
设置文件信息包含webinfo和usrinfo、设计接口包括get_webinfo(路径名)和get_userinfo(配置文件路径名)
那么ele_dict = get_webinfo(path)、user_list = get_userinfo(path)
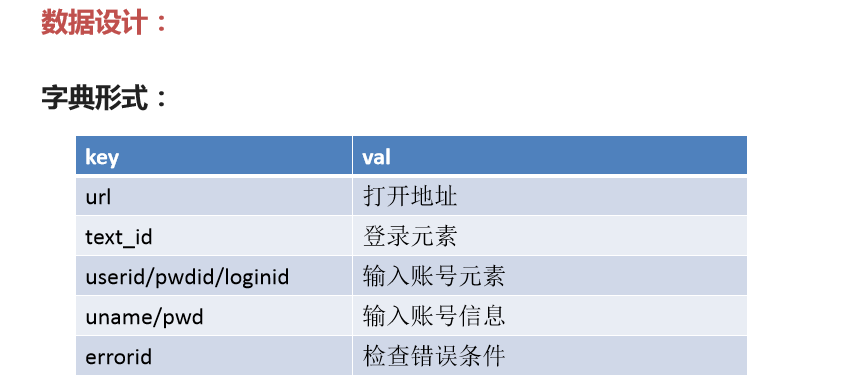
webinfo文件的:
url=https://www.baidu.com/
text_id=登录
userid=TANGRAM__PSP_10__userName
pwdid=TANGRAM__PSP_10__password
loginid=TANGRAM__PSP_10__submit
errorid=用户名或密码错误!
userinfo文件的:
uname=你的百度云账号 pwd=你的百度云密码
usedata文件的:
#导入codecs模块:
import codecs
#定义接口get_webinfo功能:
def get_webinfo(path):
web_info = {}
config = codecs.open(path,"r","utf-8")
# with open(path,"r",encoding="utf-8") as config:
for line in config:
#使用列表解析:
result = [ele.strip() for ele in line.split("=")]
web_info.update(dict([result]))
return web_info
#定义配置文件路径get_userinfo功能:
def get_userinfo(path):
user_info = []
config = codecs.open(path,"r","utf-8")
for line in config:
user_dict = {}
result = [ele.strip() for ele in line.split(" ")]
for r in result:
account = [ele.strip() for ele in r.split("=")]
user_dict.update(dict([account]))
user_info.append(user_dict)
return user_info
if __name__ == '__main__':
info = get_webinfo(r"C:我的代码selenium自动化测试百度云登录webinfo")
for key in info:
print(key,info[key])
userinfo = get_userinfo(r"C:我的代码selenium自动化测试百度云登录userinfo")
for l in userinfo:
print(l)
print(userinfo)
主程序的:
#导入网页模块功能:
from selenium import webdriver
import time
#导入活动模块功能:
from selenium.webdriver.common.action_chains import ActionChains
#导入等待模块功能:
from selenium.webdriver.support.ui import WebDriverWait
#导入usedata模块的get_webinfo功能和get_userinfo功能:
from usedata import get_webinfo,get_userinfo
#定义等待时间功能:
def get_ele_times(driver,times,func):
return WebDriverWait(driver,times).until(func)
#定义打开浏览器的功能并返回句柄:
def openBrower():
webdriver_handle = webdriver.Firefox()
return webdriver_handle #返回句柄
#定义加载URL功能:
def openUrl(handle,url):
handle.get(url)
#定义查找元素功能:
def findElement(d,arg):
"""
:param d: 文件句柄
:param arg: 必须是字典
:return:
"""
# text_id = "登录"
# if text_id in arg:
#生成等待时间并找到text_id是登录的:
get_ele_times(d,1,lambda d:d.find_element_by_link_text("登录")).click()
time.sleep(1)
#找到用户名登录的css路径:
d.find_element_by_css_selector("html body div#passport-login-pop.tang-pass-pop-login-merge.tang-pass-pop-login-tpl-mn."
"tang-pass-pop-login-color-blue.tang-pass-pop-login div#TANGRAM__PSP_4__foreground.tang-foreground "
"div#TANGRAM__PSP_4__body.tang-body div#TANGRAM__PSP_4__content.tang-content "
"div#passport-login-pop-dialog div.clearfix div.pass-login-pop-content "
"div.pass-login-pop-form div.tang-pass-footerBar p#TANGRAM__PSP_10__footerULoginBtn."
"tang-pass-footerBarULogin.pass-link").click()
time.sleep(1)
useEle = d.find_element_by_id(arg["userid"])
pwdEle = d.find_element_by_id(arg["pwdid"])
loginEle = d.find_element_by_id(arg["loginid"])
return useEle,pwdEle,loginEle
#定义发送接口函数:
def sendVals(eletuple,arg):
"""
:param eletuple:元组
:param arg: 字典格式:uname、pwd
:return:
"""
listkey = ["uname","pwd"]
i = 0
for key in listkey:
eletuple[i].send_keys("")
eletuple[i].clear()
time.sleep(1)
eletuple[i].send_keys(arg[key])
i += 1
time.sleep(3)
eletuple[2].click()
#定义拖动功能未实现:
# d.find_element_by_css_selector("html body div#vcode-body811.vcode-body div#mod-vcodes811.mod-vcodes div#pass-content811."
# "mod-vcode-content.clearfix div#pass-spin-control811.vcode-spin-control div#vcode-spin-button811."
# "vcode-spin-button p#vcode-spin-button-p811").move_to_element().drag_and_drop().right()
#定义检查结果功能:
def checkResult(d,text):
#设置抛出异常:
try:
d.find_element_by_link_text("用户名或密码错误!")
print("用户名或密码错误!")
except:
print("登录成功!")
#定义登录测试入口功能:
def login_test(ele_dict,user_list):
d = openBrower()
openUrl(d,ele_dict["url"]) #打开URL功能传入句柄和URL
ele_tuple = findElement(d,ele_dict) #运行的结果是元组
for arg in user_list:
sendVals(ele_tuple,arg)
checkResult(d,ele_dict["errorid"])
#定义主函数:
if __name__ == '__main__':
# for i in range(1):
# url = "https://www.baidu.com/"
# login_text = "登录"
# account = "你的百度云账号"
# pwd = "你的百度云密码"
# ele_dict = {"url":url,"text_id": login_text, "userid": "TANGRAM__PSP_10__userName", "pwdid": "TANGRAM__PSP_10__password",
# "loginid": "TANGRAM__PSP_10__submit","uname": account, "pwd": pwd,"errorid":"用户名或密码错误!"}
ele_dict = get_webinfo(r"C:我的代码selenium自动化测试百度云登录webinfo")
user_list = get_userinfo(r"C:我的代码selenium自动化测试百度云登录userinfo")
# user_list = [{"uname":account,"pwd":pwd}]
#设置文件信息包含webinfo和usrinfo、设计接口包括get_webinfo(路径名)和get_userinfo(配置文件路径名)
#ele_dict = get_webinfo(path)、user_list = get_userinfo(path)
login_test(ele_dict,user_list)