Python 其实不是面向对象的语言,更像是C语言的面向过程编程的语言
但 Python 也支持 class 关键字来实现类的声明与创建
但 Python 的对象更像是 JavaScript 的函数
遇到的问题 #1
-- 正确的代码
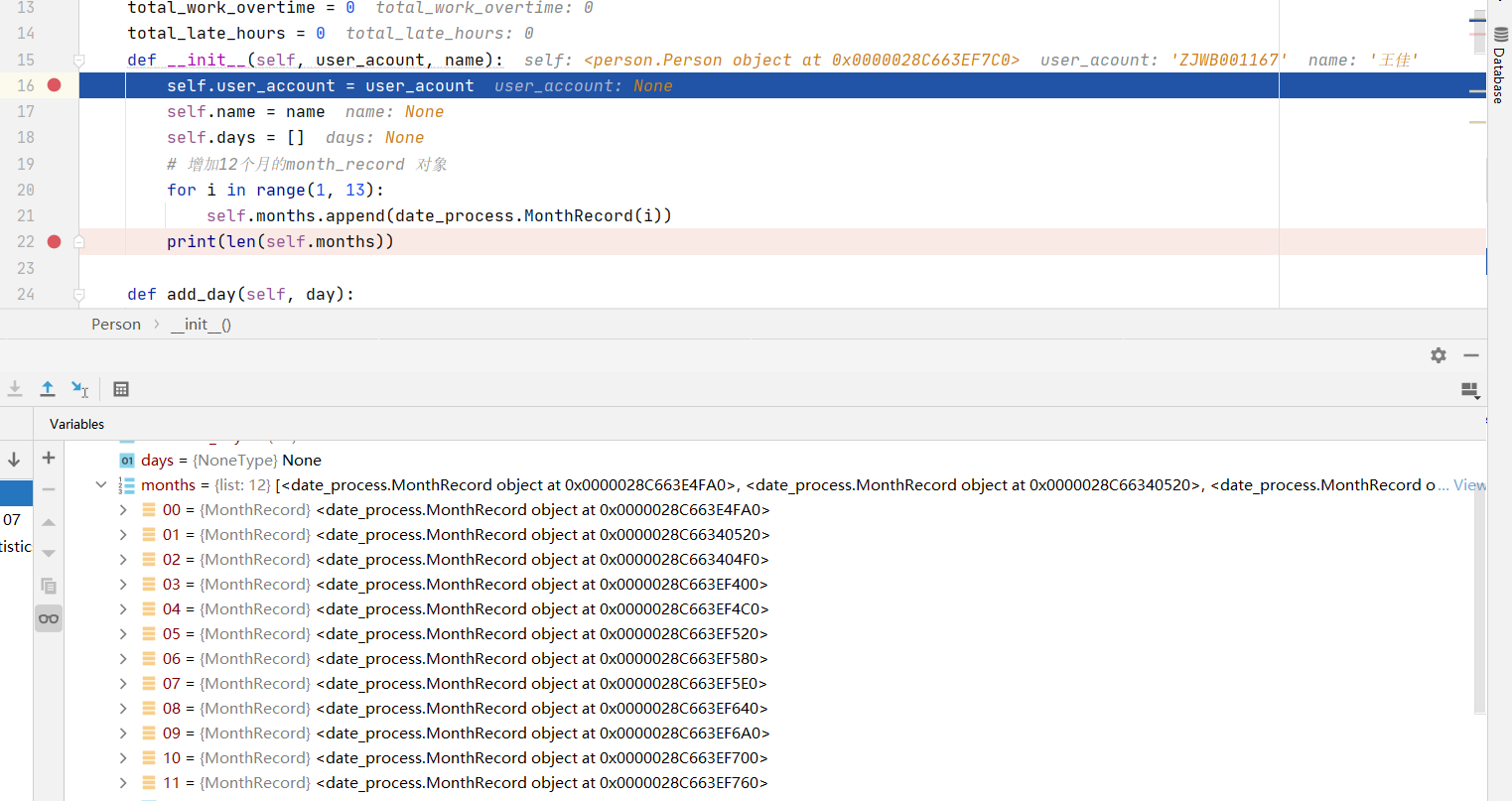
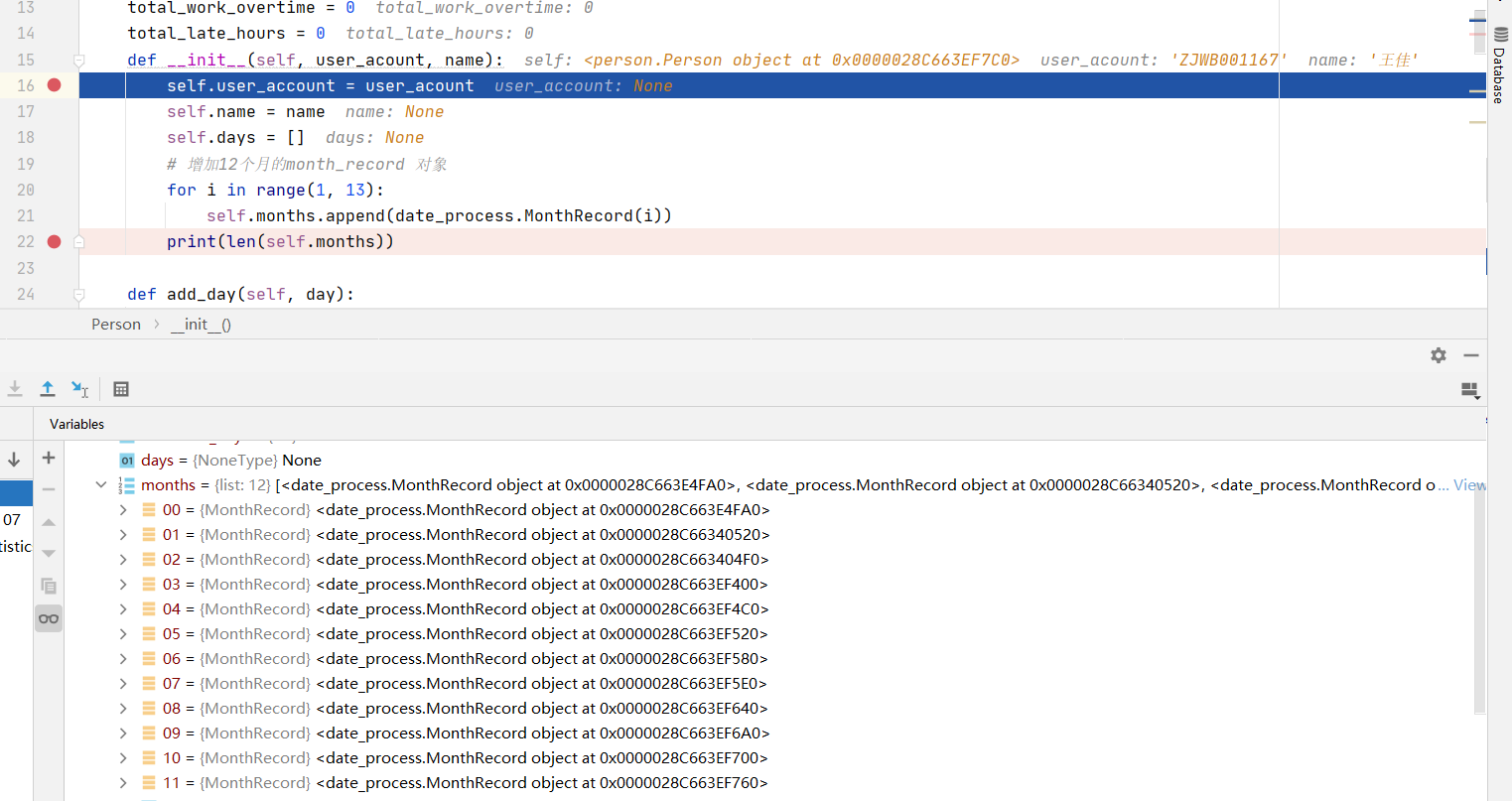
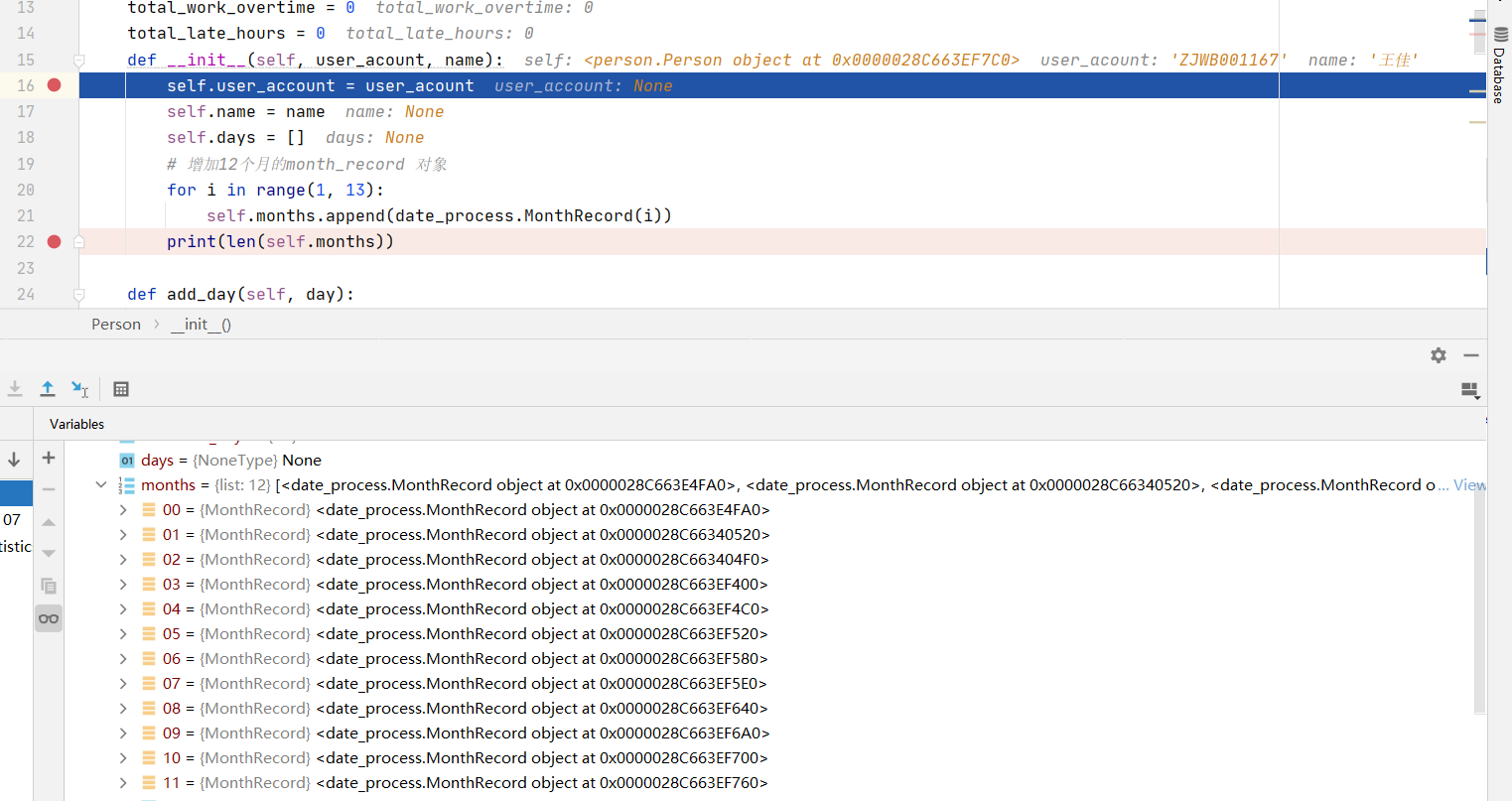
class Person: user_account = None name = None days = None months = None abnormal_days = 0 total_hours = 0 total_work_overtime = 0 total_late_hours = 0 def __init__(self, user_acount, name): self.user_account = user_acount self.name = name self.days = [] self.months = [] # 增加12个月的month_record 对象 for i in range(1, 13): self.months.append(date_process.MonthRecord(i)) print(len(self.months))
-- 错误的代码
class Person: user_account = None name = None days = None months = [] abnormal_days = 0 total_hours = 0 total_work_overtime = 0 total_late_hours = 0 def __init__(self, user_acount, name): self.user_account = user_acount self.name = name self.days = [] # 增加12个月的month_record 对象 for i in range(1, 13): self.months.append(date_process.MonthRecord(i)) print(len(self.months))
这两段代码的查询在于 months 变量,在正确的代码里,成员变量的定义里写成了 months = None, months = [ ] 写在了 __init__() 函数里面, 而在错误的代码里写成了 months = [ ]。错误的代码产生的影响是什么呢?
-----------
当你创建一个新的 Person 对象 first_person 时候,在开始执行 __init__() 函数的时候(即是运行到
self.user_account = user_acount
这一步的时候),months 的对象是 [ ]
当你创建第二个 Person 对象 secong_person 的时候,第二次执行 __init__() 函数的时候,months 的对象是 first_person.month(),其引用的其实同一块内存区域的值。
这个地方非常的反直觉,造成的后果也非常大,我为了排查这个错误也花了很久的时间。
--------- 一点猜测
只是猜测而已,没有进行过详细的验证
pyhthon 的 class 其实只是一个类似JS的函数对象,这个函数有自己的内存空间,但是实际上类就像一个函数,每一次引用的的时候都是调取的同一块内存区域,所以,Python写类的时候,成员变量的初始化请务必写到 __init__()函数里
---------- 验证图片
first_person:
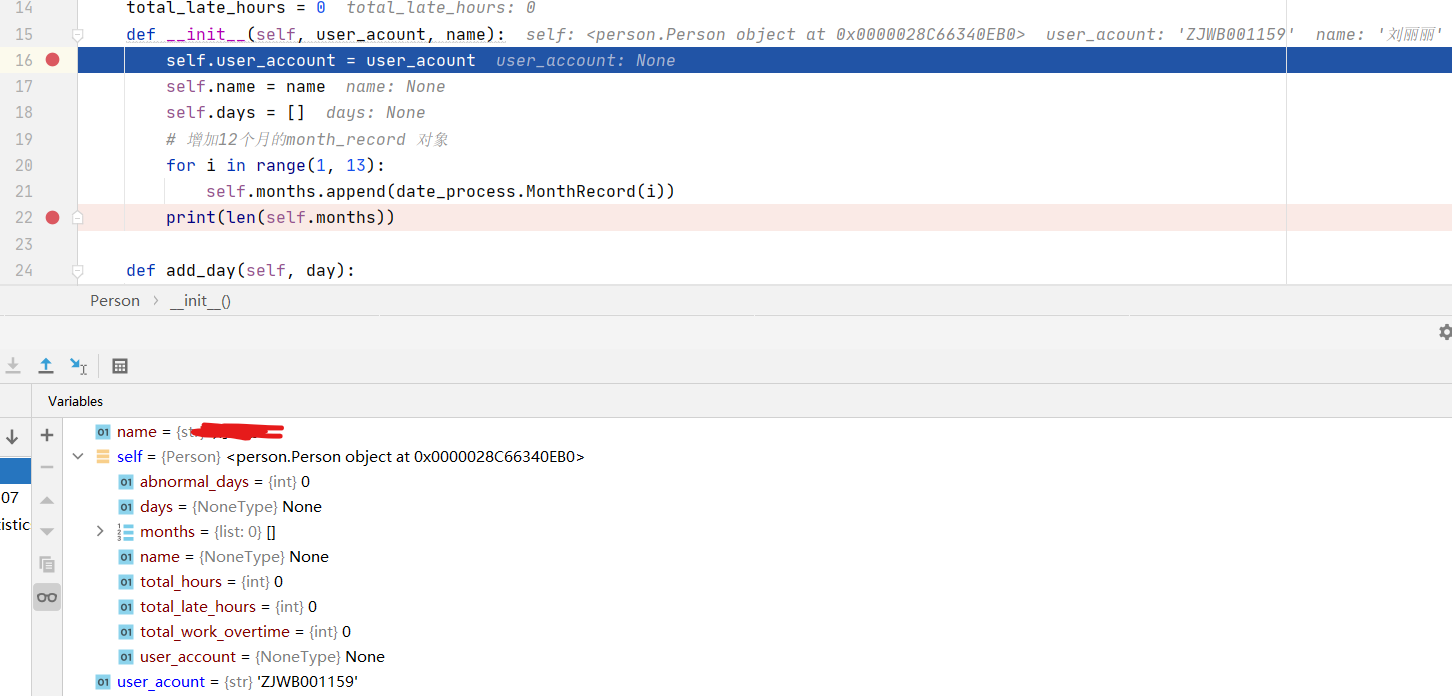
second_person: