在分析hashmap高并发场景之前,我们要先搞清楚ReHash这个概念。ReHash是HashMap在扩容时的一个步骤。
HashMap的容量是有限的。当经过多次元素插入,使得HashMap达到一定饱和度时,Key映射位置发生冲突的几率会逐渐提高。这时候,HashMap需要扩展它的长度,也就是进行Resize。
影响发生Resize的因素有两个:
1.Capacity:HashMap的当前长度。上一篇曾经说过,HashMap的长度是2的幂。
2.LoadFactor:HashMap负载因子,默认值为0.75f。
衡量HashMap是否进行Resize的条件如下:
HashMap.Size >= Capacity * LoadFactor
Resize的两个步骤:
1.扩容
创建一个新的Entry空数组,长度是原数组的2倍。
2.ReHash
遍历原Entry数组,把所有的Entry重新Hash到新数组。为什么要重新Hash呢?因为长度扩大以后,Hash的规则也随之改变。
让我们回顾一下Hash公式:
index = HashCode(Key) & (Length - 1)
当原数组长度为8时,Hash运算是和111B做与运算;新数组长度为16,Hash运算是和1111B做与运算。Hash结果显然不同。
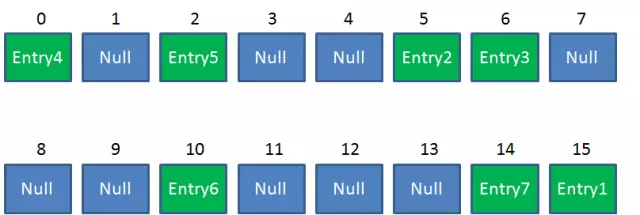
Resize前的HashMap:

Resize后的HashMap:
ReHash的Java代码如下:
1 /** 2 * Transfers all entries from current table to newTable. 3 */ 4 void transfer(Entry[] newTable, boolean rehash) { 5 int newCapacity = newTable.length; 6 for (Entry<K,V> e : table) { 7 while(null != e) { 8 Entry<K,V> next = e.next; 9 if (rehash) { 10 e.hash = null == e.key ? 0 : hash(e.key); 11 } 12 int i = indexFor(e.hash, newCapacity); 13 e.next = newTable[i]; 14 newTable[i] = e; 15 e = next; 16 } 17 } 18 }
上述流程在单线程下执行是没有问题的,但在多线程下,HashMap并非线程安全的。下面在演示在多线程环境下,HashMap的ReHash操作可能带来什么样的问题之前,先说明在单线程下的执行情况。
在说明之前,先将ReHash的代码分为如下三部分:

(一)、单线程的情况下:
假设一个HashMap已经到了Resize的临界点:
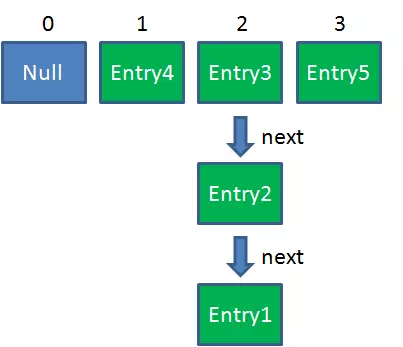
1. 扩容

2. ReHash
首先遍历Entry4对象:e = Entry4 第8行:next = e.next; => next = null; //此时:e = Entry4, next = null 第12行:假设i = 1; 第13-15行:e.next = newTable[1]; => e.next = null; newTable[1] = e; => newTable[1] = Entry4; e = next; => e = null; //此时:e = null, next = null Entry4放入newTable[1]的位置,结束while循环。开始遍历下一个对象:e = Entry3 第8行:next = e.next; => next = Entry2; //此时:e = Entry3, next = Entry2 第12行:假设i = 3; 第13-15行:e.next = newTable[3]; => e.next = null; //要插入的结点的next指向newTable[i] newTable[3] = e; => newTable[3] = Entry3; //要插入的结点放在newTable[i]处 e = next; => e = Entry2; //此时:e = Entry2, next = Entry2 Entry3放入newTable[3]的位置,继续while循环,开始遍历下一个对象:e = Entry2 第8行:next = e.next; => next = Entry1; //此时:e = Entry2, next = Entry1 第12行:假设i = 3; 第13-15行:e.next = newTable[3]; => e.next = Entry3; newTable[3] = e; => newTable[3] = Entry2; e = next; => e = Entry1; //此时:e = Entry1, next = Entry1 Entry2放入newTable[3]的位置,且Entry2.next = Entry3,继续while循环,开始遍历下一个对象:e = Entry1 .....
(二)、多线程的情况下:
1. 假设一个HashMap已经到了Resize的临界点:
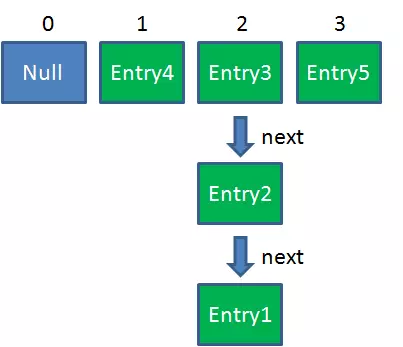
2. 此时有两个线程A和B,在同一时刻对HashMap进行Put操作:
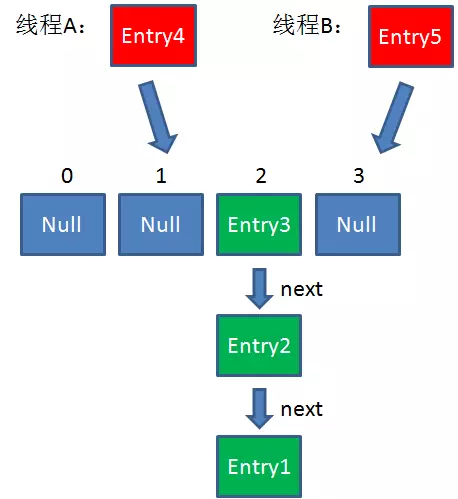
3. 此时达到Resize条件,两个线程各自进行Rezie的第一步,也就是扩容:
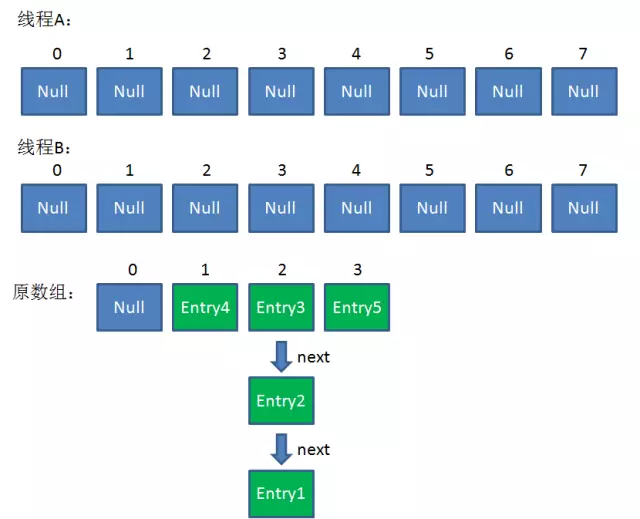
4. 这时候,两个线程都走到了ReHash的步骤。
假如此时线程B遍历到Entry3对象,刚执行完第8行代码,线程就被挂起。对于线程B来说:
e = Entry3
next = Entry2
这时候线程A畅通无阻地进行着Rehash,当ReHash完成后,结果如下(图中的e和next,代表线程B的两个引用):
直到这一步,看起来没什么毛病。
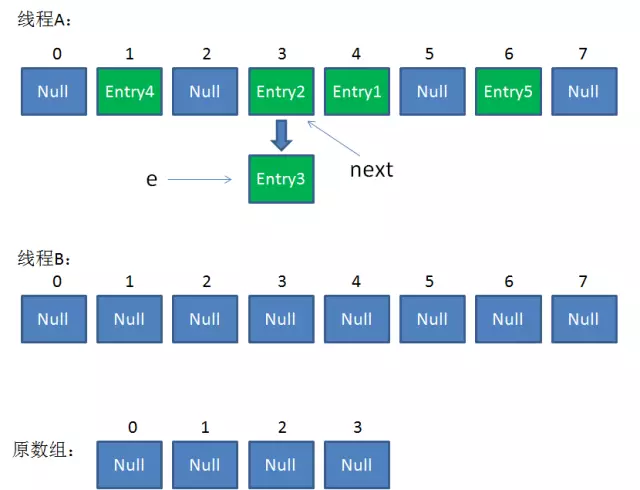
5. 接下来线程B恢复,继续执行属于它自己的ReHash。(e = Entry3, next = Entry2)
//线程B继续执行 第12行:i = 3 //因为刚才线程A对于Entry3的hash结果也是3 第13-15行:e.next = newTable[3]; => e.next = null; newTable[3] = e; => newTable[3] = Entry3; e = next; => e = Entry2; //此时:e = Entry2, next = Entry2 Entry3放入线程B中newTable[3]的位置,继续while循环,开始遍历下一个对象:e = Entry2
整体情况如下:(线程A中e和next都指向Entry2,线程B只有Entry3)
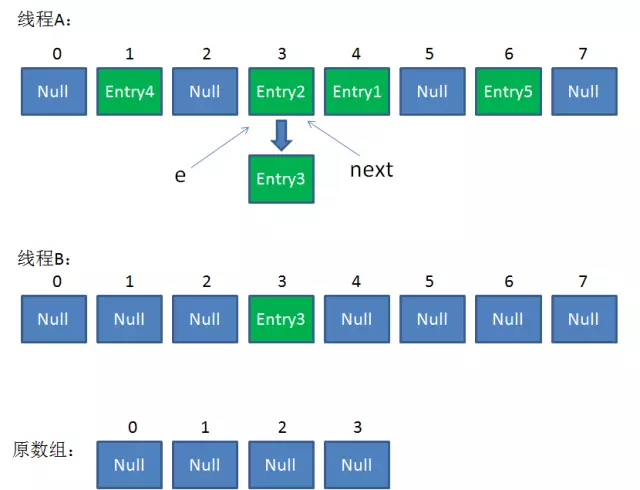
6. 继续执行:
//继续while循环 第8行:next = e.next; => next = Entry3; //此时:e = Entry2, next = Entry3 第12行:i = 3; 第13-15行:e.next = newTable[3]; => e.next = Entry3; newTable[3] = e; => newTable[3] = Entry2; e = next; => e = Entry3; //此时:e = Entry3, next = Entry3 Entry2放入newTable[3]的位置,且Entry2.next = Entry3,继续while循环,开始遍历下一个对象:e = Entry3
整体情况如下:(线程A中e和next都指向Entry3,线程B有Entry2和Entry3)
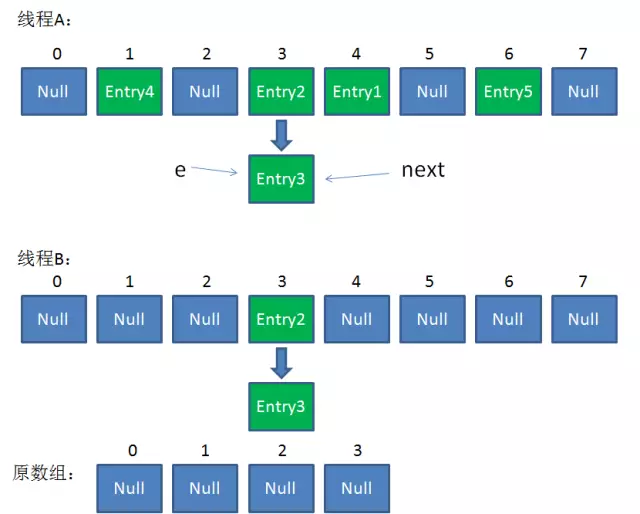
7. 继续执行:
//继续while循环 第8行:next = e.next; => next = null; //此时:e = Entry3, next = null 第9行:i = 3; 第13-15行:e.next = newTable[i]; => e.next = Entry2; newTable[3] = e; => newTable[3] = Entry3; e = next; => e = null; //此时:e = null, next = null Entry3放入newTable[3]的位置,且Entry3.next = Entry2,结束while循环。
整体情况如下:(链表出现了环形)

此时,问题还没有直接产生。当调用Get查找一个不存在的Key,而这个Key的Hash结果恰好等于3的时候,由于位置3带有环形链表,所以程序将会进入死循环!
总结:
1.Hashmap在插入元素过多的时候需要进行Resize,Resize的条件是
HashMap.Size >= Capacity * LoadFactor。
2.Hashmap的Resize包含扩容和ReHash两个步骤,ReHash在并发的情况下可能会形成链表环。
来自公众号:
