DOM(Document Object Model)——文档对象模型
什么是DOM?
Document Object Model (DOM)是HTML和XML文档的编程接口。它提供了上述文档的一种结构化表示,同时也定义了一种通过程序来改变文档结构,风格,以及内容的方式。DOM用一组结构化的节点以及对象来表示文档。本质上就是将网页和脚本语言以及编程语言连接起来。
一个网页是一个文档。这个文档可以被显示在浏览器窗口中,也可以以html源码的形式显示。这两中情况中,文档都是同一个。DOM提供了另一种方式来表示,存储,操作这个文档。DOM是网页的一种完全的面向对象的表示方法,可以通过脚本语言(比如说JavaScript)来改变。
W3C DOM标准形成了当今大多数浏览器的DOM基础。许多浏览器提供超出W3C标准的扩展,所以当用在可能被拥有不同DOM的各种浏览器使用的场合时 一定要多加注意
DOM标准主要要为:微软DOM与W3C DOM,一般IE实现的是微软DOM,而其它浏览器则不同程度的实际了W3C DOM
DOM发展史
- DOM Level Zero ,事实上从来不存在DOM 0版本,只是人们的戏称。只是在W3C DOM出现之前,不同浏览器(主要是IE与NN)实现的DOM相互排斥,1996年的浏览器大战所产生的DHTML就是所谓的DOM 0,它是脚本程序员的恶梦
- DOM Level 1 包括DOM Core和DOM HTML。前者提供了基于XML的文档结构图。后者添加了一些HTML专用的对象和方法,从而扩展了DOM Core.目前IE在内的大部分桌面浏览器都通过不同方式实现了DOM 1
- DOM Level 2 引入几个新模块:DOM视图,事件,样式,遍历和范围。IE只实现了一部分,火狐浏览器几乎全部实现,除IE之外的浏览器也实现了大部分
- DOM Level 3 引入了以统一的方式载入和保存文档的方法。DOM Core被扩展支持所有的XML1.0的特性。火狐浏览器之类实现了少部分
在开始阶段,JavaScript和DOM是紧密的联系在一起的,但是最终他们将发展为独立的实体。网页的内容存储在DOM中并且可以被JavaScript访问和处理,所以我们可以得到写下这个近似的等式:
API(网页或者XML页面)=DOM + JS(脚本语言)
DOM被设计为独立于任何特定的编程语言,通过协调一致的API以确保这种文档的结构化表现形式是有效的。虽然DOM的实现可以建立在任何语言上,但是在这里我们专注于JavaScript上的DOM实现!
尽管DOM很大程度上受到浏览器中动态HTML发展的影响,但W3C还是将它最先应用于XML。
DOM与BOM的关系
DOM与BOM的关系?——BOM包含DOM
DOM与BOM结构视图
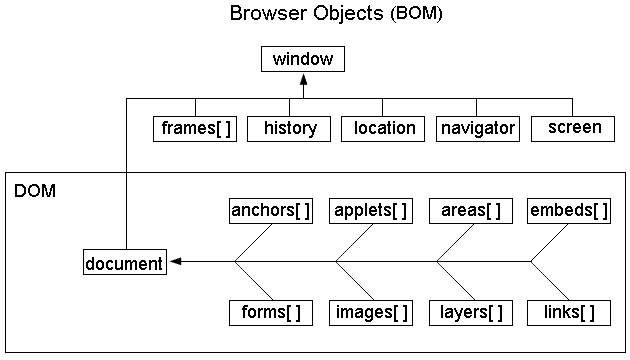
DOM Core
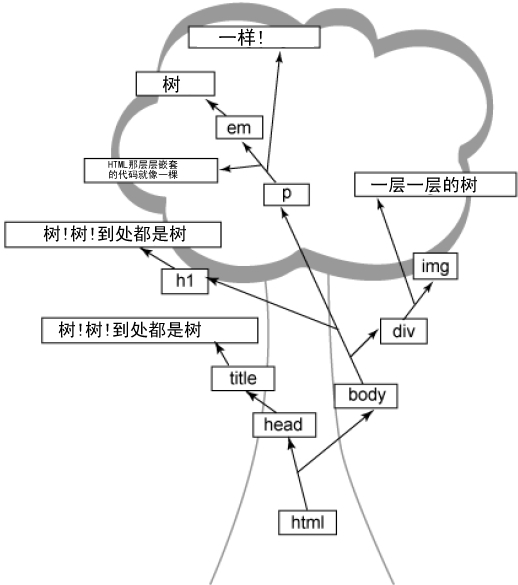
文档对象模型-DOM,就是使用树视图来形容HTML代码,看下面的一张HTML页面的源代码
<html> <head> <title>树!树!到处都是树!</title> </head> <body> <h1>树!树!到处都是树!</h1> <p>HTML那层层嵌套的代码就像一棵<em>树</em>一样!</p> <div>一层一层的树<img src="../images/stach_heap.gif" /> </div> </body> </html>
浏览器接受该页面并将之转换为树形结构
获取元素常用方法
document对象是BOM的一部分,同时也是HTML DOM的HTMLDocument对象的一种表现形式,反过来说,它也是XML DOM Document对象。JavaScript中的大部分处理DOM的过程都利用document对象,所以我们访问文档需要使用BOM提供的这个入口。
var d = document; alert(d);//这仅仅表明document这个对象是存在的
document对象有三个强大的方法,可以获取页面的任何元素
var p1 = document.getElementById("p1");//获取ID为p1的那个元素 //在一个文档中ID必须是唯一的,getElementById方法只会返回一个元素 alert(p1.tagName); var allP = document.getElementsByTagName("p");//获取文档中所有p标签 //因为页面中标签相同的元素很多,所以即使页面中只有一个p元素,getElementsByTagName也会返回一个集合 for (var i=0;i < allP.length;i++) { alert(allP[i].innerHTML);//像数组一样访问其中的每个元素 } //getElementsByTagName还可以使用通配符*来获取所有的元素 var allTags = document.getElementsByTagName("*"); alert(allTags.length); //更强大的是,getElementsByTagName不但可以在document对象上调用,也可以在其它HTML元素上调用 var p2 = document.getElementById("p2"); var p2ps = p2.getElementsByTagName("em");//将获取p2下面的em元素,而不获取p2之外的em //还有一个通过name来获取元素的方法:getElementsByName var radios = document.getElementsByName("check");//获取所有name为check的元素
由于name可以重复,getElementsByName方法始终返回一个集合,不管页面中name是否是唯一的。 IE 6.0和Opera 7.5在这个方法的使用上还存在一些错误。首先,它们还会返回id等于给定名称的元素。第二,它们仅仅检查<input/>和<img/>元素。
获取和设置元素属性——getAttribute与setAttribute方法
var p1 = document.getElementById("p1"); alert(p1.getAttribute("id")); p1.setAttribute("title","Value");
节点基础
文档根节点
var de = document.documentElement; alert(de.tagName);
由于IE 5.5中的DOM实现的错误,document.documentElement会返回<body/>元素。IE 6.0已经修复了这个错误。
获取head与body
//本来可以使用getElementsByTagName的 var head = document.getElementsByTagName("head")[0]; var body = document.getElementsByTagName("body")[0];
还可以使用节点,在使用节点前,先了解一些节点基础知识
常用节点类型
- 元素节点——文档中具有标签的节点
- 文本节点——标签中不是注释的文本块
常用的节点属性
- nodeType——节点类型,元素节点是1,文本节点是3
- nodeValue——节点值,元素节点为空,文本节点的nodeValue属性即为文本内容
- firstChild——该元素节点包含的第一个子节点
- lastChild——该元素节点包含的最后一个子节点
- nextSibling——该节点的后一个兄弟节点
- previousSibling——该节点的前一个兄弟节点
- childNodes——子节点列表,可以通过node.childNodes[index](或node.childNodes.item(index))来获取子节点
- nodeName——节点名称,对于元素节点,返回tagName,对于文本,则返回#text
考虑下面的HTML代码所表示的节点结构
<p> Some Text </p>
上面的HTML代码将会解析成两个节点:元素节点——p标签,文本节点——Some Text.也就是说,标签中包含的一些文本也是节点,那么空格之类的非打印字符会不会被当作文本节点呢?
不同浏览器在判断何为Text节点上存在一些差异。某些浏览器,如Mozilla,认为元素之间的空白(包括换行符)都是Text节点;而另一些浏览器,如IE,会全部忽略这些空白!!
var de = document.documentElement; var head = de.firstChild;//html下面第一个元素,可能是head var body = de.lastChild;//html下面最后一个元素,可能是body
答案并不确定,但是仍然有办法解决——使用节点类型检测,每个节点都有nodeType属性,指明它的节点类型。对于元素节点,它的值是1,而对于文本节点,它的值是3
var de = document.documentElement; var head = de.firstChild.nodeType==1?de.firstChild:de.firstChild.nextSibling; var body = de.lastChild.nodeType==1?de.lastChild:de.lastChild.previousSibling;] //还可以使用childNodes var de = document.documentElement; var head = de.childNodes[0].nodeType==1?de.childNodes[0]:de.childNodes[0].nextSibling; var head = de.childNodes[1].nodeType==1?de.childNodes[1]:de.childNodes[1].previousSibling;
HTML DOM
HTML DOM用对象来表示HTML标签,考虑下面的代码——
<img src="../images/stack_heap.jpg" alt="内存堆栈" onclick="alert('Hello!')" /> //对于上面的img标签,浏览器解析时会将其转换成下面的对象 { src:"../images/stack_heap.jpg", alt:"内存堆栈", onclick:"alert('Hello!')", tagName:"IMG" }; //其实不止这些属性
一般所说的DOM是指XML DOM,而W3C也为HTML页面提供了更快捷的DOM——HTML DOM!使用HTML DOM,能使访问HTML标签的属性就像访问JavaScript创建的对象的属性一样简单.
var imgObj = document.getElementById("imgObj"); alert(imgObj.src);//获取src属性如此简单
使用HTML DOM也使得访问页面一些元素变得更加简单
var bodyTag = document.documentElement.lastChild;//DOM标准方式 bodyTag = document.body;//HTML DOM方式 var titleTag = document.getElementsByTagName("title")[0].firstChild.nodeValue;//DOM标准方式 titleTag = document.title;//HTML DOM方式 //HTML DOM不仅仅可以用来获取内容,也可以设置 document.title ="Change The Title!!!";