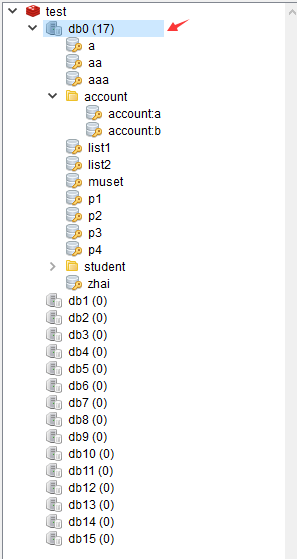
1、redis的多数据库
(1)redis默认有16个数据库
redis数据库是由一个整数索引表示而不是数据库的名称,默认情况下,一个数据库连接到数据库零
(2)数据库的切换
先切换到数据库1,然后存储一个字符串类型的数据:
127.0.0.1:6379> keys * 1) "account:b" 2) "p3" 3) "aa" 4) "p2" 5) "muset" 6) "student:4" 7) "p1" 8) "list1" 9) "a" 10) "p4" 11) "account:a" 12) "list2" 13) "zhai" 14) "student:2" 15) "aaa" 16) "student:3" 17) "student:1" 127.0.0.1:6379> select 1 OK 127.0.0.1:6379[1]> keys * (empty list or set) 127.0.0.1:6379[1]> set zhai 1997 OK 127.0.0.1:6379[1]> get zhai "1997" 127.0.0.1:6379[1]>
查看数据库1: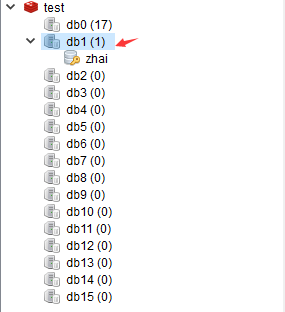
(3)移动数据库
将数据库1中的数据移动到数据库15:
127.0.0.1:6379[1]> move zhai 15 (integer) 1
查看数据库: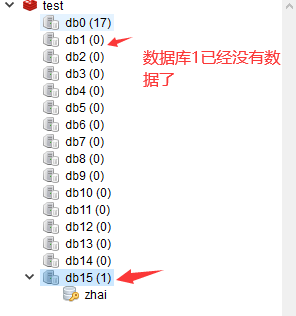
(4)清空当前数据库
先切换到数据库15:

127.0.0.1:6379[1]> select 15 OK 127.0.0.1:6379[15]>
清空当前数据库(数据库15):
127.0.0.1:6379[15]> flushdb OK 127.0.0.1:6379[15]> keys * (empty list or set) 127.0.0.1:6379[15]>
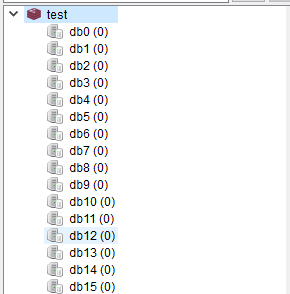
(5)清空所有数据库:
127.0.0.1:6379[15]> flushall OK 127.0.0.1:6379[15]>
2、redis缓存与数据库的一致性
(1)实时同步
适合于对强一致性要求比较高的,即查询缓存的时候没有查到就从数据库中查询,并保存到缓存;更新缓存的时候先更新数据库,再将缓存设置为过期
缺点:由于更新数据的时候,先更新的是数据库就造成缓存不起作用,高并发的情况下就不能解决问题了
(2)异步队列
适合于并发程度较高的情况,可以采用kafka等消息中间件处理消息生产和消费,先将消息放到中间件中
不是数据改变后就立即更新数据库,而是等到数据库空闲的时候再进行数据库的更新操作,减小数据库的压力
好处:
流量的削峰(将消息先放到中间件)
(3)使用阿里云的canal同步工具
(4)采用UDF自定义函数的方式
3、缓存穿透
(1)概念
查询一个不存在的数据,由于缓存不命中的时候需要从数据库中查询,查不到数据就不写入缓存,这样就会导致这个不存在的数据每次请求的时候都要从数据库中查询,造成缓存穿透
(2)解决方案
持久层查询不到数据就缓存空结果,查询的时候先判断缓存中是否存在key,有的话返回空,没有的话则查询数据库后返回数据并写入redis
4、缓存雪崩
(1)概念
缓存大量失效的时候,引发大量的数据库的查询
(2)解决方案
- 用锁/分布式锁或者队列进行串行访问
- 缓存失效时间均匀分布
5、热点key
(1)概念
某一个key访问非常频繁,当key失效的时候会有大量的线程来构建缓存,导致负载增加、系统崩溃
(2)解决方案
使用锁,单机:synchronized、lock等;分布式用分布式锁
不设置缓存过期时间,而是设置在key对应的value里面,如果检测到存的时间超过过期时间则异步更新缓存
在value设置一个比过期时间t0小的过期时间t1,当t1过期的时候,延长t1并做更新缓存的操作
设置标签缓存,标签缓存设置过期时间,标签缓存过期后,需要异步地更新实际缓存