最早由RGB在论文《Training Region-based Object Detectors with Online Hard Example Mining》中提出,用于fast-rcnn训练中,具有一定训练效果;
论文地址:https://arxiv.org/pdf/1604.03540.pdf
实验地址:https://github.com/firrice/OHEM
主要思想:一个batch的输入经过网络的前向传播后,有一些困难样本loss较大,我们可以对loss进行降序排序,取前K个认为是hard example,然后有两种方案:
(1)第一种比较简单,最终loss只取前K个,其他置0,然后进行BP:
一个例子如下:
def ohem_loss(output , label, loss_class , K_hard): batch_size = output.size()[0] loss = loss_class(output , label) sorted_loss , index = torch.sort(loss , descending = True) if(K_hard < batch_size): hard_index = index[ : K_hard] final_loss = loss[hard_index].sum() / K_hard else: final_loss = loss.sum() / batch_size return final_loss
第一种的缺点是虽然置0,但BP中依然会为之分配内存,为了提升效率引入下面第二种方案。
(2)第二种方案,以fast-rcnn的pipeline为例,训练两个ROI net的副本,权值共享,如下:
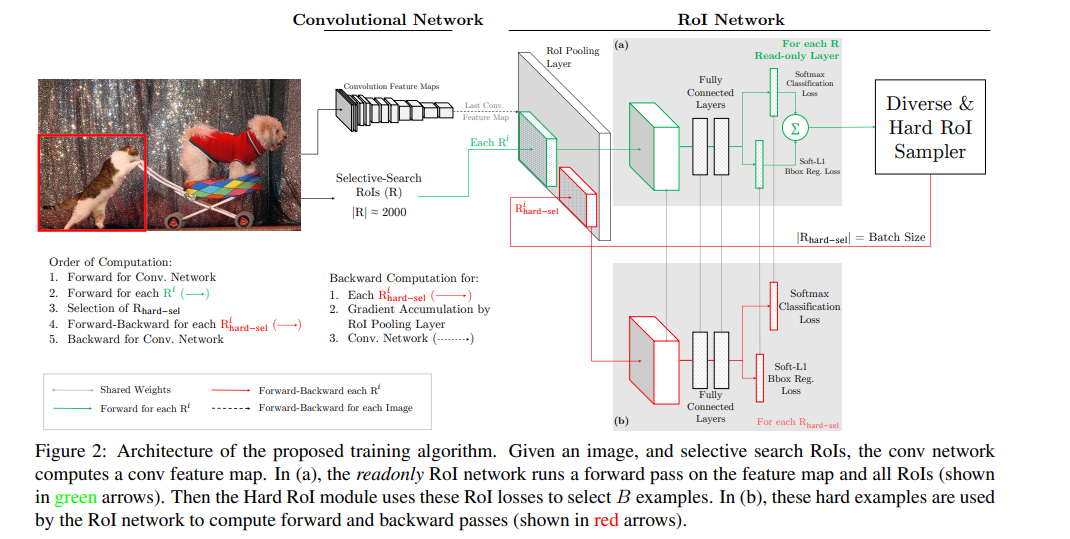
具体来说:
1 将Fast RCNN分成两个components:ConvNet和RoINet. ConvNet为共享的底层卷积层,RoINet为RoI Pooling后的层,包括全连接层;
2 对于每张输入图像,经前向传播,用ConvNet获得feature maps(这里为RoI Pooling层的输入);
3 将事先计算好的proposals,经RoI Pooling层投影到feature maps上,获取固定的特征输出作为全连接层的输入;
需要注意的是,论文说,为了减少显存以及后向传播的时间,这里的RoINet是有两个的,它们共享权重,
RoINet1是只读(只进行forward),RoINet2进行forward和backward:
a 将原图的所有props扔到RoINet1,计算它们的loss(这里有两个loss:cls和det);
b 根据loss从高到低排序,以及利用NMS,来选出前K个props(K由论文里的N和B参数决定)
为什么要用NMS? 显然对于那些高度overlap的props经RoI的投影后,
其在feature maps上的位置和大小是差不多一样的,容易导致loss double counting问题
c 将选出的K个props(可以理解成hard examples)扔到RoINet2,
这时的RoINet2和Fast RCNN的RoINet一样,计算K个props的loss,并回传梯度/残差给ConvNet,来更新整个网络