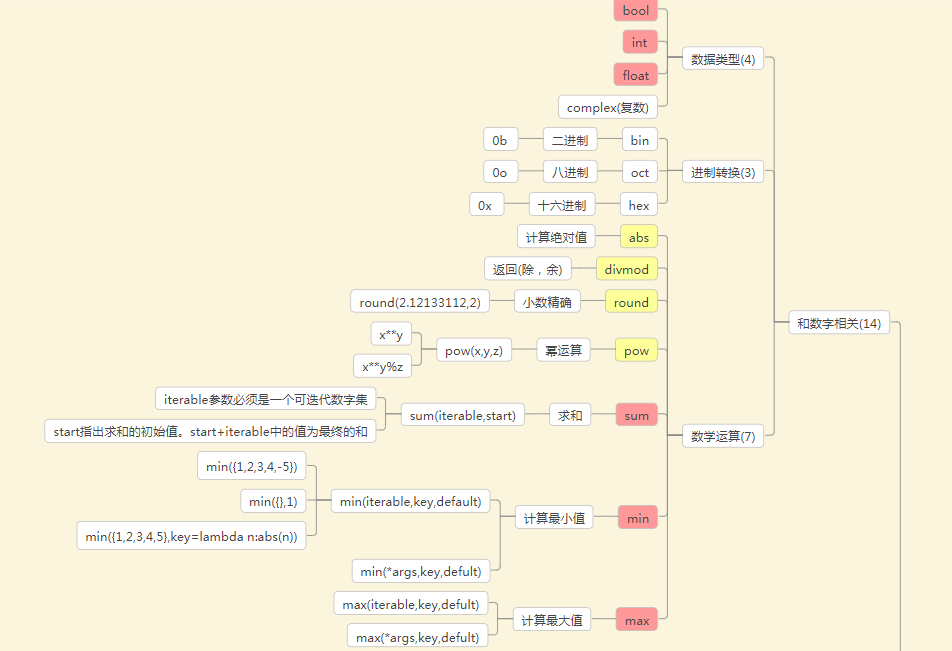
内置函数和匿名函数
python 一共有68个内置的函数;它们就是python提供给你直接可以拿来使用的所有函数
内置函数的图:链接 :https://www.processon.com/mindmap/5c515c42e4b03334b514da00
与数字相关的内置函数:
a = max({1,2,3,-4},key=abs) #比较绝对值的大小,取最大的
print(a)
a = divmod(7,3)
print(a) # (2,1)
print(sum([1,2,3,4],10)) #从10开始加;默认是从0开始加
其他的内置函数:

# 某个方法属于某个数据类型的变量,就用.调用
# 如果某个方法不依赖于任何数据类型,就直接调用 —— 内置函数 和 自定义函数
# f = open('1.复习.py')
# print(f.writable())
# print(f.readable())
#id #查看名字的内存地址
#hash - 对于相同可hash数据的hash值在一次程序的执行过程中总是不变的
# - 字典的寻址方式 ,一个k通过hash获得一个hash值,然后通过这个值来寻找vaule值。
# print(hash(12345))
# print(hash('hsgda不想你走,nklgkds'))
# print(hash(('1','aaa')))
# print(hash([])) # []是不可哈希(可变数据类型)
# ret = input('提示 : ')
# print(ret)
# print('我们的祖国是花园',end='') #指定输出的结束符
# print('我们的祖国是花园',end='')
# print(1,2,3,4,5,sep='|') #指定输出多个值之间的分隔符
# f = open('file','w')
# print('aaaa',file=f)
# f.close()
# exec('print(123)')
# eval('print(123)')
# print(eval('1+2+3+4')) # 有返回值
# print(exec('1+2+3+4')) #没有返回值
# exec和eval都可以执行 字符串类型的代码
# eval有返回值 —— 有结果的简单计算
# exec没有返回值 —— 简单流程控制
# eval只能用在你明确知道你要执行的代码是什么
# code = '''for i in range(10):
# print(i*'*')
# '''
# exec(code)
# code1 = 'for i in range(0,10): print (i)'
# compile1 = compile(code1,'','exec')
# exec(compile1)
# code2 = '1 + 2 + 3 + 4'
# compile2 = compile(code2,'','eval')
# print(eval(compile2))
# code3 = 'name = input("please input your name:")'
# compile3 = compile(code3,'','single')
# exec(compile3) #执行时显示交互命令,提示输入
# print(name)
# name #执行后name变量有值
# "'pythoner'"
基础数据类型的内置函数:

# reversed()
# l = [1,2,3,4,5]
# l.reverse() #reverse修改原列表
# print(l)
# l = [1,2,3,4,5]
# l2 = reversed(l)
# print(l2)
# 保留原列表,返回一个反向的迭代器
# l = (1,2,23,213,5612,342,43)
# sli = slice(1,5,2)
# print(l[sli])
# print(l[1:5:2])
# print(format('test', '<20'))
# print(format('test', '>40'))
# print(format('test', '^40'))
#bytes 转换成bytes类型
# 我拿到的是gbk编码的,我想转成utf-8编码,先decode(原来的类型),在encode(需要的类型)
# a=bytes('你好',encoding='GBK').decode('GBK') # unicode转换成GBK的bytes
# print(a.encode('utf-8'))
# print(bytes('你好',encoding='utf-8')) # unicode转换成utf-8的bytes
# 网络编程 只能传二进制
# 照片和视频也是以二进制存储
# html网页爬取到的也是编码
# b_array = bytearray('你好',encoding='utf-8')
# print(b_array)
# print(b_array[0])
# 'xe4xbdxa0xe5xa5xbd'
# s1 = 'alexa'
# s2 = 'alexb'
# l = 'ahfjskjlyhtgeoahwkvnadlnv'
# l2 = l[:10]
# 切片 —— 字节类型 不占内存
# 字节 —— 字符串 占内存
# print(ord('好'))
# print(ord('1'))
# print(chr(97))
# print(ascii('好'))
# print(ascii('1'))
# name = 'egg'
# print('你好%r'%name)
# print(repr('1'))
# print(repr(1))

# def is_odd(x):
# return x%2==1 #最后不是返回pool值, 也要转换为pool值。
# def is_str(x):
# return type(x) == str #最后不是返回pool值, 也要转换为pool值。
#
# ret = filter(is_str,[1,3,'acd',9,'123',10]) #把可迭代数据类型循环取值放入函数里判断是True,保留值,False过滤。
#
# # a = [i for i in [1,3,5,9,10] if i%2==1] #列表推导式带条件判断的就相当于filter
#
# print(ret) #<filter object at 0x000000000288C5C0> 迭代器
# for i in ret:
# print(i)
# ret = map(abs,[1,-4,6,-8])
# print(ret)
# for i in ret:
# print(i)
# filter 执行了filter之后的结果集合 <= 执行之前的个数
#filter只管筛选,不会改变原来的值
# map 执行前后元素个数不变
# 值可能发生改变
map,filter 中有相当于内置for循环可迭代对象的操作,从可迭代对象中一个一个的取值传入函数
#如下,每个小字典的name对应股票名字,shares对应多少股,price对应股票的价格
dic = [
{'name': 'IBM', 'shares': 100, 'price': 91.1},
{'name': 'AAPL', 'shares': 50, 'price': 543.22},
{'name': 'FB', 'shares': 200, 'price': 21.09},
{'name': 'HPQ', 'shares': 35, 'price': 31.75},
{'name': 'YHOO', 'shares': 45, 'price': 16.35},
{'name': 'ACME', 'shares': 75, 'price': 115.65}
]
# 计算购买每支股票的总价
ret = map(lambda dic:{dic['name']:round(dic['shares']*dic['price'],2)},dic)
print(list(ret))
# 过滤出单价大于100的股票有哪些
ret = filter(lambda dic:dic['price'] >100,dic)
for i in ret:
print(i['name'])
#zip
l = [1,2,3,4,5]
l2 = ['a','b','c','d']
l3 = ('*','**',[1,2])
d = {'k1':1,'k2':2} #字典取k
for i in zip(l,l2,l3,d): # 拉链式 按照最少的元素取
print(i)
#(1, 'a', '*', 'k1') #按列取值
#(2, 'b', '**', 'k2')
# l = [1,-4,6,5,-10]
# # l.sort(key = abs) # 在原列表的基础上进行排序
# # print(l)
#
# print(sorted(l,key=abs,reverse=True)) # 生成了一个新列表 不改变原列表 占内存
# print(l)
# l = [' ',[1,2],'hello world']
# new_l = sorted(l,key=len) #内置函数
# print(new_l)
匿名函数
函数名 = lambda 参数 :返回值
#参数可以有多个,用逗号隔开
#匿名函数不管逻辑多复杂,只能写一行,且逻辑执行结束后的内容就是返回值
#返回值和正常的函数一样可以是任意数据类型
# def add(x,y):
# return x+y
# add = lambda x,y:x+y
# print(add(1,2))
# dic={'k1':10,'k2':100,'k3':30}
# def func(key):
# return dic[key]
# print(max(dic,key=func)) #根据返回值判断最大值,返回值最大的那个参数是结果
# print(max(dic,key=lambda key:dic[key]))
关于匿名函数的面试题:
#面试题中,考匿名函数 就考 内置的函数与匿名函数的结合 #max(key=func) min(key=func)sorted(key=func) filter(func) map(func)这5个函数配合这匿名函数使用 # add = lambda x,y : x+y if x>y else x-y #返回值可以接一个三元运算符 # print(add(3,4)) #将这2个元组(('a'),('b')),(('c'),('d')) 通过匿名函数 转变为 [{'a': 'c'}, {'b': 'd'}] t1 = (('a'),('b')) t2 = (('c'),('d')) # ret = zip(t1,t2) # def func(tup): # return {tup[0]:tup[1]} # res = map(func,ret) res = map(lambda tup:{tup[0]:tup[1]},ret) print(list(res)) #数据类型的强制转换
#以下代码的输出是什么?请给出答案并解释。 def multipliers(): return [lambda x:i*x for i in range(4)] #返回一个列表推导式 print([m(2) for m in multipliers()]) #print([m(2) for m in [lambda x:i*x,lambda x:i*x,lambda x:i*x,lambda x:i*x]])
#m(2)匿名函数的调用
#实际上m所取的值为匿名函数(lambda x:i*x);最后的i为3;2*3=6
#[6, 6, 6, 6]
# 请修改multipliers的定义来产生期望的结果。想让i有变化。
def multipliers():
return (lambda x:i*x for i in range(4)) #返回一个生成器表达式
print([m(2) for m in multipliers()]) #此时for循环一次函数就执行一次取一个值;惰性运算
# lambda x:i*x,i = 0;lambda x:i*x,i = 1;.....
# [0, 2, 4, 6]
总结:
其他:input,print,type,hash,open,import,dir
str类型代码执行:eval,exec
数字:bool,int,float,abs,divmod,min,max,sum,round,pow
序列——列表和元组相关的:list和tuple
序列——字符串相关的:str,bytes,repr
序列:reversed,slice
数据集合——字典和集合:dict,set,frozenset
数据集合:len,sorted,enumerate,zip,filter,map
正则表达式
字符组 : [字符组] 在同一个位置可能出现的各种字符组成了一个字符组,在正则表达式中用[]表示 字符分为很多类,比如数字、字母、标点等等。 假如你现在要求一个位置"只能出现一个数字",那么这个位置上的字符只能是0、1、2...9这10个数之一。
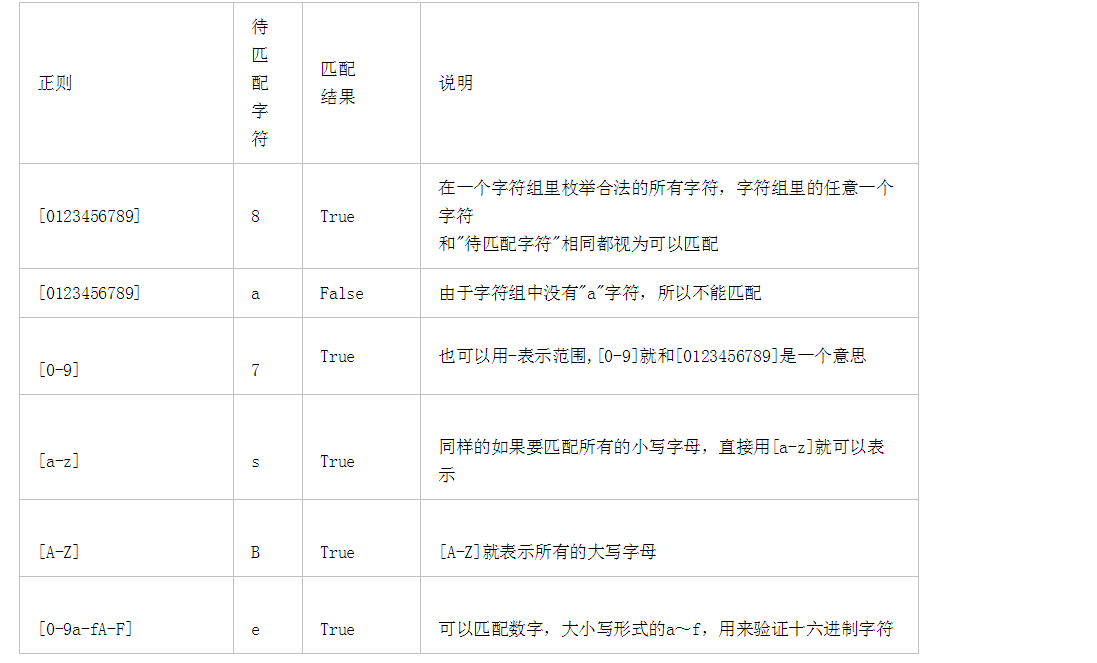



# ^ $ 匹配字符串的开始和结束
# () 分组 是对多个字符组整体量词约束的时候用的
#re模块:分组是有优先的
# findall
# split
# | 从左到右匹配,只要匹配上就不继续匹配了。所以应该把长的放前面
# [^] 除了字符组内的其他都匹配
# 量词
# * 0~
# + 1~
# ? 0~1
# {n} n
# {n,} n~
# {n,m} n~m
# 转义的问题 (. 加上就与原来的意思不一样了)
# import re
# re.findall(r'\s',r's')
# 惰性匹配
# 量词后面加问号
# .*?abc 一直取遇到abc就停
# re模块
# import re
# re.findall('d','awir17948jsdc',re.S)
# re.s 将字符串作为一个整体(无论字符串是否换行)
import re
a = """sdfkhellolsdlfsdfiooefo:
877898989worldafdsf"""
b = re.findall('hello(.*?)world',a)
c = re.findall('hello(.*?)world',a,re.S)
print ('b is ' , b)
print ('c is ' , c)
# 输出结果:
# b is []
# c is ['lsdlfsdfiooefo:
877898989']
#在字符串a中,包含换行符
,在这种情况下:
#如果不使用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重新开始。
#而使用re.S参数以后,正则表达式会将这个字符串作为一个整体,在整体中进行匹配#
# 返回值:列表 列表中是所有匹配到的项
# ret = search('d(w)+','awir17948jsdc')
# ret = search('d(?P<name>w)+','awir17948jsdc')
# 找整个字符串,遇到匹配上的就返回,遇不到就None
# 如果有返回值ret.group()就可以取到值
# 取分组中的内容 : ret.group(1) / ret.group('name')
# match
# 从头开始匹配,匹配上了就返回,匹配不上就是None
# 如果匹配上了 .group取值
# 分割 split
# 替换 sub 和 subn
# finditer 返回迭代器
# compile 编译 :正则表达式很长且要多次使用
.*?的用法:
. 是任意字符
* 是取 0 至 无限长度
? 是非贪婪模式。
在一起就是 取尽量少的任意字符,一般不会这么单独写,他大多用在:
.*?x
就是取前面任意长度的字符,直到一个x出现
在爬虫里面引用(.*?)
正则在re模块下的常用方法(python中):
import re
ret = re.findall('a', 'eva egon yuan') # 返回所有满足匹配条件的结果,放在列表里
print(ret) #结果 : ['a', 'a']
ret = re.search('a', 'eva egon yuan').group()
print(ret) #结果 : 'a'
# 函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以
# 通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None,则None.group()会报错
ret = re.match('a', 'abc').group() # 同search,不过尽在字符串开始处进行匹配
print(ret)
#结果 : 'a'
ret = re.split('[ab]', 'abcd') # 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割
print(ret) # ['', '', 'cd']
ret = re.sub('d', 'H', 'eva3egon4yuan4', 1)#将数字替换成'H',参数1表示只替换1个
print(ret) #evaHegon4yuan4
ret = re.subn('d', 'H', 'eva3egon4yuan4')#将数字替换成'H',返回元组(替换的结果,替换了多少次)
print(ret)
obj = re.compile('d{3}') #正则表达式很长,并且要多次调用时,则需要编译;将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字
ret = obj.search('abc123eeee') #正则表达式对象调用search,参数为待匹配的字符串
print(ret.group()) #结果 : 123
import re
ret = re.finditer('d', 'ds3sy4784a') #finditer返回一个存放匹配结果的迭代器
print(ret) # <callable_iterator object at 0x10195f940>
print(next(ret).group()) #查看第一个结果
print(next(ret).group()) #查看第二个结果
print([i.group() for i in ret]) #查看剩余的左右结果
注意:
1 findall的优先级查询:
import re
ret = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com')
print(ret) # ['oldboy'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可
ret = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com')
print(ret) # ['www.oldboy.com']
2 split的优先级查询
ret=re.split("d+","eva3egon4yuan")
print(ret) #结果 : ['eva', 'egon', 'yuan']
ret=re.split("(d+)","eva3egon4yuan")
print(ret) #结果 : ['eva', '3', 'egon', '4', 'yuan']
#在匹配部分加上()之后所切出的结果是不同的,
#没有()的没有保留所匹配的项,但是有()的却能够保留了匹配的项,
#这个在某些需要保留匹配部分的使用过程是非常重要的。
爬虫的应用:
import re
from urllib.request import urlopen
def getPage(url):
response = urlopen(url)
return response.read().decode('utf-8')
def parsePage(s):
com = re.compile(
'<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>d+).*?<span class="title">(?P<title>.*?)</span>'
'.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>', re.S)
ret = com.finditer(s)
for i in ret:
yield {
"id": i.group("id"),
"title": i.group("title"),
"rating_num": i.group("rating_num"),
"comment_num": i.group("comment_num"),
}
def main(num):
url = 'https://movie.douban.com/top250?start=%s&filter=' % num
response_html = getPage(url)
ret = parsePage(response_html)
# print(ret)
# f = open("move_info7", "a", encoding="utf8")
for obj in ret:
print(obj)
# data = str(obj)
# f.write(data + "
")
count = 0
for i in range(2):
main(count)
count += 25
模块
一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀。
模块的使用:
所有的模块导入都应该尽量往上写,并且尽量的按照下面的顺序来写
1内置模块
2扩展模块 (不是python自带的需要下载的模块)
3自定义模块
模块不会重复被导入 : sys.moudles #每次导入模块时先判断 sys.moudles 里面是否有,有就不导入了,没有则导入
从哪儿导入模块 : sys.path
#import
import 模块名
模块名.变量名 和本文件中的变量名完全不冲突
import 模块名 as 重命名的模块名 : 提高代码的兼容性
import 模块1,模块2
#from import
from 模块名 import 变量名
直接使用 变量名 就可以完成操作
如果本文件中有相同的变量名会发生冲突
from 模块名 import 变量名字 as 重命名变量名
from 模块名 import 变量名1,变量名2
from 模块名 import *
将模块中的所有变量名都放到内存中
如果本文件中有相同的变量名会发生冲突
from 模块名 import * 和 __all__=[] 是一对
没有这个变量,就会导入所有的名字
如果有all 只导入all列表中的名字
#__name__
在模块中 有一个变量__name__,当我们直接执行这个模块的时候,__name__ == '__main__'
当我们执行其他模块,在其他模块中引用这个模块的时候,这个模块中的__name__ == '模块的名字'
我们可以通过模块的全局变量__name__来查看模块名
__name__作用:用来控制.py文件在不同的应用场景下执行不同的逻辑
if __name__ == '__main__':
常用模块
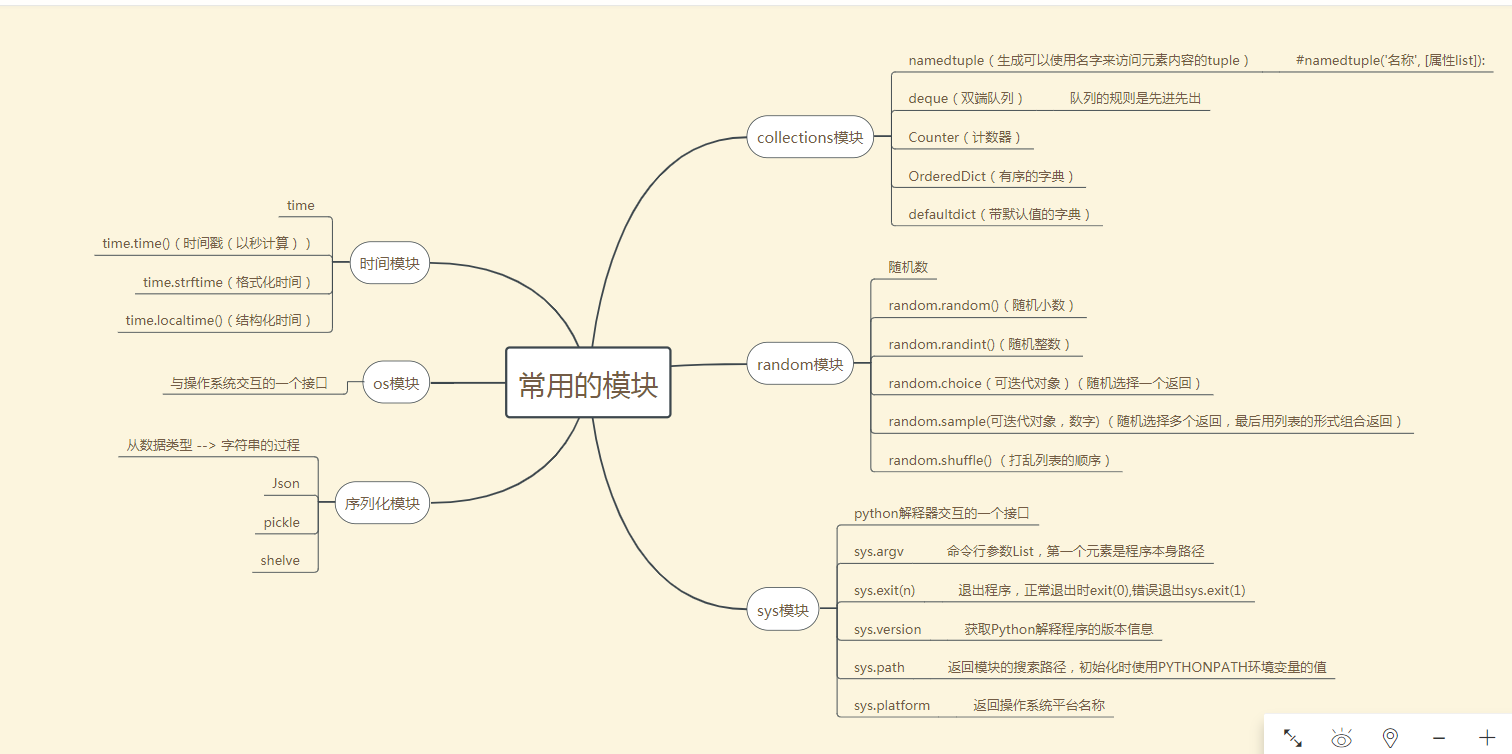
collections模块:在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。
#列表、元祖
#字典
#集合、frozenset
#字符串
#堆栈 : 先进后出
#队列 :先进先出 FIFO
# from collections import namedtuple
# Point = namedtuple('point',['x','y','z'])
# p1 = Point(1,2,3)
# p2 = Point(3,2,1)
# print(p1.x)
# print(p1.y)
# print(p1,p2)
#namedtuple('名称', [属性list]):
Circle = namedtuple('Circle', ['x', 'y', 'r'])
#花色和数字
# Card = namedtuple('card',['suits','number'])
# c1 = Card('红桃',2)
# print(c1)
# print(c1.number)
# print(c1.suits)
#队列
# import queue
# q = queue.Queue()
# q.put([1,2,3])
# q.put(5)
# q.put(6)
# print(q)
# print(q.get())
# print(q.get())
# print(q.get())
# print(q.get()) # 阻塞
# print(q.qsize())
#双队列
# from collections import deque
# dq = deque([1,2])
# dq.append('a') # 从后面放数据 [1,2,'a']
# dq.appendleft('b') # 从前面放数据 ['b',1,2,'a']
# dq.insert(2,3) #['b',1,3,2,'a']
# print(dq.pop()) # 从后面取数据
# print(dq.pop()) # 从后面取数据
# print(dq.popleft()) # 从前面取数据
# print(dq)
#有序字典
# from collections import OrderedDict
# od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
# print(od) # OrderedDict的Key是有序的
# print(od['a'])
# for k in od:
# print(k)
#使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict:
# from collections import defaultdict
# d = defaultdict(lambda : 5) # defaultdict(可调用的) 因此要返回数,必须用匿名函数
# print(d['k'])
时间模块:
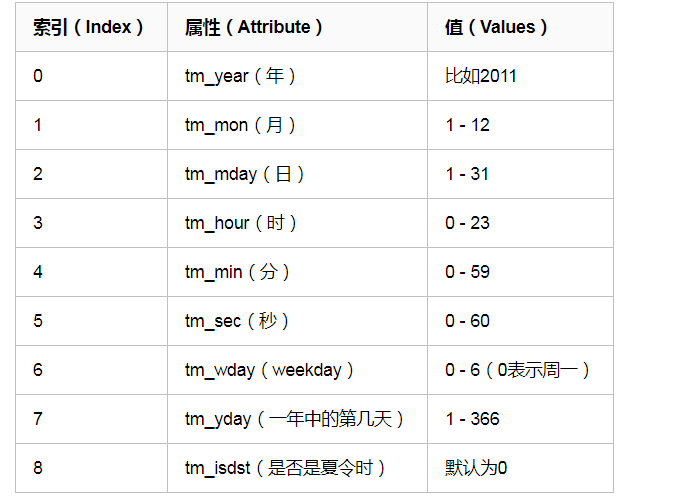
在Python中,通常有这三种方式来表示时间:时间戳、元组(struct_time)、格式化的时间字符串:
1 时间戳(timestamp):时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量,用time.time()得到。
2 结构化时间(元组时间)(struct_time):struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天等) 也就是namedtuple带名字的元组
3 格式化时间(Format String): ‘1999-12-06’
python中时间日期格式化符号:
%y 两位数的年份表示(00-99) %Y 四位数的年份表示(000-9999) %m 月份(01-12) %d 月内中的一天(0-31) %H 24小时制小时数(0-23) %I 12小时制小时数(01-12) %M 分钟数(00=59) %S 秒(00-59) %a 本地简化星期名称 %A 本地完整星期名称 %b 本地简化的月份名称 %B 本地完整的月份名称 %c 本地相应的日期表示和时间表示 %j 年内的一天(001-366) %p 本地A.M.或P.M.的等价符 %U 一年中的星期数(00-53)星期天为星期的开始 %w 星期(0-6),星期天为星期的开始 %W 一年中的星期数(00-53)星期一为星期的开始 %x 本地相应的日期表示 %X 本地相应的时间表示 %Z 当前时区的名称 %% %号本身
#导入时间模块
>>>import time
#时间戳
>>>time.time()
1500875844.800804
#时间字符串
>>>time.strftime("%Y-%m-%d %X")
'2017-07-24 13:54:37'
>>>time.strftime("%Y-%m-%d %H-%M-%S")
'2017-07-24 13-55-04'
#时间元组:localtime将一个时间戳转换为当前时区的struct_time
time.localtime()
time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24,
tm_hour=13, tm_min=59, tm_sec=37,
tm_wday=0, tm_yday=205, tm_isdst=0)
小结:时间戳是计算机能够识别的时间;时间字符串(格式化时间)是人能够看懂的时间;元组(结构化时间)则是用来操作时间的
3种格式的相互转换:

时间戳和结构化时间的相互转换
#时间戳-->结构化时间 #time.gmtime(时间戳) #UTC时间,与英国伦敦当地时间一致 #time.localtime(时间戳) #当地时间。例如我们现在在北京执行这个方法:与UTC时间相差8小时,UTC时间+8小时 = 北京时间 >>>time.gmtime(1500000000) time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=2, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0) >>>time.localtime(1500000000) time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=10, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0) #结构化时间-->时间戳 #time.mktime(结构化时间) >>>time_tuple = time.localtime(1500000000) >>>time.mktime(time_tuple) 1500000000.0
结构化时间和格式化时间的相互转换
#结构化时间-->字符串时间
#time.strftime("格式定义","结构化时间") 结构化时间参数若不传,则显示当前时间
>>>time.strftime("%Y-%m-%d %H:%M:%S")
'2017-07-24 14:55:36'
>>>time.strftime("%Y-%m-%d",time.localtime(1500000000))
'2017-07-14'
#字符串时间-->结构化时间
#time.strptime(时间字符串,字符串对应格式)
>>>time.strptime("2017-03-16","%Y-%m-%d")
time.struct_time(tm_year=2017, tm_mon=3, tm_mday=16, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=75, tm_isdst=-1)
>>>time.strptime("07/24/2017","%m/%d/%Y")
time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=0, tm_yday=205, tm_isdst=-1)
#结构化时间 --> %a %b %d %H:%M:%S %Y串
#time.asctime(结构化时间) 如果不传参数,直接返回当前时间的格式化串
>>>time.asctime(time.localtime(1500000000))
'Fri Jul 14 10:40:00 2017'
>>>time.asctime()
'Mon Jul 24 15:18:33 2017'
#时间戳 --> %a %b %d %H:%M:%S %Y串
#time.ctime(时间戳) 如果不传参数,直接返回当前时间的格式化串
>>>time.ctime()
'Mon Jul 24 15:19:07 2017'
>>>time.ctime(1500000000)
'Fri Jul 14 10:40:00 2017'
因此在计算时间差的时间,先转化为时间戳来计算时间差,然后通过结构化时间再到格式化时间。
random模块
import random
#随机小数
random.random() # 大于0且小于1之间的小数
0.7664338663654585
random.uniform(1,3) #大于1小于3的小数
1.6270147180533838
#恒富:发红包
#随机整数
random.randint(1,5) # 大于等于1且小于等于5之间的整数
random.randrange(1,10,2) # 大于等于1且小于10之间的奇数
#随机选择一个返回
random.choice([1,'23',[4,5]]) # #1或者23或者[4,5]
#随机选择多个返回,返回的个数为函数的第二个参数
random.sample([1,'23',[4,5]],2) # #列表元素任意2个组合
[[4, 5], '23']
#打乱列表顺序
item=[1,3,5,7,9]
random.shuffle(item) # 打乱次序
item
[5, 1, 3, 7, 9]
random.shuffle(item)
item
[5, 9, 7, 1, 3]
os模块
os模块是与操作系统交互的一个接口
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.system("bash command") 运行shell命令,直接显示
os.popen("bash command).read() 运行shell命令,获取执行结果
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.path
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录(文件夹),则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回文件的大小
如果想要计算文件夹的大小的话:
要循环文件夹里面的所有的文件,然后再相加起来。
序列化模块:
将原本的字典、列表等数据类型内容转换成一个字符串的过程就叫做序列化。
序列化的目的

有3中方法:json;pickle,shelve
# json 中只有这些:数字 字符串 列表 字典 元组 才能转化为字符串
# 通用的序列化格式
# 只有很少的一部分数据类型能够通过json转化成字符串
# pickle
# 所有的python中的数据类型都可以转化成字符串形式
# pickle序列化的内容只有python能理解
# 且部分反序列化依赖python代码
# shelve
# 序列化句柄
# 使用句柄直接操作,非常方便
json中的方法:
# json dumps序列化方法 loads反序列化方法
# dic = {1:"a",2:'b'}
# print(type(dic),dic)
# import json
# str_d = json.dumps(dic) # 序列化
# print(type(str_d),str_d)
# # '{"kkk":"v"}'
# dic_d = json.loads(str_d) # 反序列化
# print(type(dic_d),dic_d)
import json
# json 中的 dump load 的方法只是在文件中操作的,而dumps,loads是在内存中
# dic = {1:"a",2:'b'}
# f = open('fff','w',encoding='utf-8')
# json.dump(dic,f)
# f.close()
# f = open('fff')
# res = json.load(f)
# f.close()
# print(type(res),res)
注意:如果写入的内容是中文,要设置ensure_ascii关键字参数
import json
json dump load
dic = {1:"中国",2:'b'}
f = open('fff','w',encoding='utf-8')
json.dump(dic,f,ensure_ascii=False)
f.close()
f = open('fff',encoding='utf-8')
res1 = json.load(f)
f.close()
print(type(res1),res1)
在json中的load和dump不能直接一行一行的读或者是写,他是全部读出来的。
只能用间接的方法去读或者是写:
json
dumps {} -- > '{}
'
一行一行的读
'{}
'
'{}' loads
l = [{'k':'111'},{'k2':'111'},{'k3':'111'}]
f = open('file','w')
import json
for dic in l:
str_dic = json.dumps(dic)
f.write(str_dic+'
')
f.close()
f = open('file')
import json
l = []
for line in f:
dic = json.loads(line.strip())
l.append(dic)
f.close()
print(l)
pickle:
里面的方法个json一样,不过有区别:
import pickle #二进制,并且文件内容看不懂 ,可以直接一行一行的写人,一行一行的读出
dic = {'k1':'v1','k2':'v2','k3':'v3'}
str_dic = pickle.dumps(dic)
print(str_dic) #一串二进制内容
dic2 = pickle.loads(str_dic)
print(dic2) #字典
import pickle
import time
struct_time1 = time.localtime(1000000000)
struct_time2 = time.localtime(2000000000)
f = open('pickle_file','wb')
pickle.dump(struct_time1,f)
pickle.dump(struct_time2,f)
f.close()
f = open('pickle_file','rb')
struct_time1 = pickle.load(f)
struct_time2 = pickle.load(f)
print(struct_time1.tm_year)
print(struct_time2.tm_year)
f.close()
shelve:
import shelve
f = shelve.open('shelve_file') #得到一个句柄
f['key'] = {'int':10, 'float':9.5, 'string':'Sample data'} #直接对文件句柄操作,就可以存入数据
f.close()
import shelve
f1 = shelve.open('shelve_file')
existing = f1['key'] #取出数据的时候也只需要直接用key获取即可,但是如果key不存在会报错
f1.close()
print(existing)
注意: writeback关键字:
#{'int': 10, 'float': 9.5, 'string': 'Sample data', 'new_value': ''}
import shelve
f1 = shelve.open('shelve_file')
# print(f1['key'])
f1['key']['new_value'] = 'this was not here before'
f1.close()
f2 = shelve.open('shelve_file')
print(f2['key'])
#{'int': 10, 'float': 9.5, 'string': 'Sample data', 'new_value': ''}
#在shelve.open(writeback=True)后 才能把下面你所修改的内容所显示出来
import shelve
f2 = shelve.open('shelve_file',writeback=True)
f2['key']['new_value'] = 'this was not here before'
f2.close()
f1 = shelve.open('shelve_file')
print(f1['key'])
#{'int': 10, 'float': 9.5, 'string': 'Sample data', 'new_value': 'this was not here before'}
包
也就是把解决一类问题的模块放在同一个文件夹里 —— 包
注意点:
1. 无论是import形式还是from...import形式,凡是在导入语句中(而不是在使用时)遇到带点的,都要第一时间提高警觉:这是关于包才有的导入语法
2. 包是目录级的(文件夹级),文件夹是用来组成py文件(包的本质就是一个包含__init__.py文件的目录)
3. import导入文件时,产生名称空间中的名字来源于文件,import 包,产生的名称空间的名字同样来源于文件,即包下的__init__.py,导入包本质就是在导入该文件
强调:
1. 在python3中,即使包下没有__init__.py文件,import 包仍然不会报错,而在python2中,包下一定要有该文件,否则import 包报错
2. 创建包的目的不是为了运行,而是被导入使用,记住,包只是模块的一种形式而已,包即模块
包导入的原则:
凡是在导入时带点的,点的左边都必须是一个包,否则非法。可以带有一连串的点,如item.subitem.subsubitem,但都必须遵循这个原则。
import 包 ,是先执行包里面__init__文件(即初始化文件)
导入包的时候:
需要注意的是from后import导入的模块,必须是明确的一个不能带点,否则会有语法错误,如:from a import b.c是错误语法
#.的左边必须是包。
# import glance.db.models as ms
# ms.register_models('mysql')
# from glance.api.policy import get #在from import 中.只能再from 中出现,不能再import中出现
# get()
# from glance.api import * # *与__all__=[],限制变量名
# policy.get()
# versions.create_resource(1)
绝对导入和相对导入
绝对导入:具体到名字
相对导入:用.(当前的目录)或者..(上一层的目录)的方式最为起始(只能在一个包中使用,不能用于不同目录内)
#绝对路径导入
# import glance.api.policy as pl
# pl.get()
#只import glance ,就可以使用这个包里面的所有的方法
# import glance #从外面执行的根目录为练习
# glance.api.policy.get()
# glance.api.versions.create_resource(2)
#相对路径 #.当前的目录;..上一层的目录
# import glance
#包里的模块如果想使用其它模块的内容只能使用相对路径,使用了相对路径就不能在包内直接执行了.
特别需要注意的是:可以用import导入内置或者第三方模块(已经在sys.path中),但是要绝对避免使用import来导入自定义包的子模块(没有在sys.path中),应该使用from... import ...的绝对或者相对导入,且包的相对导入只能用from的形式。
初始面向对象
面向过程的程序设计的核心是过程(流水线式思维),过程即解决问题的步骤,面向过程的设计就好比精心设计好一条流水线,考虑周全什么时候处理什么东西。
优点是:极大的降低了写程序的复杂度,只需要顺着要执行的步骤,堆叠代码即可
缺点是:一套流水线或者流程就是用来解决一个问题,代码牵一发而动全身。
应用场景:一旦完成基本很少改变的场景
面向对象的程序设计的
优点是:解决了程序的扩展性。对某一个对象单独修改,会立刻反映到整个体系中,如对游戏中一个人物参数的特征和技能修改都很容易。
缺点:可控性差,无法向面向过程的程序设计流水线式的可以很精准的预测问题的处理流程与结果,面向对象的程序一旦开始就由对象之间的交互解决问题,谁都无法预测最终结果。
python中一切皆为对象,类型的本质就是类。
类和对象的概念以及用法:
概念:在python中,用变量表示特征,用函数表示技能,因而具有相同特征和技能的一类事物就是‘类’,对象是则是这一类事物中具体的一个。
在类中 函数叫做 方法
用法:
# 自定义类
# def 函数名():
# pass
# class 类名:
# 属性 = 'a'
#
# print(类名.属性)
# 类名的作用 就是操作属性 查看属性
# class Person: # 类名
# country = 'China' # 创造了一个只要是这个类就一定有的属性
# # 类属性 静态属性
# def __init__(self,*args): # 初始化方法,self是对象,是一个必须传的参数
# # self就是一个可以存储很多属性的大字典
# self.name = args[0] # 往字典里添加属性的方式发生了一些变化
# self.hp = args[1]
# self.aggr = args[2]
# self.sex = args[3]
#
# def walk(self,n): # 方法,一般情况下必须传self参数,且必须写在第一个
# # 后面还可以传其他参数,是自由的
# print('%s走走走,走了%s步'%(self.name,n))
#
# # print(Person.country) # 类名 可以查看类中的属性,不需要实例化就可以查看
# alex = Person('狗剩儿',100,1,'不详') # 类名还可以实例化对象,alex对象 # 实例化
# # print(alex.__dict__) # 查看所有属性
# print(alex.name) # 查看属性值
# # print(alex.hp) # 查看属性值
# alex.walk(5) # Person.walk(alex,5) # 调用方法 类名.方法名(对象名)
# 对象 = 类名()
# 过程:
# 类名() 首先 会创造出一个对象,创建了一个self变量(相当于一个大的字典)
# 调用__init__方法,类名括号里的参数会被这里接收
# 执行__init__方法
# 返回self 给对象
# 对象能做的事:
# 查看属性 对象.属性名
# 调用方法 对象.方法名(除self的其他的参数)
# __dict__ 对于对象的增删改查操作都可以通过字典的语法进行
# 类名能做的事:
# 实例化 对象 = 类名()
# 调用方法 : 只不过要自己传递self参数 类.方法名(对象,其他的参数)
# 调用类中的属性,也就是调用静态属性(类属性)
# __dict__ 对于类中的名字只能看 不能操作
对类属性的一个补充:
# 一:我们定义的类的属性到底存到哪里了?
# 有两种方式查看:
# dir(类名):查出的是一个名字列表
# 类名.__dict__:查出的是一个字典,key为属性名,value为属性值
#
# 二:特殊的类属性
# 类名.__name__# 类的名字(字符串)
# 类名.__doc__# 类的文档字符串
# 类名.__base__# 类的第一个父类(在讲继承时会讲)
# 类名.__bases__# 类所有父类构成的元组(在讲继承时会讲)
# 类名.__dict__# 类的字典属性
# 类名.__module__# 类定义所在的模块
# 类名.__class__# 实例对应的类(仅新式类中)
类命名空间与对象(实例)的命名空间
创建一个类就会创建一个类的名称空间,用来存储类中定义的所有名字,这些名字称为类的属性
而类有两种属性:静态属性和动态属性
- 静态属性就是直接在类中定义的变量
- 动态属性就是定义在类中的方法
类和对象的命名空间都是相互独立的,对象与对象的命名空间也是相互独立的
# 类里 可以定义两种属性
# 静态属性 :就是直接在类中定义的变量 (类属性)
# 动态属性 : 就是定义在类中的方法(方法名)
class Course:
language = ['Chinese'] #静态属性
def __init__(self,teacher,course_name,period,price):
self.teacher = teacher
self.name = course_name
self.period = period
self.price = price
def func(self):
pass
# Course.language = 'English'
# # Course.__dict__['language'] = 'Chinese' #类使用__dict__方法不能修改静态属性
# print(Course.language)
#'English'
python = Course('egon','python','6 months',20000)
linux = Course('oldboy','linux','6 months',20000)
#['chinese']
# python.language = 'English' #不可变的数据类型;此时相当于在对象的命名空间内创造了一个language = 'English'一个键值对。
# print(python.language) #而其他的命名空间还是原来的
# print(Course.language) #重新赋值是独立的,只是独立于在python的这一个对象的命名空间内。
# print(linux.language)
#['Chinese'];English;['Chinese']
# python.language[0] = 'English' #相当于只是修改了列表中的0索引的内存地址变为'English'的内存地址了,其他没有变化;
# print(python.language) #此时的修改则是共享的了
# print(Course.language)
# print(linux.language)
#['English'];['English'];['English']
# del python.language #删除对象中的键值对
# print(python.language)
类中的静态变量 可以被对象和类调用
对于不可变数据类型来说,类变量最好用类名操作
对于可变数据类型来说,对象名的修改是共享的,重新赋值是独立的练习:
# 创建一个类,每实例化一个对象就计数
# 最终所有的对象共享这个数据
class Foo:
count = 0
def __init__(self):
# self.count += 1 #错误的,这是在自己的命名空间创造了一个count变量名
Foo.count +=1
f1 = Foo()
f2 = Foo()
print(f1.count)
print(f2.count)
f3 = Foo()
print(f1.count)
# 认识绑定方法
# def func():pass
# print(func)
#
# class Foo:
# def func(self):
# print('func')
# def fun1(self):
# pass
# f1 = Foo()
# print(Foo.func)
# print(f1.func)
# print(f1.fun1)
#<bound method Foo.func of f1> #对象绑定函数
# a=1
# class A: #类是一个独立的命名空间,不能用全局变量的名字
# pass
# c = A()
# print(c.a) #找不到a
#包中的__init__函数:
# import 包或者是模块 ————》》 类的实例化过程,自动执行了__init__方法
# 模块.方法名() 与 对象.方法名() 类似
类里的名字有 类变量(静态属性量)+ 方法名(动态属性)
对象里的名字 对象属性
对象 —— > 类 #只能是单向的寻找
对象找名字 : 先找自己的 找类的 再找不到就报错 ;而类不能寻找对象的属性
对象修改静态属性的值
对于不可变数据类型来说,类变量最好用类名操作
对于可变数据类型来说,对象名的修改是共享的,重新赋值是独立的
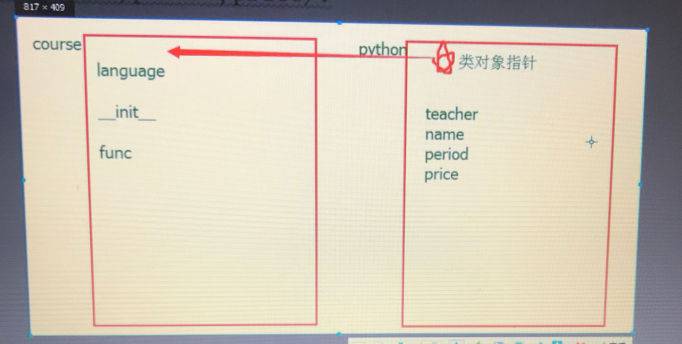
面向对象的组合用法:
组合 :一个对象的属性值 = 另外一个类的对象
class Teacher: def __init__(self,name,sex,brith): self.name = name self.sex = sex self.brith = brith self.course = Course(self.name,'python','6 month',20000) class Brith: def __init__(self,year,month,day): self.year = year self.moth = month self.day = day class Course: language = 'Chinese' def __init__(self,teacher,course_name,period,price): self.teacher = teacher self.course_name = course_name self.period = period self.price = price B=Brith('2018','12','20') teacher = Teacher('alex','男',B) #组合,就是 对象的属性值 = 另外一个类的对象 # print(teacher.brith.year) # 组合 print(teacher.course.course_name)
# 圆形类
# 圆环类
from math import pi
class Circle:
def __init__(self,r):
self.r = r
def area(self):
return self.r**2 * pi
def perimeter(self):
return 2*pi*self.r
class Ring:
def __init__(self,outside_r,inside_r):
self.outside_c = Circle(outside_r) #组合
self.inside_c = Circle(inside_r) #组合
def area(self):
return self.outside_c.area() - self.inside_c.area()
def perimeter(self):
return self.outside_c.perimeter()+self.inside_c.perimeter()
面向对象的三大特征
继承;多态;封装
继承是一种创建新类的方式,在python中,新建的类可以继承一个或多个父类,父类又可称为基类或超类,新建的类称为派生类或子类
在python中继承分为单继承和多继承;
单继承:继承一个类;多继承:继承多一个类,并且用逗号分隔开
# class A(object):pass # 父类,基类,超类
# class B:pass # 父类,基类,超类
# class A_son(A,B):pass # 子类,派生类
# class AB_son(A):pass # 子类,派生类
# 一个类 可以被多个类继承
# 一个类 可以继承多个父类 —— python里
# print(A_son.__bases__)
# print(AB_son.__bases__) #__bases__可以查看子类中所继承的所有的父类;__base__,查看从左到右第一个继承的父类;
# print(A.__bases__) # python3 -新式类# 没有继承父类默认继承object
父类中没有的属性 在子类中出现 叫做派生属性
父类中没有的方法 在子类中出现 叫做派生方法
#只要是子类的对象调用,子类中有的名字 一定用子类的,子类中没有才找父类的,如果父类也没有报错-->自己有的就用自己的,自己没有就调用父类的
如果父类 子类都有 用子类的
如果还想用父类的,单独调用父类的:
父类名.方法名 需要自己传self参数
super().方法名 不需要自己传self.
正常的代码中 单继承 === 减少了代码的重复 == 重用性
继承表达的是一种 子类是父类的关系;什么是什么的关系;狗是动物
class Animal:
def __init__(self,name,aggr,hp):
self.name = name
self.aggr = aggr
self.hp = hp
def eat(self):
print('吃药回血')
self.hp+=100
class Dog(Animal):
def __init__(self,name,aggr,hp,kind):
Animal.__init__(self,name,aggr,hp) #单独调用父类 中的self是Dog类创建的对象
self.kind = kind # 派生属性
def eat(self):
Animal.eat(self) # 如果既想实现新的功能也想使用父类原本的功能,还需要在子类中再调用父类
self.teeth = 2
def bite(self,person): # 派生方法
person.hp -= self.aggr
jin = Dog('金老板',100,500,'吉娃娃')
jin.eat()
print(jin.hp)
class Animal:
def __init__(self,name,aggr,hp):
self.name = name
self.aggr = aggr
self.hp = hp
def eat(self):
print('吃药回血')
self.hp+=100
class Dog(Animal):
def __init__(self,name,aggr,hp,kind):
super().__init__(name,aggr,hp) # 只在python3有,python3中所有类都是新式类
self.kind = kind # 派生属性
def eat(self):print('dog eating')
jin = Dog('金老板',200,500,'teddy')
print(jin.name)
jin.eat()
super(Dog,jin).eat()
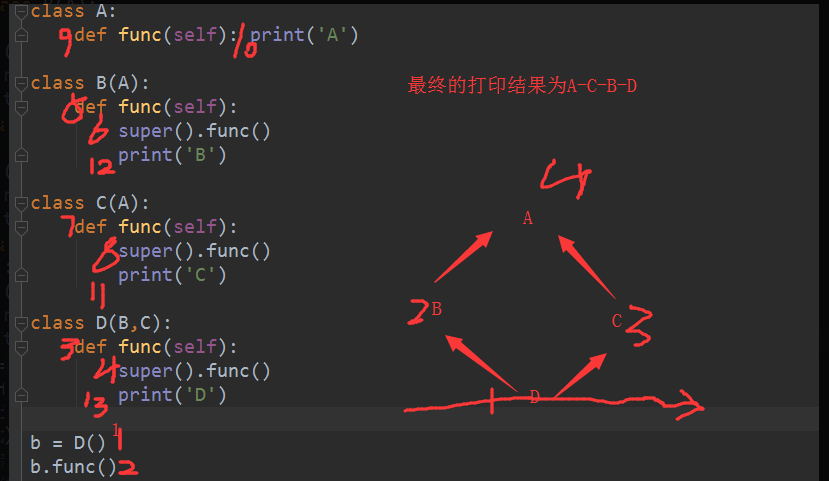
在多继承中有继承的顺序:
新式类中的继承顺序 : 广度优先 #在python3中
经典类中的继承顺序 : 深度优先,一路走到底,走过的路就不走, 在py2中
py2中有经典类和新式类;但是py3中只有新式类
python2.7
新式类 继承object类的才是新式类 广度优先
经典类 如果你直接创建一个类在2.7中就是经典类 深度优先
print(D.mro())
D.mro() #查看广度优先的继承顺序
单继承 : 子类有的用子类 子类没有用父类
多继承中,我们子类的对象调用一个方法,默认是就近原则,找的顺序是什么?
经典类中 深度优先
新式类中 广度优先
python2.7 新式类和经典类共存,新式类要继承object
python3 只有新式类,默认继承object
经典类和新式类还有一个区别 mro方法只在新式类中存在
super 只在python3中存在
super的本质 :不是单纯找父类 而是根据调用者的节点位置的广度优先顺序来的#根据广度优先按照继承顺序寻找上一个类。
class A:
def func(self): print('A')
class B(A):
def func(self):
super().func()
print('B')
class C(A):
def func(self):
super().func()
print('C')
class D(B,C):
def func(self):
super().func()
print('D')
b = D()
b.func()
print(B.mro())
钻石继承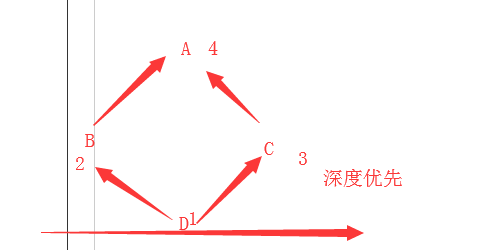
# class F:
# def func(self): print('F')
# class A(F):pass
# # def func(self): print('A')
# class B(A):
# pass
# # def func(self): print('B')
# class E(F):pass
# # def func(self): print('E')
# class C(E):
# pass
# # def func(self): print('C')
#
# class D(B,C):
# pass
# # def func(self):print('D')
#
# d = D()
# # d.func()
# print(D.mro())
super的本质 :在单继承中是找一个父类;但是多继承中不是单纯找父类 而是根据调用者的节点位置的广度优先顺序来的#根据广度优先按照继承顺序寻找上一个类。
class A:
def func(self): print('A')
class B(A):
def func(self):
super().func()
print('B')
class C(A):
def func(self):
super().func()
print('C')
class D(B,C):
def func(self):
super().func()
print('D')
b = D()
b.func()
print(B.mro())
继承的作用:
减少代码的重用
提高代码可读性
规范编程模式
接口类与抽象类
接口类 : python原生不支持;支持多继承,接口类中的所有的方法都必须不能实现 —— java
抽象类 : python原生支持的;不支持多继承,抽象类中方法可以有一些代码的实现 —— java
python中没有接口类,有抽象类,abc模块中的metaclass = ABCMeta,@abstructmethod
本质是做代码规范用的,希望在子类中实现和父类方法名字完全一样的方法
接口类与抽象类的区别:
在java的角度上看是有区别的:
1.java本来就支持单继承 所以就有了抽象类
2.java没有多继承 所以为了接口隔离原则,设计了接口这个概念,支持多继承了。
接口隔离原则:使用多个专门的接口,而不使用单一的总接口。即客户端不应该依赖那些不需要的接口。
python及支持单继承也支持多继承,所以对于接口类和抽象类的区别就不那么明显了
甚至在python中没有内置接口类,有下载的模块可以实现接口类。
接口类的单继承
from abc import abstractmethod,ABCMeta
class Payment(metaclass=ABCMeta): # 元类 默认的元类 type
@abstractmethod
def pay(self,money):pass # 没有实现这个方法;接口类的单继承
class Wechat(Payment):
def pay(self,money):
print('已经用微信支付了%s元'%money)
class Alipay(Payment):
def pay(self,money):
print('已经用支付宝支付了%s元' % money)
class Applepay(Payment):
def pay(self,money):
print('已经用applepay支付了%s元' % money)
def pay(pay_obj,money): # 统一支付入口
pay_obj.pay(money)
# wechat = Wechat()
# ali = Alipay()
app = Applepay()
# wechat.pay(100)
# ali.pay(200)
p = Payment()
# 接口类的继承
from abc import abstractmethod,ABCMeta
class Swim_Animal(metaclass=ABCMeta):
@abstractmethod
def swim(self):pass
class Walk_Animal(metaclass=ABCMeta):
@abstractmethod
def walk(self):pass
class Fly_Animal(metaclass=ABCMeta):
@abstractmethod
def fly(self):pass
class Tiger(Walk_Animal,Swim_Animal):
def walk(self):
pass
def swim(self):
pass
class OldYing(Fly_Animal,Walk_Animal):pass
class Swan(Swim_Animal,Walk_Animal,Fly_Animal):pass
#对于操作系统来说一切皆文件
import abc #利用abc模块实现抽象类
class All_file(metaclass=abc.ABCMeta):
all_type='file'
@abc.abstractmethod #定义抽象方法,无需实现功能
def read(self):
'子类必须定义读功能'
with open('filaname') as f: # 简单的基础的方法
pass
@abc.abstractmethod #定义抽象方法,无需实现功能
def write(self):
'子类必须定义写功能'
pass
class Txt(All_file): #子类继承抽象类,但是必须定义read和write方法
def read(self):
print('文本数据的读取方法')
def write(self):
print('文本数据的读取方法')
class Sata(All_file): #子类继承抽象类,但是必须定义read和write方法
def read(self):
print('硬盘数据的读取方法')
def write(self):
print('硬盘数据的读取方法')
class Process(All_file): #子类继承抽象类,但是必须定义read和write方法
def read(self):
print('进程数据的读取方法')
def write(self):
print('进程数据的读取方法')
wenbenwenjian=Txt()
yingpanwenjian=Sata()
jinchengwenjian=Process()
#这样大家都是被归一化了,也就是一切皆文件的思想
wenbenwenjian.read()
yingpanwenjian.write()
jinchengwenjian.read()
print(wenbenwenjian.all_type)
print(yingpanwenjian.all_type)
print(jinchengwenjian.all_type)
抽象类 : 规范
一般情况下 单继承 能实现的功能都是一样的,所以在父类中可以有一些简单的基础实现
多继承的情况 由于功能比较复杂,所以不容易抽象出相同的功能的具体实现写在父类中
抽象类还是接口类 : 面向对象的开发规范 所有的接口类和抽象类都不能实例化
java :
java里的所有类的继承都是单继承,所以抽象类完美的解决了单继承需求中的规范问题
但对于多继承的需求,由于java本身语法的不支持,所以创建了接口Interface这个概念来解决多继承的规范问题
python:
python中没有接口类 :
python中自带多继承 所以我们直接用class来实现了接口类
python中支持抽象类 : 一般情况下 单继承 不能实例化
且可以实现python代码
多态:
在不考虑实例类型的情况下使用实例;比如在python中可以同时接收多种的数据类型;因此python是天生多态.
python 属于动态强类型的语言,弱类型语言表现在在传入参数的时候不用写数据的类型;而强类型语言表现在str不能和int相加;因此属于动态的;有强有弱。
鸭子类型:在python中,如果两个类刚好相似,并不产生父类的子类的兄弟关系,而不是通过接口类和抽象类来规范保证相似的,这种属于鸭子类型。
比如list和tuple这种相似,是自己写代码的时候约束的,而不是通过父类约束的
鸭子类型的优点:松耦合 每个相似的类之间都没有影响,可以方便修改,而不影响其他的代码。
缺点:太随意了,只能靠自觉
class List():
def __len__(self):pass
class Tuple():
def __len__(self):pass
def len(obj):
return obj.__len__()
l = Tuple()
len(l)
封装:
隐藏对象的属性和实现细节
优点:
1. 将变化隔离;
2. 便于使用;
3. 提高复用性;
4. 提高安全性;
封装原则:
1. 将不需要对外提供的内容都隐藏起来;
2. 把属性都隐藏,提供公共方法对其访问。
封装 —— 变成私有的
在python中只要__(双下划线)名字,就把这个名字私有化了
私有化了之后 就不能能从类的外部直接调用了
静态属性 方法 对象属性 都可以私有化
这种私有化只是从代码级别做了变形,并没有真的约束
变形机制 _类名__名字
#其实这仅仅这是一种变形操作 #类中所有双下划线开头的名称如__x都会自动变形成:_类名__x的形式: class A: __N=0 #静态属性 #类的数据属性就应该是共享的,但是语法上是可以把类的数据属性设置成私有的如__N,会变形为_A__N def __init__(self): self.__X=10 #变形为self._A__X #对象属性 def __foo(self): #变形为_A__foo #方法 print('from A') def bar(self): self.__foo() #只有在类内部才可以通过__foo的形式访问到. #在外边可以通过A._A__N是可以访问到的,即这种操作并不是严格意义上的限制外部访问,仅仅只是一种语法意义上的变形
在类外用这个调用,在类的内部直接__名字调用
class Room:
__key = 3
def __init__(self,name,length,width):
self.__name = name
self.__length = length
self.__width = width
def __area(self):
return self.__length * self.__width
room = Room('alex',100,200)
# print(Room._Room__key) #3
# print(Room._Room__area(room)) #20000
# print(room._Room__area()) #20000
注意:父类的私有属性 不能被 子类调用。
# class Foo:
# __key = '123' # _Foo__key
#
# class Son(Foo):
# print(Foo.__key) # _Son__key
#报错
在父类Foo中的__key本质是 _Foo__key;而在子类中,类发生了变化,因此变成了_Son__key,所以找不到这个值了。
会用到私有的即封装这个概念的场景有:
1.隐藏起一个属性 不想让类的外部调用
2.我想保护这个属性,不想让属性随意被改变
3.我想保护这个属性,不被子类继承
property
内置装饰器函数 只在面向对象中使用;把函数名()变成了对象的属性名
from math import pi
class Circle:
def __init__(self,r):
self.r = r
#@property # 加上@property 以后在调用这个函数的时候就可以像直接调用属性一样;
def perimeter(self):
return 2*pi*self.r
@property #把函数名()变成了属性名
def area(self):
return self.r**2*pi
c1 = Circle(5)
print(c1.area) # 圆的面积#area变成了属性名了
print(c1.perimeter()) # 圆的周长
# 对象属性 查看 修改 删除
class Person:
def __init__(self,name):
self.__name = name #__属性 对这个属性私有化,在外部查看不了
@property #方法名变成属性;查看
def name(self):
return self.__name
@name.deleter #删除属性
def name(self):
print('123')
del self.__name
@name.setter #修改属性
def name(self,new_name): #后面只能传一个参数,参数为 == 后面的参数
self.__name = new_name
alex = Person('alex')
print(alex.name) #查看
alex.name = '6666' #修改
print(alex.name)
del alex.name #这里的del 触发了 @name.deleter 装饰的方法,装饰的函数里面进行删除属性
# print(alex.name)
classmethod 类方法 中有默认的参数cls(传入的类)
当这个方法的操作只涉及静态属性的时候 就应该使用classmethod来装饰这个方法
# 类的操作行为
# class Goods:
# __discount = 0.8 # 静态的属性
# def __init__(self,name,price):
# self.name = name
# self.__price = price
# @property
# def price(self):
# return self.__price * Goods.__discount
# @classmethod # 把一个方法 变成一个类中的方法,这个方法就直接可以被类调用,不需要依托任何对象
# def change_discount(cls,new_discount): # 修改折扣 ;默认参数cls 为传入的类 class,自动的帮你传入的
# cls.__discount = new_discount
# print(apple.price)
# Goods.change_discount(0.5) # Goods.change_discount(Goods)
# print(apple.price)
staticmethod 静态的方法
在完全面向对象的程序中,
如果一个函数 既和对象没有关系 也和类没有关系 那么就用staticmethod将这个函数变成一个静态方法,
静态方法就是没有默认的参数 就象普通的函数一样
class Login:
def __init__(self,name,password):
self.name = name
self.pwd = password
def login(self):pass
@staticmethod
def get_usr_pwd(): # 静态方法
usr = input('用户名 :')
pwd = input('密码 :')
Login(usr,pwd)
Login.get_usr_pwd()
类方法和静态方法 都是类调用的,对象可以调用类方法和静态方法,只是一般情况下 推荐用类名调用
面向对象的进阶
1.isinstance和issubclass
isinstance(obj,cls)检查是否obj是否是类 cls 的对象
class Foo(object):
pass
obj = Foo()
isinstance(obj, Foo)
issubclass(sub, super)检查sub类是否是 super 类(父类)的派生类
class Foo(object):
pass
class Bar(Foo):
pass
issubclass(Bar, Foo)
2.反射
反射 : 是用字符串类型的名字 去操作 变量;而python一切皆为对象,都可以用反射。
eval也可以实现字符串类型的python代码,只不过有安全的隐患;而反射就没有安全问题
# name = 1
# eval('print(name)') # 安全隐患
反射有4个方法:getattr(查看);hasattr(检查是否有);serattr(修改);delattr(删除); getattr 一般与hasattr一起使用,先检测是否有,然后再查看;
反射对象的属性和方法;
class A:
def __init__(self,name):
self.name = name
def func(self):
print('123')
a = A('a')
n = a.name
a.func()
#反射对象的属性
ret = getattr(a,'name')
print(ret)
#反射对象的方法
ret = getattr(a,'func')
print(ret) #<bound method A.func of <__main__.A object at 0x000000000296C748>> 函数的内存地址
ret()
反射类的静态属性和方法:
class A:
key = '666'
def __init__(self,name):
self.name = name
@classmethod #类方法
def func(self):
print('123')
# 反射类的静态属性
m = A.key
ret = getattr(A,'key')
print(ret)
# 反射类的方法
A.func()
ret = getattr(A,'func')
print(ret) #<bound method A.func of <class '__main__.A'>>
ret()
反射自己的模块和模块里面的方法 ,用sys.modules来获得当前本文件的所有模块,返回的是一个字典。
import sys
year = 2018
def func():
print('6666')
if hasattr(sys.modules[__name__],'year'): # 用来判断 在前面这个模块里是否有year这个变量;防止getattr直接报错
print(getattr(sys.modules[__name__],'year')) #getattr 与hasattr括号里面的内容应该保持一致
print(sys.modules['__main__']) #sys.modules是一个字典
# 在本文件中执行,__name__ =='__main__'; __name__是一个变量
ret = getattr(sys.modules['__main__'],'year')
print(ret)
# 如果在另外的一个文件中执行的话 __name__ == 模块名了
ret = getattr(sys.modules[__name__],'year')
print(ret)
func_name = getattr(sys.modules[__name__],'func' #函数名
func_name()
内置的模块也可以反射
# 内置模块也能用
# time
# asctime
# import time
# print(getattr(time,'time')())
# print(getattr(time,'asctime')())
如果要反射的函数有参数的话,则把参数写到括号里
#print(time.strftime('%Y-%m-%d %H:%M:S'))
print(getattr(time,'strftime')('%Y-%m-%d %H:%M:S'))
模块中的类也能用反射得到
#my的模块里面的内容
class C: def __init__(self,name): self.name = name @classmethod def name1(self): print('666')
# 一个模块中的类能反射得到
import my
a = getattr(my,'C') # 反射得到类
print(a)
ne = getattr(my,'C')('alex') #实例化一个对象
print(ne)
print(getattr(my.C,'name1')) #调用类的方法
因此只要是 什么.什么都能用反射来实现 ---> getattr(什么,'什么')
getattr 与hasattr是一起的;hasattr是用来判断的;
setattr 和delattr (不是很常用)
# setattr 设置修改变量
class A:
pass
a = A()
setattr(a,'name','nezha')
setattr(A,'name','alex')
print(A.name)
print(a.name)
# delattr 删除一个变量
delattr(a,'name') #删除的是对象中的name,
print(a.name) #对象中没有name变量,则就要类中去寻找。得到类的name变量
delattr(A,'name') #删除的是类中的name,
print(a.name) #类中也没有了就报错了
3.__str__和__rep__; __del__
内置的类方法 和 内置的函数之间有着千丝万缕的联系双下方法
obj.__str__ ——————> str(obj)
obj.__repr__ ——————> repr(obj)
如果该对象的类中没有__str__或者__repr__的方法就找父类,若没有继承,则父类为object,
object 里有一个__str__,一旦被调用,就返回调用这个方法的对象的内存地址;
object 里有一个__repr__,一旦被调用,也返回调用这个方法的对象的内存地址;
class Teacher:
def __init__(self,name,salary):
self.name = name
self.salary = salary
def func(self):
return 'wahaha'
nezha = Teacher('哪吒',250)
print(nezha) # 打印一个对象的时候,就是调用obj.__str__
print('%s'%nezha) #'%s'%obj,调用obj.__str__
print(str(nezha)) #str(obj),调用obj.__str__
#<__main__.Teacher object at 0x000000000045D160>
print(repr(nezha)) #repr(obj),调用obj.__repr__
print('>>> %r'%nezha) #'%r'%obj,调用obj.__repr__
#<__main__.Teacher object at 0x000000000045D160>
如果对象的类中有__str__和__repr__方法就用自己的;
print(obj) / ' %s '% obj / str(obj) 的时候,实际上是内部调用了obj.__str__方法,如果str方法有,那么他返回的必定是一个字符串
如果没有__str__方法,会先找本类中的__repr__方法,再没有再找父类中的__repr__ 或者 __str__方法。
所以 __repr__ 是__str__的备胎;但是__str__不能作为__repr__的备胎。
repr(),只会找__repr__,如果没有 找父类的
class Teacher:
def __init__(self,name,salary):
self.name = name
self.salary = salary
def __str__(self):
return "Teacher's object :%s"%self.name
def __repr__(self):
return str(self.__dict__)
def func(self):
return 'wahaha'
nezha = Teacher('哪吒',250)
print(nezha) # 打印一个对象的时候,就是调用obj.__str__
print('%s'%nezha) #'%s'%obj,调用obj.__str__
print(str(nezha)) #str(obj),调用obj.__str__
print(repr(nezha)) #repr(obj),调用obj.__repr__
print('>>> %r'%nezha) #'%r'%obj,调用obj.__repr__
#没有__str__,结果全为{'name': '哪吒', 'salary': 250},相当于执行了__repr__
#有__str__,结果为Teacher's object :哪吒;{'name': '哪吒', 'salary': 250}
内置的方法有很多,不一定全都在object中,比如__len__
class Classes:
def __init__(self,name):
self.name = name
self.student = []
def __len__(self):
return len(self.student)
def __str__(self):
return 'classes'
py_s9= Classes('python全栈9期')
py_s9.student.append('二哥')
py_s9.student.append('泰哥')
print(len(py_s9)) #len() 调用内部的__len__
print(py_s9)
4.item系列
item系列中有__getitem__;__setitem__;__delitem__.
class Foo:
def __init__(self,name,age,sex):
self.name = name
self.age = age
self.sex = sex
def __getitem__(self, item):
if hasattr(self,item):
return self.__dict__[item] #self.__dict__返回的是对象的所有的属性,是一个字典
def __setitem__(self, key, value):
self.__dict__[key] = value
def __delitem__(self, key):
print('666')
# del self.__dict__[key]
f = Foo('egon',38,'男')
print(f['name']) #__getitem__,就可以像字典或者列表一样的取值了,dic[k];list[0]
f['hobby'] = '男' #__setitem__,就可以像字典或者列表一样的修改值了,dic[k]=v;list[0]=v
print(f.hobby,f['hobby'])
del f.hobby # object 原生支持 __delattr__
del f['hobby'] # 通过__delitem__函数里面的代码实现;相当于 del 就执行了__delitem__函数.
#'666'
print(f.__dict__)
5.__new__;__call__;__len__;__hash__;__eq__
# __init__ 初始化方法
# __new__ 构造方法 : 创建一个对象
#实例化一个类的时候,在__init__ 之前先执行__new__,创建了一个self对象
class A:
def __init__(self):
self.x = 1
print('in init function')
def __new__(cls, *args, **kwargs): #__new__中有一个参数为cls 为类,自动的传入
print('in new function')
return object.__new__(A, *args, **kwargs) #返回一个对象
a1 = A()
print(a1)
print(a1.x)
# in new function
# in init function
# <__main__.A object at 0x0000000009E87390>
# 1
# 单例模式
# 一个类 始终 只有 一个 实例
# 当你第一次实例化这个类的时候 就创建一个实例化的对象
# 当你之后再来实例化的时候 就用之前创建的对象
#共用一个对象
class A:
__instance = False
def __init__(self,name,age):
self.name = name
self.age = age
def __new__(cls, *args, **kwargs):
if cls.__instance: #类的对象 ---> T
return cls.__instance
cls.__instance = object.__new__(cls)
#print(cls.__instance) #类的对象
return cls.__instance
egon = A('egg',38)
egon.cloth = '小花袄'
nezha = A('nazha',25)
#相当于总是 共用 一个对象 ,只不 给对象的属性每次旧的属性都覆盖掉了,没有覆盖的就可以继续使用。
print(nezha)
print(egon)
# <__main__.A object at 0x0000000009F612E8>
# <__main__.A object at 0x0000000009F612E8>
print(nezha.name)
print(egon.name)
#nazha
# nazha
print(nezha.cloth)
#小花袄
PYC文件:
在硬盘上看到的pyc文件,其实PyCodeObject才是Python编译器真正编译成的结果。当python程序运行时,编译的结果是保存在位于内存中的PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复上面的过程。所以,我们可以说pyc文件其实是PyCodeObject的一种持久化保存方式。
单例对象
# mysingleton.py
class My_Singleton(object):
def foo(self):
print("foo.....")
my_singleton = My_Singleton()
#func.py
from mysingleton import my_singleton
def bar():
print(id(my_singleton))
# 单例模式方式2 :模块方式 import ;导入一次模块后,就会执行模块里面的所有的内容;
# 然后把内容放在pyc内存中,下一次导入的时候,直接取就行了;因此对于python来说,导入多少次的模块就只会执行一次;
# 所以说导入模块里面的对象的时候就会从pyc里面直接取,这样取的对象始终是一个,因此是单例的对象; # from mysingleton import my_singleton,My_Singleton # my_singleton.foo() # # print(id(my_singleton)) # 思考1 # from mysingleton import my_singleton as my_singleton_new # # print(id(my_singleton_new)) # print(id(my_singleton)) # 思考2 # import func # # func.bar()
#__call__
# class Foo:
#
# def __init__(self):
# pass
#
# def __call__(self, *args, **kwargs):
# print('__call__')
#
#
# obj = Foo() # 执行 __init__
# obj()#执行是对象的类的__call__的方法
len() 就调用了 __len__
# hash() #__hash__ 默认返回的是hash值(通过内容计算得到的)
# class A:
# def __init__(self,name,sex):
# self.name = name
# self.sex = sex
# def __hash__(self):
# return hash(self.name+self.sex) #按照名字和性别来计算hash值
#
# a = A('egon','男')
# b = A('egon','nv')
# print(hash(a))
# print(hash(b))
# obj == obj ————> __eq__
class A:
def __init__(self,name):
self.name = name
def __eq__(self,obj): #__eq__判断两个对象是否相等;默认是判断内存地址;
#print(self,obj) #<__main__.A object at 0x000000000295C710> <__main__.A object at 0x000000000295C7B8>
if self.name == obj.name: #判断两个对象的名字是否相等
return True
else:
return False
b = A('alex')
a = A('alex')
print(a==b)
6.hashlib 模块
python的hashlib模块提供了常见的摘要算法,比如md5,sha1等等。
摘要算法又叫做哈希算法,通过函数,把任意长度的数据转换为一个长度固定的数据串(通常用十六进制的字符串表示),通常叫做加密。摘要算法是一个单向的函数,加密容易,解密难。
摘要算法运用的场景:
1.密码的密文存储;密码用md5变成密文保存到文件中。防止密码的丢失;安全
2.文件的一致性验证
import hashlib # 提供摘要算法的模块
md5 = hashlib.md5() #实例化一个对象md5
md5.update(b'123456') #输入的数据类型为bytes类型的
print(md5.hexdigest()) #md5.hexdigest()来获得加密后的数据,
#aee949757a2e698417463d47acac93df(十六进制的)
如果你要加密的数据的数量比较多的话,可以分块多次调用update(),最后结果和一次调用是一样的
#验证文件的一致性,可以分开的加密,最后结果和一起加密是一样的
# import hashlib
#
# md5 = hashlib.md5()
#
# with open('userinfo')as f:
# while True:
# ret = f.read(9)
# md5.update(bytes(ret,encoding='utf-8'))
# if not ret:
# break
#
# print(md5.hexdigest())
加盐:对原始口令加一个复杂的字符串来实现
hashlib.md5("salt".encode("utf8")) # salt 可改变为任意的
更加复杂的加密为 动态加盐;
动态加盐一般指的是 使用用户名的一部分 或者 直接使用整个用户名 作为盐
# md5 = hashlib.md5(bytes('salt',encoding='utf-8')+b'用户名的一部分')
configparser模块
用configparser模块来配置文件的时候;
文件是有一定的格式的:
# [DEFAULT]
# ServerAliveInterval = 45
# Compression = yes
# CompressionLevel = 9
# ForwardX11 = yes
#
# [bitbucket.org] 节(Section)
# User = hg
#
# [topsecret.server.com]
# Port = 50022
# ForwardX11 = no
configparser模块来生成文件
# configparse
# import configparser
# config = configparser.ConfigParser() #对象
# config["DEFAULT"] = {'ServerAliveInterval': '45',
# 'Compression': 'yes',
# 'CompressionLevel': '9',
# 'ForwardX11':'yes'
# }
# config['bitbucket.org'] = {'User':'hg'}
#
# config['topsecret.server.com'] = {'Host Port':'50022','ForwardX11':'no'}
#
# with open('example.ini', 'w') as f:
# config.write(f)
查找文件里面的内容:
#只要有[DEFAULT]这个字节的时候,打印出键或者是键值对的时候,都会默认出现default的键.
import configparser
config = configparser.ConfigParser()
# ---------------------------查找文件内容,基于字典的形式
print(config.sections()) # []
config.read('example.ini')
print(config.sections()) # ['bitbucket.org', 'topsecret.server.com']
print('bytebong.com' in config) # False
print('bitbucket.org' in config) # True
print(config['bitbucket.org']["user"]) # hg
print(config['DEFAULT']['Compression']) #yes
print(config['topsecret.server.com']['ForwardX11']) #no
print(config['bitbucket.org']) #<Section: bitbucket.org> #节的名字
for key in config['bitbucket.org']: # 注意,有default的节的时候,除了打印出['bitbucket.org']这个字节的k
# 也会默认出现default的键
print(key)
# user
# serveraliveinterval
# compression
# compressionlevel
# forwardx11
print(config.options('bitbucket.org')) # 同for循环,找到'bitbucket.org'下所有键,同时也会默认出现default的键
print(config.items('bitbucket.org')) #找到'bitbucket.org'下所有键值对
print(config.get('bitbucket.org','serveraliveinterval')) # 45 get方法 Section下的key对应的 value
增或者是删配置文件里面的内容:
# import configparser
# config = configparser.ConfigParser()
# config.read('example.ini') # 读文件
# config.add_section('yuan') # 增加section
# config.remove_section('bitbucket.org') # 删除一个section
# config.remove_option('topsecret.server.com',"forwardx11") # 删除一个配置项
# config.set('topsecret.server.com','k1','11111')
# config.set('yuan','k2','22222')
# f = open('new2.ini', "w")
# config.write(f) # 写进文件
# f.close()
logging模块,用来记录日志
日志 :用来记录用户行为 或者 代码的执行过程。
logging
有5种级别的日志记录模式 :
logging.debug('debug message') # 低级别的 # 排错信息
logging.info('info message') # 正常信息
logging.warning('警告错误') # 警告信息
logging.error('error message') # 错误信息
logging.critical('critical message') # 高级别的 # 严重错误信息
两种配置方式:basicconfig 、log对象
# basicconfig 简单 能做的事情相对少
# 中文的乱码问题
# 不能同时往文件和屏幕上输出
log对象的优点
# 程序的充分解耦
# 让程序变得高可定制
# 配置log对象 稍微有点复杂 能做的事情相对多 ,很灵活
import logging
logger = logging.getLogger() #对象
fh = logging.FileHandler('log.log',encoding='utf-8') #创建一个文件控制对象
sh = logging.StreamHandler() # 创建一个屏幕控制对象
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
formatter2 = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s [line:%(lineno)d] : %(message)s')
logger.setLevel(logging.DEBUG) #设置输出日志记录模式
# 文件操作符 和 格式 关联
fh.setFormatter(formatter)
#屏幕操作符和 格式 关联
sh.setFormatter(formatter2)
# logger 对象 和 文件操作符 关联
logger.addHandler(fh)
#logger 对象 和 屏幕操作符 关联
logger.addHandler(sh)
logging.debug('debug message') # 低级别的 # 排错信息
logging.info('info message') # 正常信息
logging.warning('警告错误') # 警告信息
logging.error('error message') # 错误信息
logging.critical('critical message') # 高级别的 # 严重错误信息
配置的参数:
logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有:
filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open(‘test.log’,’w’)),
默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。
format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s用户输出的消息