在往表里面插入数据的时候,经常需要:a.先判断数据是否存在于库里面;b.不存在则插入;c.存在则更新
一、replace into
前提:数据库里面必须有主键或唯一索引,不然replace into 会直接插入新数据,导致数据表里面有重复数据
执行时先尝试插入数据:
a.当数据表里面存在(通过主键或唯一索引来判断)该数据,则先将表里的数据删除,再插入新的数据
b.如果数据表里面不存在该数据,则直接插入数据
replace into是insert into的增强版,语法跟insert iton差不多
replace into table_name(columns)values(values1,values2);
replace into table_name(columns) select columns from table_name2
测试数据(该表建立了一个复合的唯一索引user_add):
CREATE TABLE `relace_on` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`user_id` int(11) unsigned NOT NULL,
`interal` tinyint(3) unsigned NOT NULL,
`add_time` date NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `user_add` (`user_id`,`add_time`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=latin1;
插入测试数据:
INSERT INTO relace_on (user_id, interal, add_time)
VALUES
(1,20,'2016-05-06'),
(2,20,'2016-05-06'),
(3,20,'2016-05-06'),
(1,20,'2016-05-07'),
(2,20,'2016-05-07'),
(3,20,'2016-05-07')
现在数据库数据:
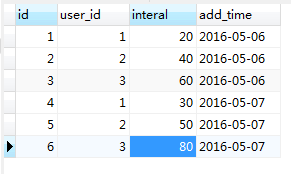
接下来执行一下replace into语句(存在):replace INTO relace_on(user_id, interal, add_time)values(1,40,'2016-05-06'),(2,60,'2016-05-06'),(3,80,'2016-05-06')
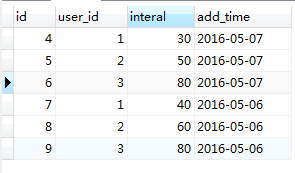 此时sql执行成功,受影响行数为6行(删除三条,插入三条)
此时sql执行成功,受影响行数为6行(删除三条,插入三条)
对比一下你会发现user_id(1,2,3)的账户在2016-05-06这一天原先都是有数据的,并且id为(1,2,3);现在执行了replace into后,id变成了(7,8,9),并且interal字段的值为执行语句的值,此时replace into语句根据数据表中的user_add这个复合的唯一索引发现在数据表中user_id为(1,2,3)的用户在2016-05-06这天各存在一条记录,这时就把原先的三条数据删除了,重新插入了三条,所以id从1,2,3变成了7,8,9;并且interal的值也变了
接下来执行一下replace into语句(不存在):replace INTO relace_on(user_id, interal, add_time)values(4,40,'2016-05-06'),(5,60,'2016-05-06'),(6,80,'2016-05-06')
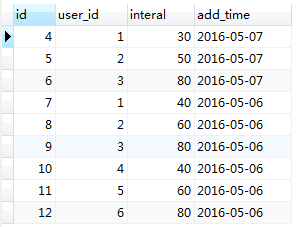 此时sql执行成功,受影响行数为3行(插入三条)
此时sql执行成功,受影响行数为3行(插入三条)
对比上图,你会发现原先的数据没变,只是新增了三条数据,同样是2016-05-06这天的,但是user_id是(4,5,6)根据user_add这个复合的唯一索引,这三条数据不存在数据表中,所以直接插入即可
二、on duplicate key update
它也是可以用于更新数据的,跟replace into有点相似,但是on duplicate key update是数据表里面存在该数据就更新,不存在则插入,;而replace into则是存在就删除,再插入,不存在则插入
依旧使用上面现有的数据来测试:
先添加一个字段,用于等下更新多个字段之用:ALTER TABLE `relace_on` ADD COLUMN `copy_interal` tinyint(3) UNSIGNED NOT NULL AFTER `interal`;
语法:
更新单个字段:insert into table_name(columns)values(values1,values2) on duplicate key update column=values(column)或者column=value(1,'zgw')
更新多个字段:insert into table_name(columns)values(values1,values2) on duplicate key update column1=values(column1),column2=values(column2)
执行一条语句(存在):insert into relace_on(user_id, interal,copy_interal, add_time)values(6,100,200,'2016-05-06') on duplicate KEY update interal=values(interal),copy_interal=values(copy_interal)
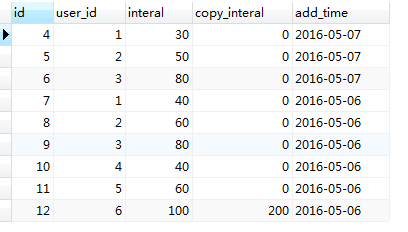
如图,user_id=6,add_time='2016-05-06'这条数据存在,则更新interal和copy_interal两个字段的值(interal原先为80,copy_interal新增字段默认为0)
再次执行一条语句(不存在):insert into relace_on(user_id, interal,copy_interal, add_time)values(7,100,200,'2016-05-06') on duplicate KEY update interal=values(interal),copy_interal=values(copy_interal)