对于大批量的更新操作 又涉及同步,如果可以:
a) 最好是使用最小粒度的维护,可以减少每次维护的工作量,也减少备份 (建立作业JOB批量操作,定期进行删除)
b) 如果是急需,又涉及到同步,那么可以把同步拿掉进行删除,完成之后再建上(避免出现线上阻塞,影响性能。同步会同步大量日志,更新完成之后再重建同步使用的不是日志同步而是快照,所以速度要比用日志同步快很多。)
监控:可以用 sp_who2 或者 可以通过查询 sysprocess 获取是否有阻塞,在更新的同时,查看同步的监控通常是看SqlMonitor,以便于对当前的情况进行随时的调整。
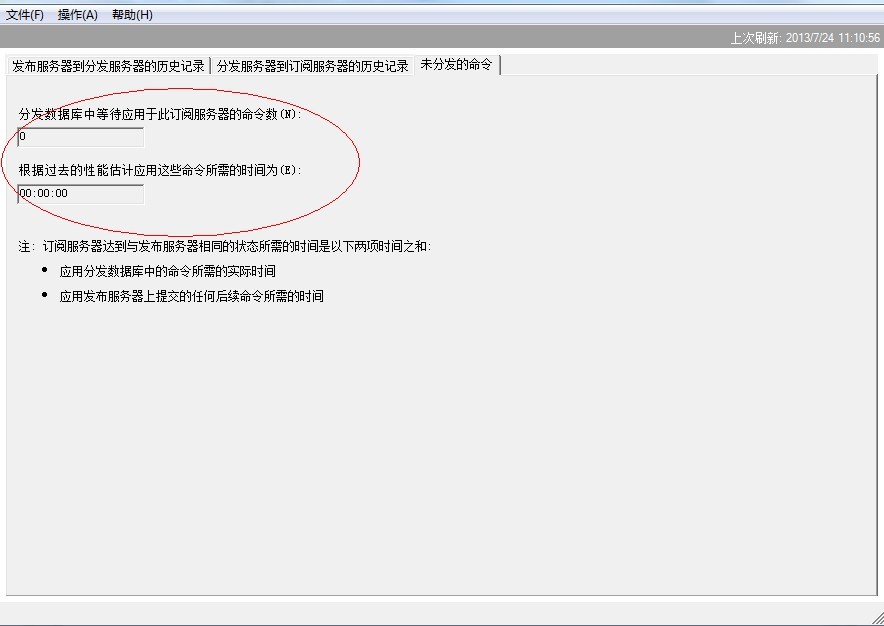
1. 我们可以通过以下查询看到目前有多少的命令没有分发出去,如果数据量特别大,可以稍等,分发相对少一些的时候再来进行操作。
USE distribution GO SELECT COUNT(*) FROM dbo.MSrepl_commands WITH(NOLOCK)
或者就是复制监视器中的未分发命令来进行查看
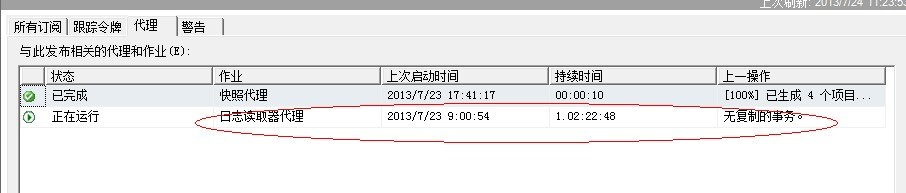
2. 如果 Logreader的日志显示当前正在进行大量数据的读取,那么表示之前有大量的数据变更,如果我们正在执行分批更新的话,那么应该先停止,这通常表明我们的分批可能不太合理,导致日志读取器一直在读取事务
SQLMonitor 会对服务器造成比较大的影响。
以下脚本可以查看当时库有多少同步,如果知道表,可以直接查询这个表同步到什么地方,同步到了几处。
USE TEST GO SELECT sct .dest_db ,srt. dest_owner , srt. name , sct. srvname, pub.pubid , srt .dest_table --,srt.artid ,sct.artid FROM syspublications as pub WITH (NOLOCK) inner join sysarticles as srt WITH( NOLOCK) on pub .pubid = srt .pubid inner join syssubscriptions sct with (nolock) on srt.artid = sct.artid GROUP BY sct. srvname , pub. pubid , srt.dest_owner , srt.name , srt.dest_table ,sct .dest_db