K-means是一种无监督式的聚类算法,KNN是一种有监督式的分类算法;
两者总结如下:
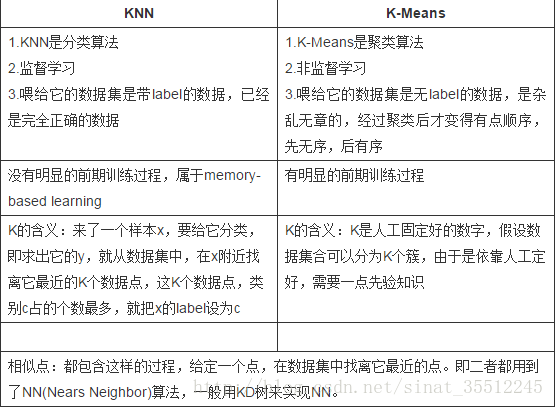
聚类算法是一种无监督学习算法。k均值算法是其中应用最为广泛的一种,算法接受一个未标记的数据集,然后将数据聚类成不同的组。K均值是一个迭代算法,假设我们想要将数据聚类成K个组,其方法为:
- 随机选择K个随机的点(称为聚类中心);
- 对与数据集中的每个数据点,按照距离K个中心点的距离,将其与距离最近的中心点关联起来,与同一中心点关联的所有点聚成一类;
- 计算每一组的均值,将该组所关联的中心点移动到平均值的位置;
- 重复执行2-3步,直至中心点不再变化
K-means优点: 算法简单易实现; - 缺点: 需要用户事先指定类簇个数; 聚类结果对初始类簇中心的选取较为敏感; 容易陷入局部最优; 只能发现球形类簇;