这两天看了Lenet的模型理解,很简单的手写数字CNN网络,90年代美国用它来识别钞票,准确率还是很高的,所以它也是一个很经典的模型。而且学习这个模型也有助于我们理解更大的网络比如Imagenet等等。
我这里主要是对网络配置文件做了相关注释,没时间解释了,上车:http://pan.baidu.com/s/1jH4HbCy ,密码:5gkn
参考博客:http://blog.csdn.net/bea_tree/article/details/51601197
现在来大致说一下Lenet的结构,如下:
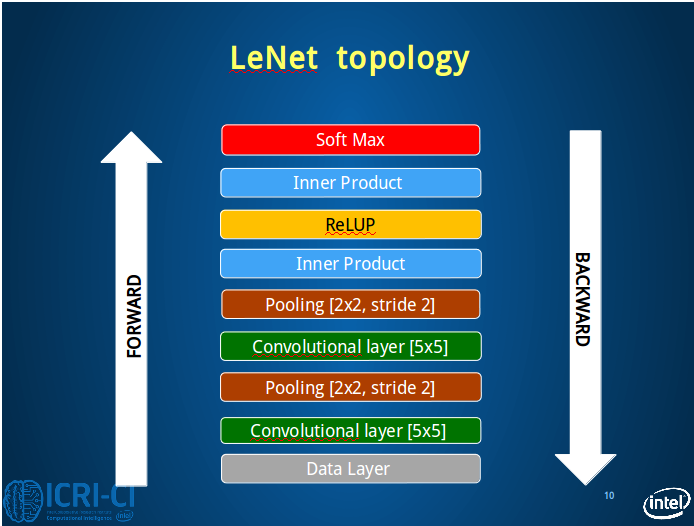

如上,一层数据层,两层卷积层和两层池化层(又称下采样层),再过两个全连接层和两个非线性层(Relu激活函数),最后输出Loss和accuracy;
(注意这里的数据层又分为两层,一层在训练阶段有效,它计算出train_loss来调整参数;一层在测试阶段有效,它经过一次前向传播,得到test_loss和accuracy,并进行比较,防止过拟合;同时要注意这两种数据是同时参与CNN计算的,也就是一边训练一边测试)
关于网络配置文件里还有几个地方我要说一下:
(1)solver.prototxt中的momemtum(冲量):


加上动量项就像从山顶滚下一个球,求往下滚的时候累积了前面的动量(动量不断增加),因此速度变得越来越快,直到到达终点。同理,在更新模型参数时,对于那些当前的梯度方向与上一次梯度方向相同的参数,那么进行加强,即这些方向上更快了;对于那些当前的梯度方向与上一次梯度方向不同的参数,那么进行削减,即这些方向上减慢了。因此可以获得更快的收敛速度与减少振荡。
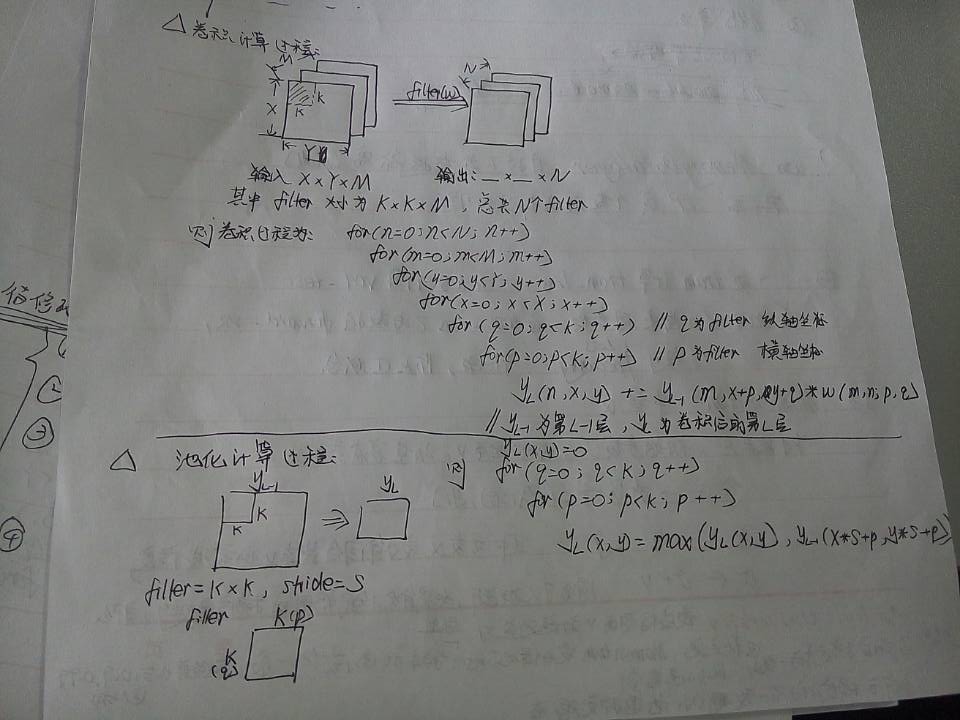
(2)卷积计算过程和池化计算过程:
(3)decay_mult:权衰量

关于梯度下降的优化参考这个博客:http://blog.csdn.net/heyongluoyao8/article/details/52478715