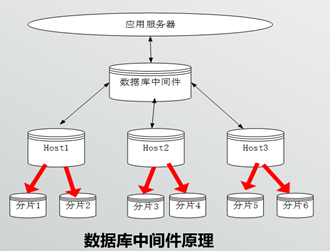
解决方案:使用分布式数据库,引入中间件实现负载均衡,我们先把操作发给这个中间件管家,然后管家通过识别,哦~原来你要进行select操作,那么我就把你这个请求发给master,又来一个原来你需要进行的是插入insert的操作,那么我就把你这个请求发给slave,当如果有多个slave的时候,我就通过slave的权重,轮循的发给每一个slave,这样我们就实现了读写分离操作,以及简单的负载均衡。
数据库的读写分离
实现原理:读写分离简单的说是把对数据库读和写的操作分开对应不同的数据库服务器,这样能有效地减轻数据库压力,也能减轻io压力。主数据库提供写操作,从数据库提供读操作,其实在很多系统中,主要是读的操作。当主数据库进行写操作时,数据要同步到从的数据库,这样才能有效保证数据库完整性。
什么是读写分离:
在数据库集群架构中,让主库负责写,而从库只负责处理读,让两者分工明确达到提高数据库整体读写性能。当然,主数据库另外一个功能就是负责将事务性查询导致的数据变更同步到从库中,也就是写操作。
读写分离的好处
1)分摊服务器压力,提高机器的系统处理效率
读写分离适用于读远比写的场景,如果有一台服务器,当select很多时,update和delete会被这些select访问中的数据堵塞,等待select结束,并发性能并不高,而主从只负责各自的写和读,极大程度的缓解X锁和S锁争用;
假如我们有1主3从,不考虑上述1中提到的从库单方面设置,假设现在1分钟内有10条写入,150条读取。那么,1主3从相当于共计40条写入,而读取总数没变,因此平均下来每台服务器承担了10条写入和50条读取(主库不承担读取操作)。因此,虽然写入没变,但是读取大大分摊了,提高了系统性能。另外,当读取被分摊后,又间接提高了写入的性能。所以,总体性能提高了,说白了就是拿机器和带宽换性能;
2)增加冗余,提高服务可用性,当一台数据库服务器宕机后可以调整另外一台从库以最快速度恢复服务