Hello World
package main
import "fmt"
func main() {
fmt.Println("Hello, World")
}
我相信,大部分从事编程工作的人,写的第一个代码都是Hello World。
这个也成为了一种传统,那么今天,就从这里开始我们的源码共读计划。
看上面的代码中,最核心的一部分就是调用了 fmt package的Println这个方法。
我们先简单的看一下fmt大概能做什么
fmt 包概述
官方用两句很简单的话介绍了这个包是做什么的,fmt包的主要作用就是格式化I/O的输入和输出。并且还特别指出跟C语言中的printf和scanf很像。
这就清晰了,我们可以用来做什么,一个是输出,一个是输入。
整个fmt包一共有19个function。
func Errorf(format string, a ...interface{}) error
func Fprint(w io.Writer, a ...interface{}) (n int, err error)
func Fprintf(w io.Writer, format string, a ...interface{}) (n int, err error)
func Fprintln(w io.Writer, a ...interface{}) (n int, err error)
func Fscan(r io.Reader, a ...interface{}) (n int, err error)
func Fscanf(r io.Reader, format string, a ...interface{}) (n int, err error)
func Fscanln(r io.Reader, a ...interface{}) (n int, err error)
func Print(a ...interface{}) (n int, err error)
func Printf(format string, a ...interface{}) (n int, err error)
func Println(a ...interface{}) (n int, err error)
func Scan(a ...interface{}) (n int, err error)
func Scanf(format string, a ...interface{}) (n int, err error)
func Scanln(a ...interface{}) (n int, err error)
func Sprint(a ...interface{}) string
func Sprintf(format string, a ...interface{}) string
func Sprintln(a ...interface{}) string
func Sscan(str string, a ...interface{}) (n int, err error)
func Sscanf(str string, format string, a ...interface{}) (n int, err error)
func Sscanln(str string, a ...interface{}) (n int, err error)
除去一个特殊的Errorf。它们主要分为两部分,一个是以输出为主的,所有的方法名中都包含print;另一部分是以输入为主的,全部包含scan。
其中,输出还分两部分。一个是打印到标准输出或指定的io.Writer上,比如:
func Fprint(w io.Writer, a ...interface{}) (n int, err error)
func Printf(format string, a ...interface{}) (n int, err error)
还有一种是直接将传入的interface转换为string后返回给接受者。比如:
func Sprint(a ...interface{}) string
除此之外,还有一些小规律,所有以小写“f”结尾的函数,说明它支持format;所有以“ln”结尾的,说明都是按行输入/输出。
fmt包的使用几乎是每个Go开发者最熟悉的部分了。所以这里就不展开说一些示例了。
下面,我们来看一下整个fmt代码包的结构以及核心的一些实现。
fmt包结构
fmt
├── doc.go
├── errors.go
├── errors_test.go
├── example_test.go
├── export_test.go
├── fmt_test.go
├── format.go
├── gostringer_example_test.go
├── print.go
├── scan.go
├── scan_test.go
├── stringer_example_test.go
└── stringer_test.go
可以看到,除去test和example以及doc文件,整个核心代码就只有4个文件。
format.go
errors.go
print.go
scan.go
那么我们就一起来看一下format.go吧
format.go
fmt 包主要的就是格式化的输入输出,格式化是输入输出的基础。
那么,我们就要先看 format.go 这部分的内容。
这部分源码的主要作用,就是将格式化用的 verbs 全部进行统一。
首先,第一部分就是:
type fmtFlags struct {
.....
}
这个结构体的是将格式化输出用的 verbs 全部格式化到上述的结构体中
然后,紧接着 fmt 的定义 struct , 是 Printf 等格式化输出的基础。
type fmt struct {
......
fmtFlags
......
}
我们可以看到之前提到的 fmtFlags 作为 fmt 的一部分,这是属于 Go 中比较经典的组合。
这里独立出来的主要原因,官方在注释中,主要是为了方便快速的初始化 fmtFlags 。
官方的使用的如下:
func (f *fmt) clearflags() {
f.fmtFlags = fmtFlags{}
}
这个设计比较好,我们可以在自己代码中进行借鉴。
在这之后,就是格式化需要用的三个填充
// writePadding 在 f.buf 后面直接生成 n 个填充字节.
func (f *fmt) writePadding(n int) {
if n <= 0 { // 无需填充
return
}
buf := *f.buf
oldLen := len(buf)
newLen := oldLen + n
// 根据需要填充的字节数以及原来 buf 的长度,给 buf 开辟新的内存空间.
if newLen > cap(buf) {
buf = make(buffer, cap(buf)*2+n)
copy(buf, *f.buf)
}
// 决定 padByte 的字节的内容.
// 默认是空格,如果设置了 f.zero 那就是 0 填充
padByte := byte(' ')
if f.zero {
padByte = byte('0')
}
// 使用 padByte 填充.padding 大小的空间,
padding := buf[oldLen:newLen]
for i := range padding {
padding[i] = padByte
}
*f.buf = buf[:newLen]
}
func (f *fmt) pad(b []byte) { }
func (f *fmt) padString(s string) { }
这三个是相互结合使用的。
后面的两个pad(b []byte)和 padString(s string)都是通过调用writePadding(n int)来实现的。
通过对的抽象,更加方便进行pad操作,如下所示:
func (f *fmt) pad(b []byte) {
......
if !f.minus {
// 在左侧填充
f.writePadding(width)
f.buf.write(b)
} else {
// 右侧填充
f.buf.write(b)
f.writePadding(width)
}
}
要做到格式化输出,最基本的就是将变量以及变量的值打印出来,所以一面就是对基础数据类型的格式化输出。
func (f *fmt) fmtBoolean(v bool)
func (f *fmt) fmtUnicode(u uint64)
func (f *fmt) fmtInteger(u uint64, base int, isSigned bool, verb rune, digits string)
func (f *fmt) fmtFloat(v float64, size int, verb rune, prec int)
主要就这四个,分别是布尔、整型、浮点型以及Unicode。
这几个都是属于比较基础的,这里的布尔的转换只有几行的代码,就不再去提。
对于整型的转换,这里需要注意精度以及进制转换的问题,如下所示:
// fmtInteger 格式化 signed (有符号) 和 unsigned (无符号) 整数.
func (f *fmt) fmtInteger(u uint64, base int, isSigned bool, verb rune, digits string) {
......
prec := 0
if f.precPresent {
prec = f.prec
// 精度为 0 并且值为 0 意味着 “除了填充之外什么也不打印” 。
if prec == 0 && u == 0 {
oldZero := f.zero
f.zero = false
f.writePadding(f.wid)
f.zero = oldZero
return
}
} else if f.zero && f.widPresent {
prec = f.wid
if negative || f.plus || f.space {
prec-- // leave room for sign
}
}
switch base {
case 10:
......
case 16:
......
case 8:
......
case 2:
......
default:
panic("fmt: unknown base; can't happen")
}
......
}
再后面是对 string 和 byte 进行操作的两个方法,主要作用是将 string 或 byte 按照指定的精度进行截断。
// truncateString 按照 f.prec 的精度,将 s 截断为指定的长度.
func (f *fmt) truncateString(s string) string {
......
}
// truncate 将字节切片 b 按照字符串的方式进行截断.
func (f *fmt) truncate(b []byte) []byte {
......
}
剩下部分代码,都是基于上面提到的方法的进一步的封装。
func (f *fmt) fmtS(s string)
func (f *fmt) fmtBs(b []byte)
func (f *fmt) fmtSbx(s string, b []byte, digits string)
func (f *fmt) fmtSx(s, digits string)
func (f *fmt) fmtBx(b []byte, digits string)
func (f *fmt) fmtQ(s string)
func (f *fmt) fmtC(c uint64)
func (f *fmt) fmtQc(c uint64)
format 总结
最后,针对这部分的代码,我们做一个总结。
为更加直观的查看,我专门绘制了一个图。
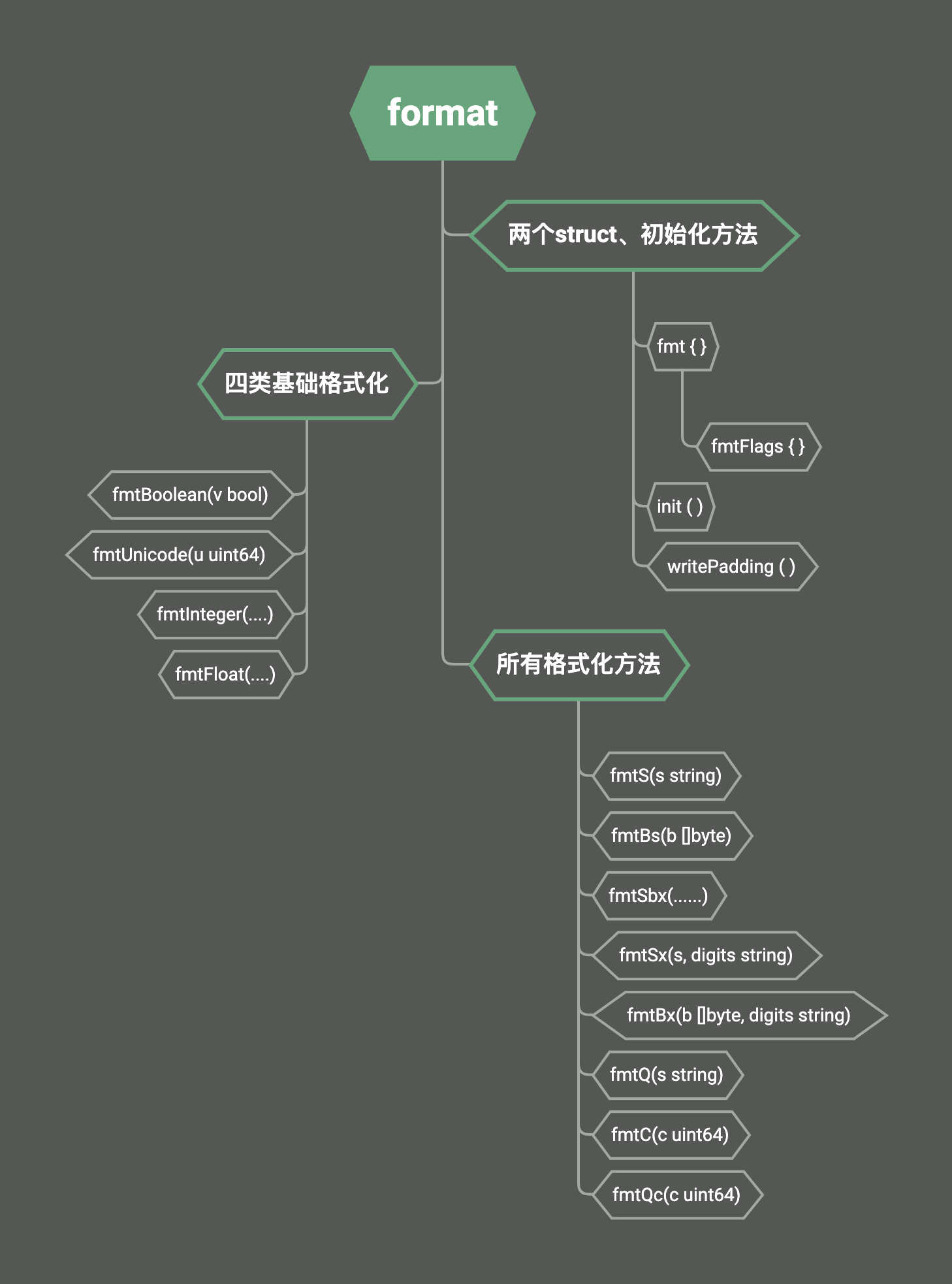
这部分的代码,我在源代码中写有详细的注释。建议在看完文章后,一定要详细的去读一下。
你可以去公众号回复关键字format.go拿到这部分的源码,一共只有600行,一会就能读完。
但是,肯定会有更多的收获。
