http://geek.rohitkalhans.com/2013/09/enhancedMTS-deepdive.html 科学上网
Introduction
Re-applying binary logs generated from highly concurrent master on the slave has always been an area of focus. It is important for various reasons. First, in real-time systems, it becomes extremely important for the slave to keep up with the master. This can only be guaranteed if the slaves’ performance in reapplying the transactions from the binary log is similar (or at-least comparable) to that of master, which is accepting queries directly from multiple clients. Second, in synchronous replication scenarios, having a fast slaves, aids in reducing the response times as seen by the clients to the master. This can be made possible by applying transactions from the binary log in parallel. However if left uncontrolled, a simple round-robin multi-threaded applying will lead to inconsistency and the slave will no longer be the exact replica of the leader.
The infamous out of order commit problem
The Out of order execution of transaction on the slave if left uncontrolled will lead to the slave diverging from the master. Here is an example: consider two transactions T1 and T2 being applied on an initial state.
On Master we apply T1 and T2 in that order.
State0: x= 1, y= 1
T1: { x:= Read(y);
x:= x+1;
Write(x);
Commit; }
State1: x= 2, y= 1
T2: { y:= Read(x);
y:=y+1;
Write(y);
Commit; }
State2: x= 2, y= 3
|
On the slave however these two transactions commit out of order (Say T2 and then T1).
State0: x= 1, y= 1
T2: { y:= Read(x);
y:= y+1;
Write(y);
Commit; }
State1: x= 1, y= 2
T1: { x:= Read(y);
x:=x+1;
Write(x);
Commit; }
State2: x= 3, y= 2
|
As we see above the final state state 2 is different in the two cases. Needless to say that we need to control the transactions that can execute in parallel.
Controlled parallelization
The above problem can be solved by controlling what transactions can be executed in parallel with the ones being executed by the slave. This means we need to have some kind of information in the transactions themselves. Interesting to note that we can use the information of parallelization from the master on the slave. Since we have multiple transactions committing at the same time on the master, we can store the information of the transactions that were in the "process of committing" when this transaction committed. Now let's define the phrase "process of committing".
Logical clock and commit parent
We have introduced a logical clock. Now before I am tackled by a mathematician from one side and a computer engineer from the other, let me explain. It is a simple counter which is stepped when a binlog group of transaction commits on the master. Essentially this clock is stepped every time the leader execute the flush stage of binlog group commit. The value of this clock is recorded on each transaction when it enters the prepare stage. This recorded value is the "commit parent"
During Prepare
trx.commit_parent= commit_clock.get_timestamp();
During Commit
for every binlog group
commit_clock.step();
As it is evident by now the transactions with the same commit parent follow our guiding principle of slave side parallelization i.e. transactions that have entered the prepared stage but has not as yet committed, and hence can be executed in parallel.
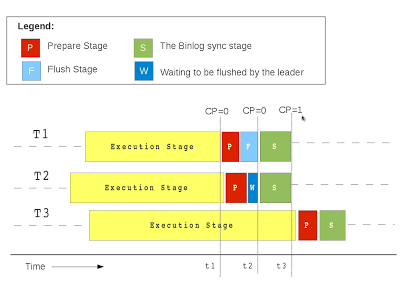
In the example we will take up three transactions (T1 T2 T3), two of which have been committed as a part of the same binlog group. T1 enters the prepare stage and get the commit parent as 0 since none of the group have been committed as yet. T1 assigns itself as the leader and then goes on to flush its transaction/statement cache. In the meanwhile transaction T2 enters the prepare stage. It is also assigned the same commit parent "0"(CP as used in the figure) since the commit clock has not as yet been stepped. T2 then goes on a wait for the leader to flush its cache in to the binlog. After the flush has been completed by the leader, it signals T2 to continue and both of them enter the Sync stage, where the leader thread calls fsync() there by finishing the binlog commit process. The transaction T3 however enters the prepare stage after the previous group has been synced and there-by ends up getting the next CP.
Another thing to note here is that the "group" of transactions that are being executed in parallel are not bounded by binlog commit group. There is a possibility that a transaction have entered the binlog prepare stage but could not make it to the current binlog group. Our approach takes care of such cases and makes sure that we relax the boundary of the group being executed in parallel on the slave.
Another thing to note here is that the "group" of transactions that are being executed in parallel are not bounded by binlog commit group. There is a possibility that a transaction have entered the binlog prepare stage but could not make it to the current binlog group. Our approach takes care of such cases and makes sure that we relax the boundary of the group being executed in parallel on the slave.
On the slave we use the existing infrastructure of DB partitioned MTS to execute the tranactions in parallel, simply by modifying the scheduling logic.
Conclusion
This feature provides the great enhancement to the existing MySQL replication. To know more about the configuration options of this enhancement refer to this post.This feature is available in MySQL 5.7.2 release. You can try it out and let us know the feedback.
About the author
