集了各个企业成功的分布式组件,用Spring Boot的形式对其进行封装,最终得到了Spring Cloud,简化了开发者的工作。Spring Cloud当前主要是通过Netflix(网飞)公司的组件来实施微服务架构,但是因为Netflix的组件更新较慢(如Zuul 2.x版本经常不能如期发布,最后取消),并且只按自身企业需要进行更新(如Hystrix停止增加新功能),所以Spring Cloud有“去Netflix组件”的趋势。不过,“去Netflix组件”也需要一定的时间,所以当前还是以Netflix组件为主,这也是本书的核心内容之一。从另外一个角度来看,组件的目的是完成分布式的某些功能,虽类别不同但思想相近,也就是“换汤不换药”。因此,现在学了Netflix组件,即使将来不再使用,也可以吸收其思想和经验,通过这些来对比将来需要学习的新组件,也是大有裨益的。
为什么还要讲微服务之外的分布式系统的知识
在编写本书的时候,我考虑了很久,除了Spring Cloud微服务的内容外,还要不要加入其他分布式系统的内容,如分布式发号机、分布式数据库、分布式事务和缓存等。加入这些内容,本书似乎就没有鲜明的特点了,内容会显得有点杂;不加入这些内容,企业构建分布式系统的讲解就会不全面。
反复思考之后,我最终决定将一些常用的分布式知识也纳入本书进行讨论。换一个角度来考虑,微服务作为分布式系统的一种,其自身也是为了简化分布式系统的开发,满足企业生产实践的需要,同样,加入这些知识的讲解也是为了让企业能更好地搭建网站,和微服务架构的目的是一致的